




对于许多用户来说,ClickHouse 中存在很多神秘而陌生的功能,这些功能给 ClickHouse 带来了非常高的查询性能。
LowCardinality 数据类型就是 ClickHouse 中的一种特殊的功能,目前可以应用在生产环境中。在本文中,笔者将带领大家一起学习 LowCardinality 的工作原理以及如何使用 LowCardinality。
LowCardinality 实战
LowCardinality 是一种数据类型,或者换句话说,LowCardinality 是数据类型函数。我们可以使用它来修改任何 ClickHouse 数据类型,最常用于 String 数据类型。我们将以 官方提供的 ontime 数据集为例,该表包含 1.72 亿行数据,描述了多年来美国航班信息。
ontime 创建表语句:
CREATE TABLE `ontime` (
`Year` UInt16,
`Quarter` UInt8,
`Month` UInt8,
`DayofMonth` UInt8,
`DayOfWeek` UInt8,
`FlightDate` Date,
`UniqueCarrier` FixedString(7),
`AirlineID` Int32,
`Carrier` FixedString(2),
`TailNum` String,
`FlightNum` String,
`OriginAirportID` Int32,
`OriginAirportSeqID` Int32,
`OriginCityMarketID` Int32,
`Origin` FixedString(5),
`OriginCityName` String,
`OriginState` FixedString(2),
`OriginStateFips` String,
`OriginStateName` String,
`OriginWac` Int32,
`DestAirportID` Int32,
`DestAirportSeqID` Int32,
`DestCityMarketID` Int32,
`Dest` FixedString(5),
`DestCityName` String,
`DestState` FixedString(2),
`DestStateFips` String,
`DestStateName` String,
`DestWac` Int32,
`CRSDepTime` Int32,
`DepTime` Int32,
`DepDelay` Int32,
`DepDelayMinutes` Int32,
`DepDel15` Int32,
`DepartureDelayGroups` String,
`DepTimeBlk` String,
`TaxiOut` Int32,
`WheelsOff` Int32,
`WheelsOn` Int32,
`TaxiIn` Int32,
`CRSArrTime` Int32,
`ArrTime` Int32,
`ArrDelay` Int32,
`ArrDelayMinutes` Int32,
`ArrDel15` Int32,
`ArrivalDelayGroups` Int32,
`ArrTimeBlk` String,
`Cancelled` UInt8,
`CancellationCode` FixedString(1),
`Diverted` UInt8,
`CRSElapsedTime` Int32,
`ActualElapsedTime` Int32,
`AirTime` Int32,
`Flights` Int32,
`Distance` Int32,
`DistanceGroup` UInt8,
`CarrierDelay` Int32,
`WeatherDelay` Int32,
`NASDelay` Int32,
`SecurityDelay` Int32,
`LateAircraftDelay` Int32,
`FirstDepTime` String,
`TotalAddGTime` String,
`LongestAddGTime` String,
`DivAirportLandings` String,
`DivReachedDest` String,
`DivActualElapsedTime` String,
`DivArrDelay` String,
`DivDistance` String,
`Div1Airport` String,
`Div1AirportID` Int32,
`Div1AirportSeqID` Int32,
`Div1WheelsOn` String,
`Div1TotalGTime` String,
`Div1LongestGTime` String,
`Div1WheelsOff` String,
`Div1TailNum` String,
`Div2Airport` String,
`Div2AirportID` Int32,
`Div2AirportSeqID` Int32,
`Div2WheelsOn` String,
`Div2TotalGTime` String,
`Div2LongestGTime` String,
`Div2WheelsOff` String,
`Div2TailNum` String,
`Div3Airport` String,
`Div3AirportID` Int32,
`Div3AirportSeqID` Int32,
`Div3WheelsOn` String,
`Div3TotalGTime` String,
`Div3LongestGTime` String,
`Div3WheelsOff` String,
`Div3TailNum` String,
`Div4Airport` String,
`Div4AirportID` Int32,
`Div4AirportSeqID` Int32,
`Div4WheelsOn` String,
`Div4TotalGTime` String,
`Div4LongestGTime` String,
`Div4WheelsOff` String,
`Div4TailNum` String,
`Div5Airport` String,
`Div5AirportID` Int32,
`Div5AirportSeqID` Int32,
`Div5WheelsOn` String,
`Div5TotalGTime` String,
`Div5LongestGTime` String,
`Div5WheelsOff` String,
`Div5TailNum` String
) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192)
如果要求查询与航班的热门城市相关的统计信息,如下查询:
Query 1:
:) select OriginCityName, count() from ontime group by OriginCityName order by count() desc limit 10;
┌─OriginCityName────────┬──count()─┐
│ Chicago, IL │ 10872578 │
│ Atlanta, GA │ 9279569 │
│ Dallas/Fort Worth, TX │ 7760200 │
│ Houston, TX │ 5898651 │
│ Los Angeles, CA │ 5804789 │
│ New York, NY │ 5283856 │
│ Denver, CO │ 5199842 │
│ Phoenix, AZ │ 4891313 │
│ Washington, DC │ 4252095 │
│ San Francisco, CA │ 4027466 │
└───────────────────────┴──────────┘
10 rows in set. Elapsed: 2.089 sec. Processed 172.34 million rows, 3.82 GB (82.51 million rows/s., 1.83 GB/s.)
再下钻到城市 Chicago 以获取更详细的信息:
Query 2:
:) select OriginCityName, count(), uniq(FlightNum), sum(Distance)
from ontime where OriginCityName = 'Chicago, IL'
group by OriginCityName order by count() desc;
┌─OriginCityName─┬──count()─┬─uniq(FlightNum)─┬─sum(Distance)─┐
│ Chicago, IL │ 10872578 │ 7765 │ 8143093140 │
└────────────────┴──────────┴─────────────────┴───────────────┘
1 rows in set. Elapsed: 2.197 sec. Processed 172.34 million rows, 4.00 GB (78.45 million rows/s., 1.82 GB/s.)
接下来,我们可以使用 LowCardinality 对表结构进行修改。在修改表结构之前,让我们先查看表的列 DestCityName 和 OriginCityName 的元数据信息:
:) SELECT column, any(type),
sum(column_data_compressed_bytes) compressed,
sum(column_data_uncompressed_bytes) uncompressed,
sum(rows)
FROM system.parts_columns
WHERE (table = 'ontime') AND active AND (column LIKE '%CityName')
GROUP BY column
ORDER BY column ASC
┌─column─────────┬─any(type)─┬─compressed─┬─uncompressed─┬─sum(rows)─┐
│ DestCityName │ String │ 421979321 │ 2440948285 │ 172338036 │
│ OriginCityName │ String │ 427003910 │ 2441007783 │ 172338036 │
└────────────────┴───────────┴────────────┴──────────────┴───────────┘
现在,我们将 OriginCityName 列的类型更改为 LowCardinality:
:) ALTER TABLE ontime MODIFY COLUMN OriginCityName LowCardinality(String);
0 rows in set. Elapsed: 19.258 sec.
该 Alter Table 命令是在线执行的,修改完成后,再次查询元数据信息:
┌─column─────────┬─any(type)─┬─compressed─┬─uncompressed─┬─sum(rows)─┐
│ DestCityName │ String │ 421979321 │ 2440948285 │ 172338036 │
│ OriginCityName │ LowCardinality(String) │ 161295620 │ 264243767 │ 172338036 │
└────────────────┴───────────┴────────────┴──────────────┴───────────┘
根据上面的查询结果,我们将 OriginCityName 与 DestCityName 进行比较,会发现 OriginCityName 列的存储(压缩情况下)减少了2.6倍,而未压缩的大小几乎减少了10倍。
那么查询性能如何呢?我们重新执行上面的 Query 1 和 Query 2:
Query 1:
:) select OriginCityName, count() from ontime group by OriginCityName order by count() desc limit 10;
┌─OriginCityName────────┬──count()─┐
│ Chicago, IL │ 10872578 │
│ Atlanta, GA │ 9279569 │
│ Dallas/Fort Worth, TX │ 7760200 │
│ Houston, TX │ 5898651 │
│ Los Angeles, CA │ 5804789 │
│ New York, NY │ 5283856 │
│ Denver, CO │ 5199842 │
│ Phoenix, AZ │ 4891313 │
│ Washington, DC │ 4252095 │
│ San Francisco, CA │ 4027466 │
└───────────────────────┴──────────┘
10 rows in set. Elapsed: 0.595 sec. Processed 172.34 million rows, 281.33 MB (289.75 million rows/s., 472.99 MB/s.)
Query 2:
:) select OriginCityName, count(), uniq(FlightNum), sum(Distance)
from ontime where OriginCityName = 'Chicago, IL'
group by OriginCityName order by count() desc;
┌─OriginCityName─┬──count()─┬─uniq(FlightNum)─┬─sum(Distance)─┐
│ Chicago, IL │ 10872578 │ 7765 │ 8143093140 │
└────────────────┴──────────┴─────────────────┴───────────────┘
1 rows in set. Elapsed: 1.475 sec. Processed 172.34 million rows, 460.89 MB (116.87 million rows/s., 312.54 MB/s.)
Query 1 的性能提高了 3.5 倍,但是它仅仅处理了列 OriginCityColumn。 而第二个查询也得到了改进,只提升了 33%,这是因为修改后的列 OriginCityName 只是用于过滤,其他列仍和之前一样读取和处理。所以我们需要进一步优化,将相同的方法应用于 FlightNum 列。
FlightNum 之前的元数据信息:
┌─column────┬─any(type)──────┬─compressed─┬─uncompressed─┬─sum(rows)─┐
│ FlightNum │ String │ 537637866 │ 773085928 │ 172338036 │
└───────────┴────────────────┴────────────┴──────────────┴───────────┘
FlightNum 修改之后的元数据信息:
┌─column────┬─any(type)──────┬─compressed─┬─uncompressed─┬─sum(rows)─┐
│ FlightNum │ LowCardinality(String) │ 330646531 │ 362920578 │ 172338036 │
└───────────┴────────────────┴────────────┴──────────────┴───────────┘
接着,我们再次查询 Query 2:
:) select OriginCityName, count(), uniq(FlightNum), sum(Distance)
from ontime where OriginCityName = 'Chicago, IL'
group by OriginCityName order by count() desc;
┌─OriginCityName─┬──count()─┬─uniq(FlightNum)─┬─sum(Distance)─┐
│ Chicago, IL │ 10872578 │ 7765 │ 8143093140 │
└────────────────┴──────────┴─────────────────┴───────────────┘
1 rows in set. Elapsed: 1.064 sec. Processed 172.34 million rows, 549.77 MB (161.98 million rows/s., 516.74 MB/s.)
可以直观地看到查询性能又增加了 30%。
总结一下,上面的查询结果,如下表:
String 列 | 1 个 LowCardinality列 | 2 个 LowCardinality 列 | |
|---|---|---|---|
Query 1(sec) | 2.089 | 0.595(x3.5) | |
Query 2(sec) | 2.197 | 1.475(x1.5) | 1.064(x2) |
因此,通过简单快速的更改表的字段数据类型,就可以显着提高查询性能。正如我们上面所提到的,ontime 数据集并不是 LowCardinality 使用的最佳选择,因为 OriginCityName 列的数据长度相对较短,FlightNum 列的数据更短。如果将 LowCardinality 应用在较长的字符串上,带来的性能提升会更加显著。
着手练一把
1. 使用普通数据类型创建表和加载数据
:) CREATE TABLE Dict
(
d2 UInt32,
d1 UInt32,
uint UInt64,
flt Float64,
str String
)
ENGINE = MergeTree()
PARTITION BY d2
ORDER BY (d2, d1)
:) INSERT INTO Dict SELECT
intDiv(number, 100000) AS d2,
number AS d1,
(rand64() % 7000 +1)*10000 AS uint,
uint * pi() as flt,
['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten'][rand()%10+1] AS str
FROM numbers(10000000);
Ok.
0 rows in set. Elapsed: 2.097 sec. Processed 10.03 million rows, 80.22 MB (4.78 million rows/s., 38.26 MB/s.)
:) OPTIMIZE TABLE Dict FINAL
0 rows in set. Elapsed: 1.312 sec.
2. 使用 LowCardinality 数据类型创建表和加载数据
:) CREATE TABLE LCDict
(
d2 UInt32,
d1 UInt32,
uintlc LowCardinality(UInt64),
fltlc LowCardinality(Float64),
strlc LowCardinality(String)
)
ENGINE = MergeTree()
PARTITION BY d2
ORDER BY (d2, d1);
:) INSERT INTO LCDict SELECT
intDiv(number, 100000) AS d2,
number AS d1,
(rand64() % 7000 +1)*10000 AS uint,
uint * pi() as flt,
['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten'][rand()%10+1] AS str
FROM numbers(10000000);
Ok.
0 rows in set. Elapsed: 3.291 sec. Processed 10.03 million rows, 80.22 MB (3.05 million rows/s., 24.38 MB/s.)
:) OPTIMIZE TABLE LCDict FINAL
0 rows in set. Elapsed: 1.483 sec.
如果创建表时提示如下错误:
DB::Exception: Creating columns of type LowCardinality(UInt64) is prohibited by default due to expected negative impact on performance. It can be enabled with the "allow_suspicious_low_cardinality_types" setting..
可以设置如下参数:
set allow_suspicious_low_cardinality_types = 1;
通过插入数据可以发现,LowCardinality 数据类型的表,插入数据比较耗时。
3. 查看新创建的两张表元数据
:) SELECT
table,
sum(bytes) / 1048576 AS size,
sum(rows) AS rows
FROM system.parts
WHERE active AND (database = 'default') AND (table LIKE '%Dict')
GROUP BY table
ORDER BY size DESC;
┌─table──┬──────────────size─┬─────rows─┐
│ Dict │ 157.7021312713623 │ 10000000 │
│ LCDict │ 93.76335144042969 │ 10000000 │
└────────┴───────────────────┴──────────┘
LowCardinality 数据类型的表占用存储空间较小。
下面进行查询,每个查询取三次结果的平均值作为比较的依据。
4. 查询对比
笔者在这里只比较 String 数据类型,对于 Float64 和 UInt64 数据类型,大家自行查询比较。
4.1 group by 查询
SELECT str, count(str) AS cnt FROM Dict
GROUP BY str;
三次查询耗时(sec):0.017+0.017+0.017
SELECT uintlc, count(uintlc) AS cnt FROM LCDict
GROUP BY uintlc;
三次查询耗时(sec):0.010+0.011+0.011
4.2 like 匹配查询
如果不加 count 的话,返回数据比较多,打印结果是需要花费时间,影响结果。所以使用 count 统计结果数。
select count(1) from (SELECT d2, d1, str FROM Dict
WHERE str LIKE '%en');
数据量:1998880
三次查询耗时(sec):0.082+0.076+0.077
select count(1) from (SELECT d2, d1, strlc FROM LCDict WHERE strlc LIKE '%en');
数据量:2000744
三次查询耗时(sec):0.015+0.013+0.015
4.3 点条件查询
如果不加 count 的话,返回数据比较多,打印结果是需要花费时间,影响结果。所以使用 count 统计结果数。
select count(1) from (SELECT d2, d1, str FROM Dict
WHERE str = 'ten' ORDER BY d2, d1);
数据量:999928
三次查询耗时(sec):0.049+0.049+0.049
select count(1) from (SELECT d2, d1, strlc FROM LCDict
WHERE strlc = 'ten' ORDER BY d2, d1);
数据量:1001054
三次查询耗时(sec):0.031+0.032+0.032
LowCardinality 理解
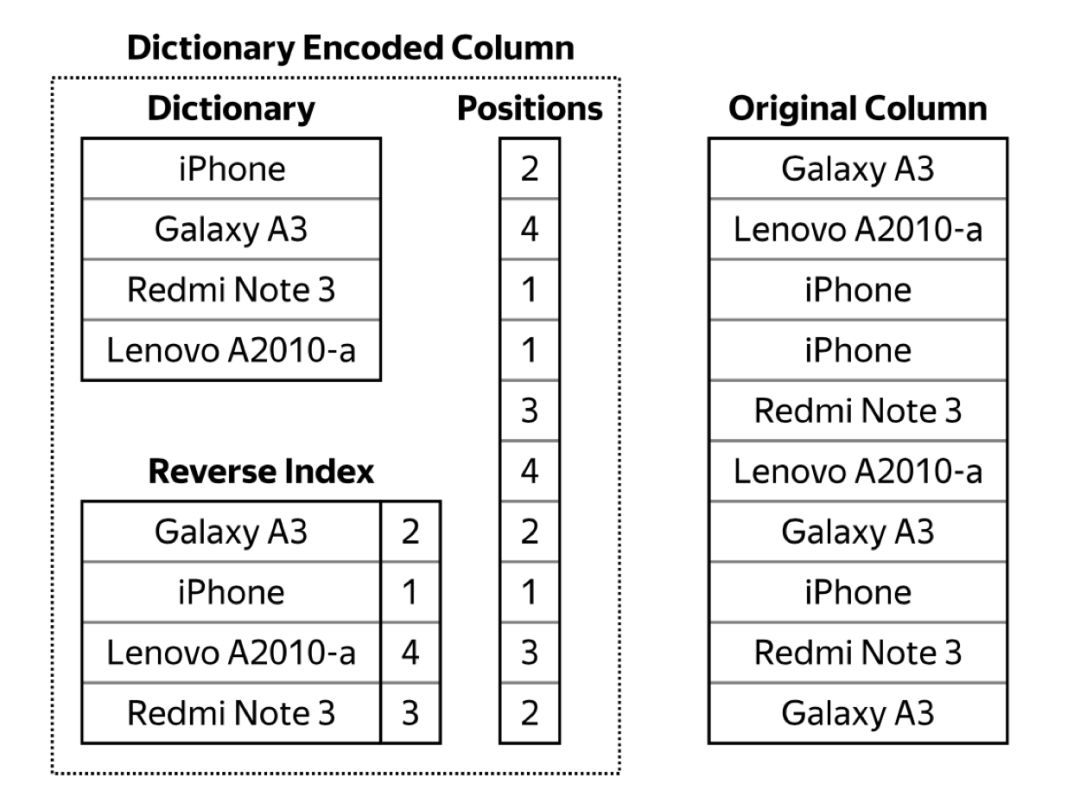
ClickHouse 的高性能给我们留下了深刻的印象,高性能是靠非常谨慎和智慧的工程来实现的。 LowCardinality 数据类型就是其中的一个示例。其实 LowCardinality 是字符串字典编码实现的,其中字符串被编码为 Position
(positions,可以理解为索引),并通过 position-to-string
的映射引用字典。当源字符串很长且去重后值的数量不是很大时,它的效果最佳。ClickHouse 没有硬性限制具体去重后值的大小,如果去重后值的数量低于 1000 万,效果通常会很好。对于具有多个 partition 和 part 的 ClickHouse 大表,如果在 part 级别保留 1000 万限制,则去重后值的总数甚至可能更高。
LowCardinality 支持 String、Number、Date、DateTime、Nullable数据类型。
在内部,ClickHouse 创建一个或多个文件以存储 LowCardinality 字典数据。如果所有 LowCardinality 列都符合 8192 个不同的值,那么每个表可以是一个单独的文件,如果去重值的数量更多,则每个 LowCardinality 列就使用一个文件。
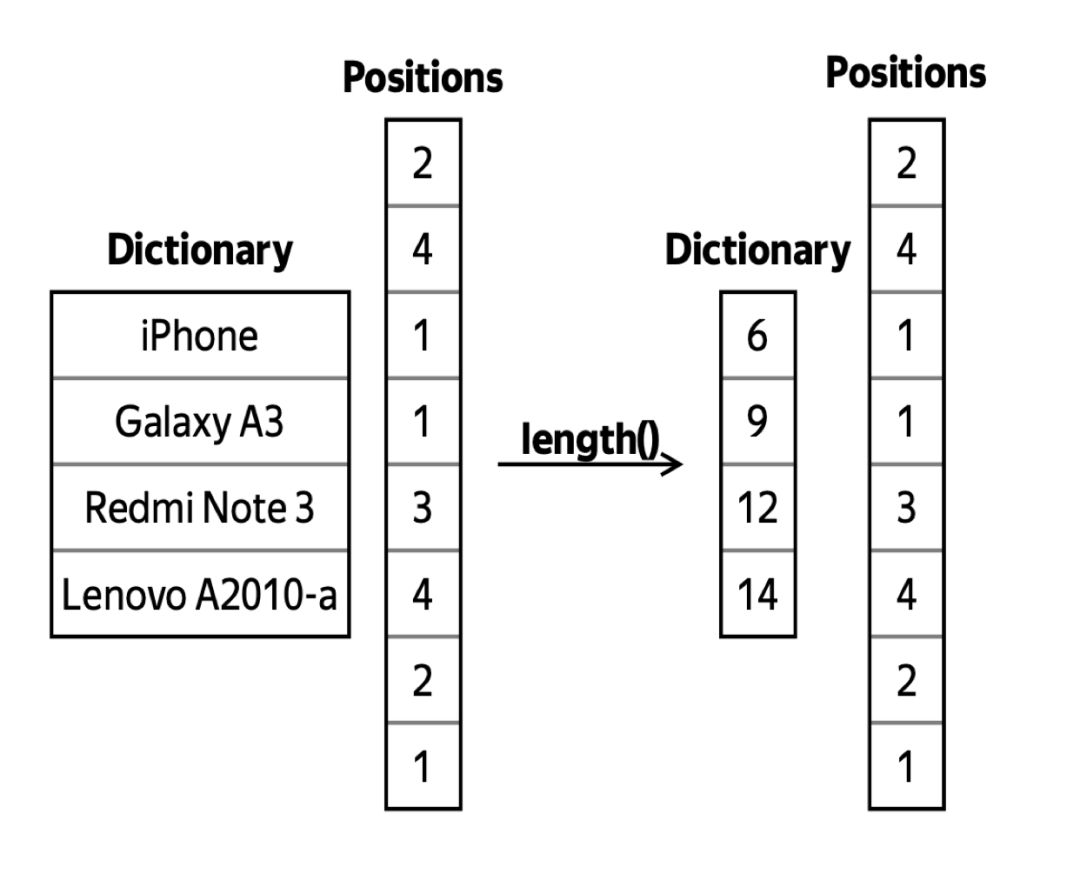
ClickHouse LowCardinality 优化不仅限于存储,它还使用字典 position 进行过滤、分组和加速某些查询功能(例如 length())等。这就是为什么我们在 Query 1 中看到的改进要比纯粹从存储效率提升的效果更大的原因。在分布式查询中,ClickHouse 还将尝试在大多数查询处理中对词典 position 进行操作。
LowCardinality 与 Enum
值得一提的是,还有一种用字典编码字符串的可能性,那就是枚举类型:Enum。
ClickHouse 完全支持枚举。从存储的角度来看,它可能甚至更高效,因为枚举值存储在表定义上而不是存储在单独的数据文件中。枚举适用于静态字典。但是,如果插入了原始枚举之外的值,ClickHouse 将抛出异常。枚举值中的每个更改都需要 ALTER TABLE,这可能会带来很多麻烦。LowCardinality 在这方面要灵活得多。
总结
ClickHouse 是一个功能丰富的DBMS。它具有针对最佳性能的许多精心设计的技术决策, LowCardinalty 是其中之一。如果使用得当,它将有助于减少存储并显着提高查询性能。虽然 LowCardinality 支持好几种数据类型,但是笔者建议对数字列使用 set index,对低基数字符串列使用 LowCardinality。
参考
https://www.altinity.com/blog/2019/3/27/low-cardinality
https://github.com/yandex/clickhouse-presentations/blob/master/meetup19/string_optimization.pdf
