





点击蓝字,关注我们
在大数据时代,工作流任务调度系统成为了数据处理和业务流程管理的核心组件,在大数据平台的构建和开发过程中尤为重要。随着数据量的激增和业务需求的多样化,合理的任务调度不仅能够提高资源利用率,还能保证业务流程的稳定和高效运行。本文将结合实际场景,探讨目前市面上常见的工作流任务调度及其关键特性。
01
工作流任务调度的定义
作业计划是指预定的任务执行策略,包括何时执行、依赖关系以及执行条件等。而任务实例则是指在具体时间点上执行的任务。在工作流调度中,任务实例的生成通常基于作业计划,通过对作业的依赖关系进行解析,确保作业按照预期顺序和时间执行。
02
常见的工作流调度系统
市面上常见的工作流调度可以分为两个大类:定时分片类作业调度系统和DAG工作流类作业调度系统。
1. 定时分片类调度系统
任务分片:将大任务拆分为多个小任务,分配到不同的服务器上并发执行。这不仅提高了处理效率,也能实现负载均衡。 精确定时:要求任务在指定时间点精确触发,以确保业务流程的及时性。例如,定时清理日志文件、定时生成报表等。
2. DAG工作流类调度系统
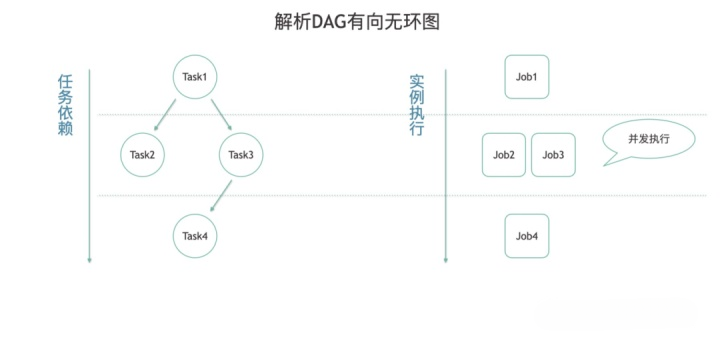
依赖管理:支持复杂的任务依赖关系,确保任务在满足前置条件时自动触发。例如,数据清洗任务在数据采集成功后才能执行。 灵活的触发机制:支持时间触发、依赖触发等多种方式,满足不同业务场景的需求。
03
工作流任务调度的关键特性
1. 任务依赖管理
2. 高可用性
3. 监控与报警
4. 灵活的任务配置
04
工作流任务调度的应用场景
数据处理:在数据采集、清洗和分析过程中,任务调度系统可以确保各个环节有序进行,确保数据的准确性和及时性。 报告生成:定期生成报表的任务可以通过调度系统自动化执行,减少人工干预,提高效率。 监控与维护:定时检查系统状态、清理无用数据等维护任务也可通过调度系统来实现。
05
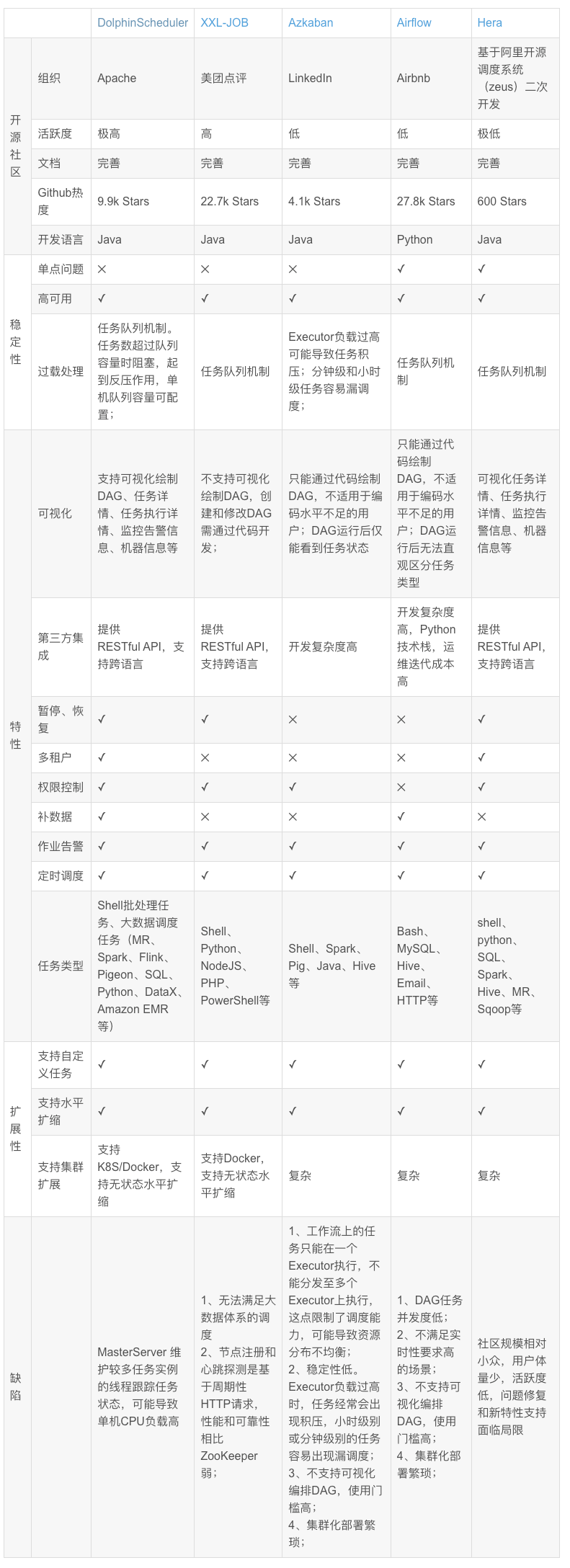
常见的工作流任务调度工具
Apache DolphinScheduler:专注于提供灵活的任务调度和管理,支持复杂的任务依赖关系,能够高效处理大规模数据处理工作流。DolphinScheduler的可视化界面和丰富的插件机制,使得用户可以方便地定义、调度和监控工作流。此外,DolphinScheduler的分布式架构保证了高可用性和扩展性,适合企业在多种场景下的应用,如数据ETL、报表生成和定期任务调度等。 Apache Oozie:基于Hadoop的工作流调度系统,支持复杂的依赖关系和多种作业类型(如MapReduce、Pig、Hive等)。Oozie使用XML定义工作流,适合需要处理大规模数据的环境。
Azkaban:由LinkedIn开发,专注于简化复杂工作流的管理。Azkaban使用.job文件描述作业的依赖关系,提供了用户友好的Web界面。 Chronos:一个分布式的任务调度器,支持Cron语法的定时任务和依赖关系。Chronos更适合对实时性要求较高的任务调度。 Airflow:由Airbnb开发,强调动态工作流的定义和可视化管理,支持Python作为定义语言,适合需要灵活调度的场景。
06
技术选型怎么做?
可扩展性:系统能否随着数据量和任务复杂度的增加而水平扩展。 可靠性:系统的容错能力和高可用性,确保任务执行的稳定性。 性能:任务调度和执行的效率,包括延迟和吞吐量。 易用性:用户界面友好程度、配置和管理的便利性。 集成能力:与现有系统和工具(如数据源、消息队列等)的兼容性和集成能力。 监控与告警:是否提供实时监控、日志记录和告警机制,便于运维管理。 社区与支持:是否有活跃的社区和专业支持,确保问题能够及时解决。 安全性:数据加密、用户权限管理等安全措施的有效性。 成本:总体拥有成本,包括软件许可、基础设施和维护费用。 灵活性:支持多种调度策略、工作流定义和任务类型的能力。
07
结论

我知道你在看哟
文章转载自海豚调度,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
