




本文是由东南大学知识科学与工程实验室、杭州市蚂蚁集团联合发表。该文提出的 MATEval 框架通过模仿人类协作讨论的方式,整合多个代理互动来评估开放式文本。 MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
MATEval: 基于多Agent交互的文本评估框架

1 摘要
2 核心内容
2.1 MATEval: 多Agent文本评估框架
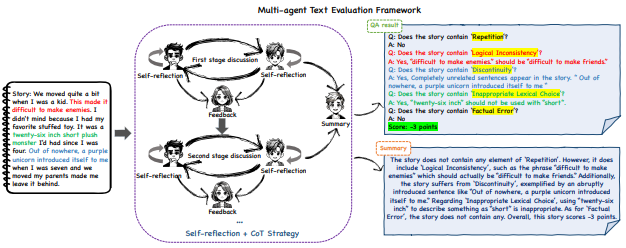
2.2 MATEval: 组成部分
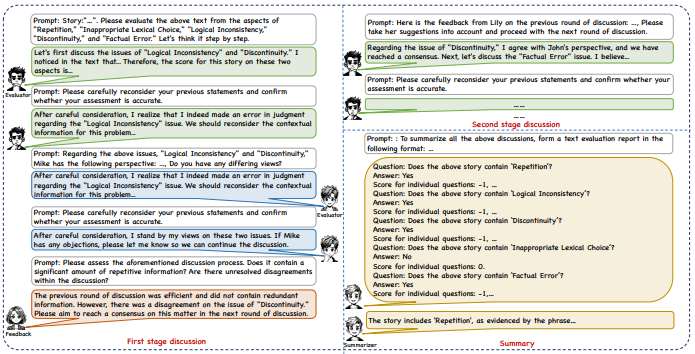
(1)Evaluator Agent
(2)Feedback Agent
(3)Summarizer Agent
(4)Self-reflection
(5)CoT
(6)Feedback Mechanism
(7)Output
3 总结
提出了MATEval框架,它能够提供详尽的诊断报告,提高了 LLM 生成文本评分的准确性和可靠性。该框架不仅加速了工业环境中的模型迭代,还提升了审查效率。
在多智能体框架中创新性地整合了自我反思和CoT方法,并在讨论结束后引入了反馈机制,以解决分歧并促进共识。
在两个英文和两个中文文本数据集上进行了全面实验。实验结果证明了该框架的有效性并且评估结果与人类评估的结果高度一致。

文章转载自AI 搜索引擎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
