




1. 背景
为了更深入地研究 Apache Doris 开源项目,今天笔者和大家聊一下 Doris 项目所使用的 Google Mesa 技术。
关于该项目的详细论文资料可以访问:Geo-Replicated, Near Real-Time, Scalable Data Warehousing
论文下载地址:https://storage.googleapis.com/pub-tools-public-publication-data/pdf/42851.pdf
笔者不会在本篇文章中带着大家去完整读一遍论文,而是把我们需要关心的点总结出来,快速地熟悉该项目解决的问题以及提供的功能特性和适应的场景。
2. Mesa 介绍
Mesa 项目是 Google 大概在2014年发表的论文,实现全球复制以及高度可扩展的分析型数据仓库系统。在 Google 内部,Mesa 主要解决 Google 在线广告报表和分析业务,拥有准实时的数据更新能力和低延迟的数据查询性能。Mesa 能够处理 PB 级别的数据量,每秒完成数百万行数据的更新,每天服务几十亿次查询和数万亿次数据读取操作。
另外,Mesa能够全球复制功能,可以跨多个数据中心备份,并且在低延时提供一致的和可重复的请求响应,即使其中一个整个数据中心挂掉也没问题。
3. 需求驱动
Google 在多个地域运行着一个可拓展的广告平台,它每天为全球的用户提供数十亿广告服务。针对广告行业的种种需求,要求 Google 针对数据存储实现以下需求:
Atomic Updates
原子性更新,不可能在部分更新完成时就查询到系统的某个状态。
Consistency and Correctness
一致性和正确性。要求强一致性并且是可重复的,即使这个请求跨越了多个数据中心。
Availability
可用性。没有单点故障SPOF,不能停服务。
Near Real-Time Update Throughput
准实时的更新吞吐量。系统支持持续的更新,支持增量实时更新,吞吐要达到百万行/秒,更新操作在几分钟内即可被查询到。
Query Performance
查询性能。系统既要支持低延迟的用户报表查询请求,也要支持高吞吐的Ad-hoc即席分析查询。低延迟要保证99%的延迟在几百毫秒内,并且总体的查询吞吐量一天要达到数万亿行。
Scalability
可扩展性。这个系统必须能够随着数据量和请求数的增长而扩展,能够支持万亿行和PB级别的数据量。
Online Data and Metadata Transformation
在线数据和元数据变更。业务不断变化,对于schema的变更,包括加表、删表、加列、减列,新建索引,修改物化视图等的操作都必须不能停止服务的在线完成,而且不能影响数据更新和查询。
于是,Mesa 是 Google 对于这些技术性和可操作性难题的解决方案。论文中有一段描述,说的非常清楚,笔者直接贴出:
Mesa is a distributed, replicated, and highly available data processing, storage, and query system for structured data. Mesa ingests data generated by upstream services, aggregates and persists the data internally, and serves the data via user queries.
总结几点就是:
分布式
多副本
高可用
结构化数据
数据处理、存储和查询系统
对于 Mesa 的技术选型,Mesa 充分利用 Google 的基础架构和服务,例如 Colossus(Google 下一代分布式文件系统)、BigTable 和 MapReduce。为了实现存储的可扩展性和可用性,数据进行水平分区和复制。更新操作将应用在单个表或者多个表的粒度上。为了实现在更新时一致而且可重复的查询,底层存储的数据都是多版本的。为了实现可扩展的更新,数据更新都是批量处理、同时分配一个新的版本号和周期性(例如每几分钟)合并到 Mesa 中。为了实现在多个数据中心之间更新的一致性,Mesa 使用基于 Paxos 的分布式一致性协议。
接着论文开始介绍现有的业界解决方案。基于关系型技术和数据立方体的方案,很难做准实时更新,Google 内部的系统中 BigTable 不支持跨行事务,Megastore、Spanner 和 F1 都是 OLTP 系统,提供跨地理复制数据的强一致性,但是不支持海量数据的高吞吐写入和更新。Mesa 借鉴了基于 BigTable 和 Spanner 底层的 Paxos 技术用于元数据存储和维护。
既然业界现有解决方案存在这样或那样的问题,那么 Mesa 创新之处是什么?论文从存储设计和系统架构方面进行描述。
4. Mesa 存储系统
存储在 Mesa 中的数据主要由两种属性组成:维度属性和度量属性,这实际可以看做是一种KV模型,Key 就是维度属性(维度列),Value 就是度量属性(指标列)。
4.1 数据模型
在 Mesa 中,数据是使用表来管理的。每个表有一个用于指定其结构的 Schema 。特别的是,一个表 Schema 指定了表的键空间 K(key space K)和相关的值空间 V(value space V),K 和 V 都是集合。表 Schema 也指定聚合函数 F : V x V-> V,用于聚合相同键的所有值。这个聚合函数一定要是相关的(结合律)(例如对于所有值F且v0 , v1 , v2 ∈ V,(F(v0,v1),v2) = F(v0,F(v1,v2))实际上,它通常也是交换的(交换律)(例如F(v0,v1) = F(v1,v0)),尽管 Mesa 确实有不可交换聚合函数的表(例如F(v0,v1) = v1来替换一个值)。这个 Schema 也用于指定表的一个或多个索引,这些索引都是在 K 中的有序索引。
键空间 K 和值空间 V 代表着每个列的多个元组,每个元组有一个固定的类型(例如int32、int64、string 等等)。Schema 为每个独立的 Value 列指定了一个相关的聚合函数,而 F 是隐式定义的 Value 列,
例如:
F((x1,...,xk),(y1,...,yk)) = (f1(x1,y1),...,fk(xk,yk))
其中 (x1,...,xk),(y1,...,yk) ∈ V 是 column values 的任意两个元组,而且 f1,...,fk 是 Schema 为每个 value column 显示定义的。
上面是不是听起来有点乱,其实想要表达的意思很简单,举个例子说明一下。
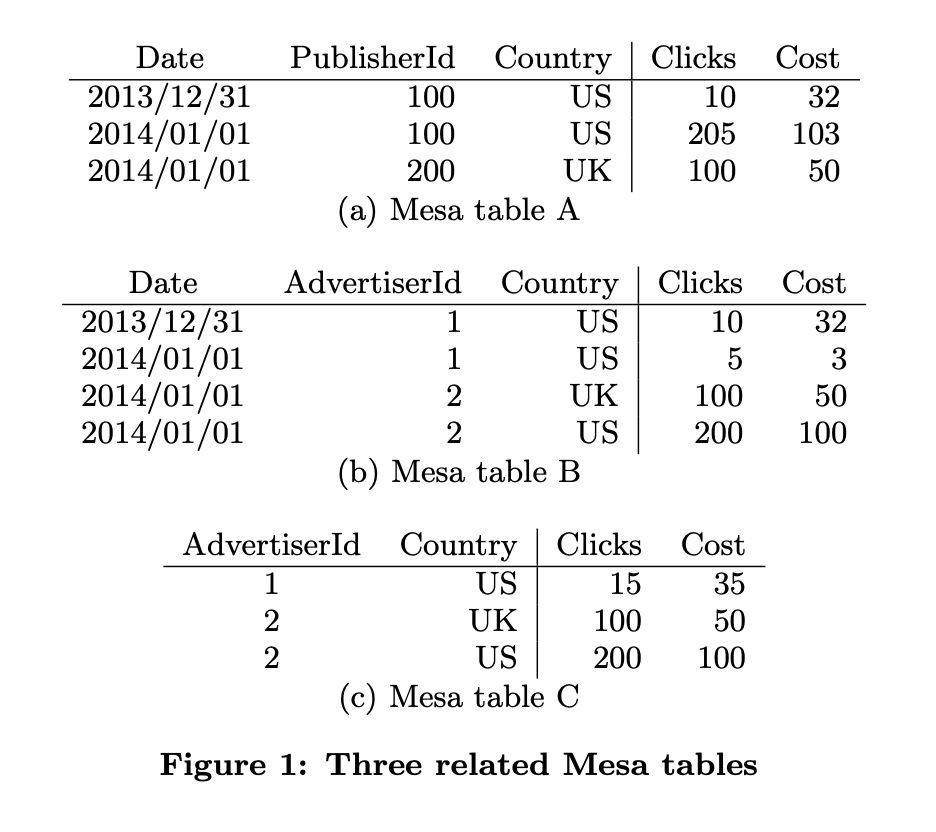
图1显示了三张典型的表:
Mesa table A 的维度列包括 Date, PublisherId, Country,指标列是 Clicks, Cost,聚合函数是 SUM。
Mesa table B 的维度列包括 Date, AdvertiserId, Country,指标列是 Clicks, Cost,聚合函数是 SUM。
Mesa table C 是 Table B 的物化视图,维度列是 AdvertiserId, Country,指标列是 Clicks, Cost,聚合函数是 SUM。
在生产环境中,Mesa 包含超过一千个表,大部分的表拥有数百个列,而且使用各种聚合函数。
4.2 更新和查询
为了实现高吞吐量的更新,Mesa 按照批量方式来更新数据。为了在数据更新时不影响数据查询一致性和实现更新的原子性,每个更新批次都会带一个自增的版本号,Mesa 按版本顺序来执行更新操作,确保在移至下一个更新操作前原子性地合并更新操作,其实就是采用了 MVCC 机制,做到无锁的更新。
再看一个示例:
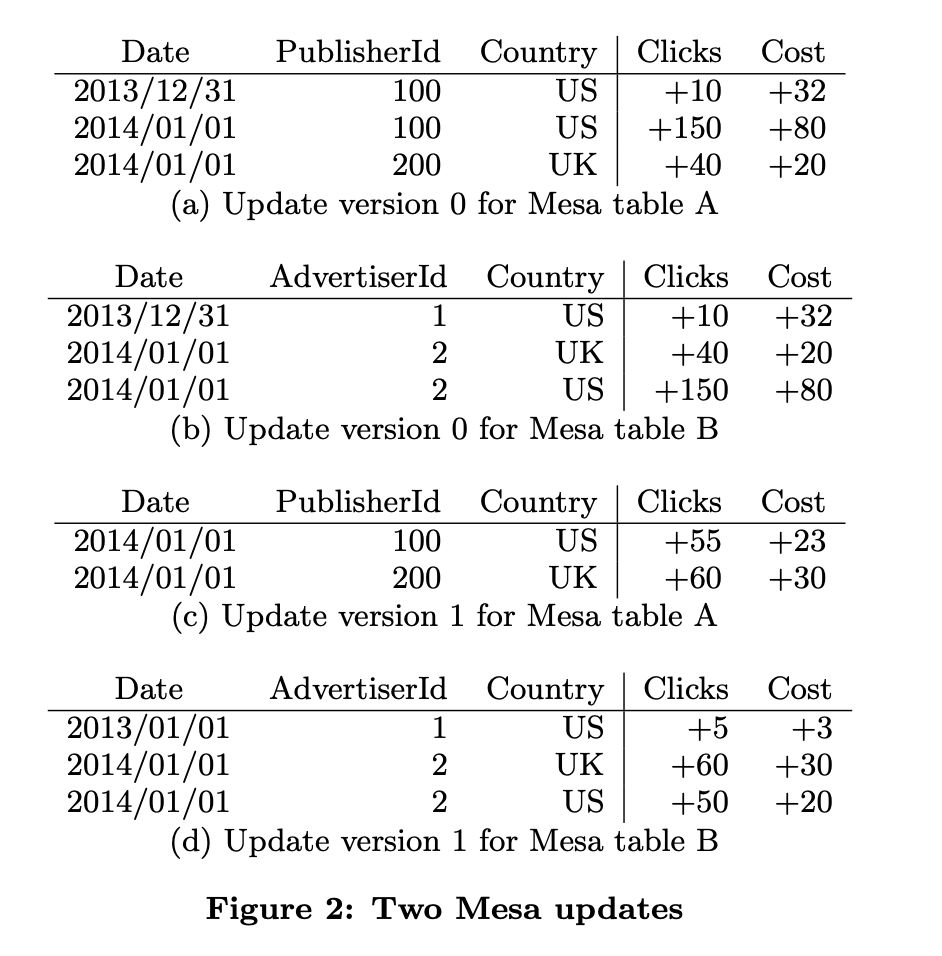
图2 显示了两个针对 图1 定义的表的更新操作,可以看出 table A 和 table B 是通过两个批次的更新,经历了两次版本变化,而 table C 是 table B 的物化视图,Mesa 会自动对 table C 处理这些更新操作,因为它能直接从 table B 的更新中衍生出来。对于 table B的每个批次的更新,table C 都保持了和 table B 的一致原子更新。
因为 Mesa 更新操作采用了MVCC机制,所以查询时也需要指定版本号。同时,根据论文的描述,还需要指定基于维度的 Predicate ,在 key space上做过滤的谓词条件。
4.3 版本化的数据管理
版本化的数据在 Mesa 中的更新和查询处理中都起着至关重要的作用。然而,它也面临着多种挑战,具体如下:
第一、独立地存储每个版本从存储的角度是非常浪费的,占用存储空间,而聚合后数据会更小。
第二、在查询的时候访问各个版本并且聚合它们成本很高,而且增加了访问延时。
第三、原生的在每次更新时对所有版本的预聚合开销非常高。
为了应对这些挑战,Mesa 提出了 Delta 的概念,对于每次的更新,相同的 Key 都做预聚合,形成一个独立的 Singleton delta,一个 Singleton delta 包括很多行数据,以及一个version = [V1, V2],V1 和 V2 是更新的版本号,而且 V1 ≤ V2。在某些场景下可能会不存储原始数据,也就不能下钻到最细的粒度,但是做了上卷,所以会非常节省空间。
Delta 之间可以做 merge。例如一个 delta 为 [V1, V2] 和另一个 [V2 + 1, V3] 可以聚合产生 [V1,V3]。
Mesa 要求查询指定的版本号不能无限的小,需要在一个时间范围前(比如24小时之内),这是因为还会存在一个 base compaction 的策略,用来归并所有的历史 delta,从查询效率来说,通过合并小文件来减少随机I/O的次数。合并了 base 之后,这些老版本的 delta 就可以删除掉了。
但是 base compaction 往往是每天 compaction,但是考虑分钟级别的导入,也会有成百上千的小文件需要在运行时做查询,也就多了非常多的随机I/O。为了加速实时的在线查询,并且平衡导入的高吞吐,Mesa 提出了多级的 compaction 策略,这里 Mesa 实际用了两级存储,会存在一个 cumulative compaction 的过程,例如每当积累到10个 Singleton delta,就做一次小的多路归并,合并成一个 cumulative delta。再积累了10个之后再做一次多路归并即可。
Singleton delta 每到一定的版本数,比如下图中是每隔10个版本,就通过 cumulative compaction 将10个 singleton delta 合并为1个 cumulative delta ,最终每天会通过 base compaction 将所有一定周期的内的 delta 都合并为 base delta。所以查询时只需要查询1个 base delta, 1个 cumulative delta 和少数 singleton delta 即可。
看一下论文中的示例:

上图的中 Base 是24小时之前的文件,按每天粒度聚合而成。还有61-92共32个 singleton delta,它们都是每个批量导入后预聚合的数据,如果不存在 cumulative delta,那么查询条件的版本指定到91,除了需要查询 Base,另外还需要查询61-91这32次的随机I/O,这种延迟明显太大,那么如果有了 cumulative delta 就可以按照最短路径的算法,做一次查询只需要 Base,然后查询61-90这个 cumulative delta,最后查询91这一个 singleton delta,一共3次随机I/O就可以查询出来结果。
4.4 Mesa物理数据和索引结构
Mesa 的 delta 是基于 delta compaction 策略创建和删除的。一旦 delta 已经创建,它是 immutable 的,因此 Mesa 的物理存储格式不需要支持增量修改。
Mesa 的存储格式要尽可能的节约空间,同时支持 key 快速查询,Mesa 设计了索引 Index 和数据 Data 文件,物理上 Index 和 Data 数据是分开的,每个 Index 实际就是 Short Key 的顺序排列,再加上 offset 偏移量,每个 Data 就是 Key+Value 的顺序存储。每个表都是这样多个 Index 和多个 Data 的集合。
Data 文件中的数据按照 Key 有序排列,按行切块形成 row block,按列存储,这种格式和现在的 ORC、Parquet 类似,Row Block的大小一般不大,它是从磁盘加载到内存的最小粒度,使用这种格式很容易做压缩,因为每一列的格式都是相同的,可以做一些轻量级的编码比如RLE、字典编码等,在这个基础之上再做重量级的压缩,比如LZO、Snappy、GZIP等,就可以实现压缩比很高的存储。
Index 文件存储了 Short Key,Short Key 关联一个 Row Block,这样只需要把 Index 加载到内存,在 Index 文件中做二分查找定位 Row Block 在 Data 文件中偏移量 offset,然后加载 Row Block 到内存,再做一些 Predicate filter 的 Scan,对于 Key 相同的按照聚合函数做聚合即可把结果查到。
5. Mesa 系统架构
Mesa 是使用 Google 通用的基础架构和服务构建的,包括 BigTable 和 Colossus 。Mesa 运行在多个数据中心(DC, Datacenter)里,每个数据中心运行一个 Mesa 实例。Mesa 的元数据存储在 BigTable,数据存储在Colossus 。
5.1 单个DC实例
每个 Mesa 实例是由两个子系统组成:更新和查询系统。这些子系统是解耦的,可以分别扩展以满足各自的性能。所有的元数据都持久化在 Bigtable 中,所有的数据文件都存储在 Colossus 中。
5.1.1 更新系统
论文中列举了更新系统的主要职责,包括:
执行所有必要的操作,确保数据在本地 Mesa 实例中正确
加载更新
执行表 compaction
应用 schema change
运行表 checksum 检查
以上操作都是由 Controller/Worker 架构的组件来管理,系统架构图如下:
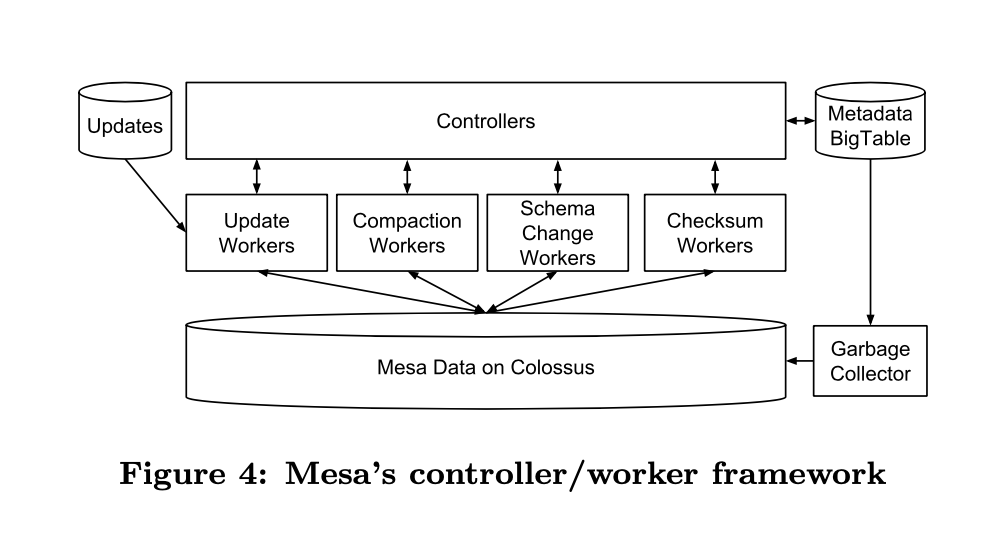
Controller 的职责如下:
所有 table metadata 的缓存
上图中各种 worker 的调度器
所有的 metadata 都存储在 BigTable 中,所以 Controller 可以是一个无状态的服务,Controller 在启动的时就去 BigTable 拉取元数据,所以更新系统挂掉是不会影响查询的。Controller 通过 RPC 接收外部的请求,然后把 Task 投递到 queue 中。
Worker 采用隔离的策略,上图架构中有4个 Worker Pool。每个 Worker 都有自己独立的职责,比如 Update Workers 负责数据的更新、Compaction Workers 负责 delta compaction、Schema Change Workers 负责实现table schema 在线变更、Checksum Workers 负责校验数据文件是否损坏。
图中还有一个 GC(Garbage Collector)主要作用是负责 Worker 销毁的,即当一些 Workers 失败时,清理遗留的中间数据,也会防止 Worker 死掉从而影响 Worker Pool。
为了支持更好的扩展性,Controller 可以做 sharding,同时 Controller 不存在单点(SPOF),因为所有的 metadata 都在 BigTable 中存储,可以快速进行重建状态。
5.1.2 查询系统
查询子系统架构如下图所示:
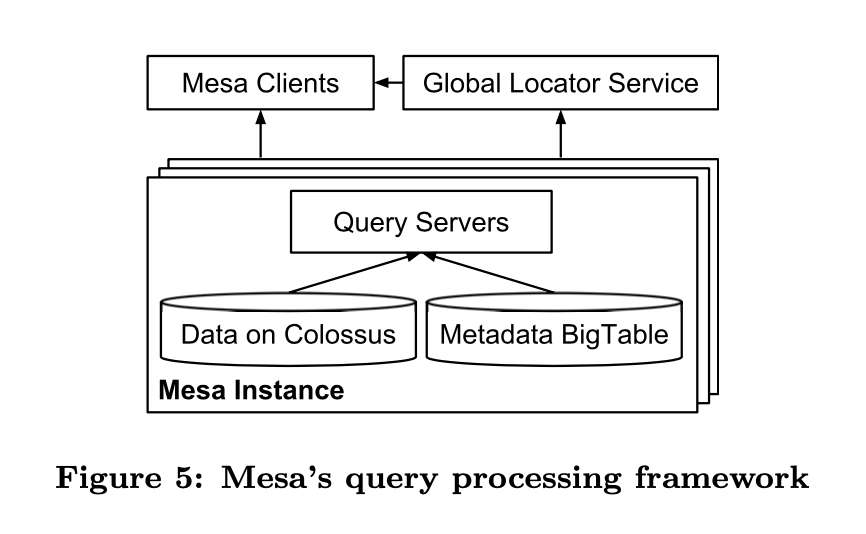
Mesa 查询子系统的架构相对比较简单,大家也容易理解,这里简单说一下。
查询步骤大致如下:
Query Servers 获取用户查询请求
查询 table metadata
决定数据存储在哪些文件
发起查询请求,数据聚合处理
将结果转换为客户端需要的格式,并响应客户端
Mesa 作为一个简单的通用存储查询系统,只提供了有限的语义,包括filter和group by,剩下的 Higher-level 的语义包括 JOIN、子查询等等都由上层系统实现,比如 MySQL、F1、Dremel。
Mesa 为了满足用户对不同类型查询的不同性能需求(比如在线的 reporting 要求低延迟;Ad-hoc 的分析查询一般要求高吞吐),利用标签对低延迟的点查询和高吞吐的批量查询进行隔离和优先级设置,即采用了分治策略,把不同的 Query System 标记不同的 label,这样在查询的时候可以进行选择。这里还是比较像 HBase RSGroup 隔离机制。
5.2 Mesa 多个DC部署
Mesa 为了提供高可用性,它能够部署在全球各个数据中心中。每个实例是独立的,而且保存了数据的单独拷贝。
5.2.1 一致性更新机制
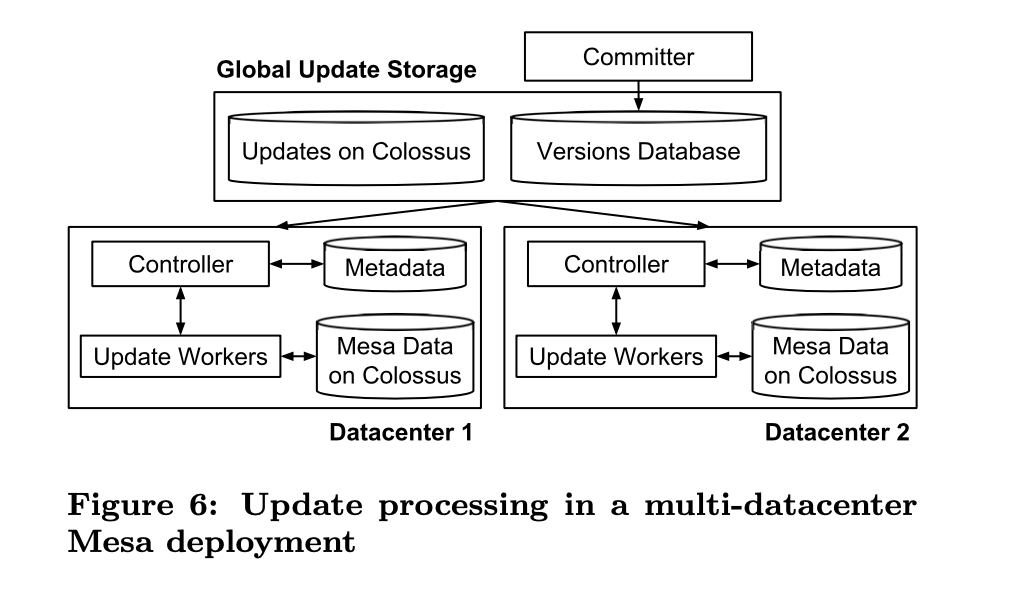
我们已经知道在 Mesa 中的所有表都是多版本的,允许 Mesa 在处理新更新的同时继续为先前状态提供一致的数据。
如上图所示,为了实现多DC的一致性更新,Mesa 引入了 Committer 组件,负责协调在多DC实例下,一次只更新一个 version。在更新前,Committer 会给每个 batch 的更新分配一个 version,保存在上图中的 Versions Database(a globally replicated and consistent data store build on top of the Paxos consensus algorithm)中,然后 Mesa 的 Controller 会监听 Versions Database 的变化,如果有update,则拉取该update并且更新本DC,成功后通知 Versions Database,Committer 检查 verion 提交的一致性条件是否满足,比如5个里面3个成功了,那么commit这个version,再继续下个批次的更新。
这种方案的特点在于:
1. 所有新的查询都会定位到已提交的版本,而且更新是batch处理的,Mesa 在查询和更新中不需要任何的锁
2. 数据是异步更新,元数据是基于Paxos协议同步更新
这两个特点可以让 Mesa 实现非常高的数据更新和查询的吞吐量。
5.2.2 新的 Mesa 实例
随着 Google 建立新的DC并淘汰旧的DC,就需要启动新的 Mesa 实例。要启动新的Mesa 实例,使用 peer-to-peer 负载机制。Mesa 具有一个特殊的负载工作程序(类似于 controller/worker 架构中的其他 worker),该 worker 将表从另一个 Mesa 实例复制到当前实例。然后,在表提供可用查询之前,Mesa 使用 Update Workers 保持和该表的最新已提交的 version 一致。在启动过程中,我们将所有表加载到新的 Mesa 实例中,Mesa 也使用相同的 peer-to-peer 负载机制从表损坏中恢复。
6. Mesa 增强功能
论文在这一部分介绍了 Mesa 设计的一些高级功能:
Mesa 查询性能优化
使用 delta 裁剪优化技术,避免读取不必要的 delta
使用 scan-to-seek 优化技术,充分利用索引,获取数据
使用 resume key 技术,Mesa 典型地将一个流式数据给客户端,每次一个块。而每一个块,Mesa 都附上一个 resume key。如果一个查询服务器不响应了,受影响的 Mesa 客户端能够马上切换到另一个查询服务器并带上 resume key,从 resume key 中恢复查询而不是重新执行整个查询。
Mesa Worker 并行化操作
为了获得更好的可伸缩性,Mesa 通常使用 MapReduce 框架来并行化不同类型的 Worker 任务的执行。
Mesa Schema Changes
Mesa Schema Changes 就是指 scheme 的变更不会影响数据的查询和更新。我们知道 Schema 变更在实际的业务中,会经常遇到的,所以必须要求 Schema 在线变更。
要实现Schema在线变更,最普通的办法如下:(1)基于固定 update version 的表拷贝一份数据并按照新的 schema version 进行存储 (2)回放这个表的所有更新,直到新的 schema version是当前值 (3)切换该 schema version 作为新的 schema version
此方法虽然可靠,但是代价昂贵,特别是对于涉及许多表的架构更改而言。
针对上面的问题,Mesa 提出了 linked schema change 的方法,解决这个问题,大概意思就是通过把旧的和新的 schema version 认为是一个更新、合并。但是这种做法无法处理所有情况,比如:删除排序列中的一列、修改列的类型等。
防止数据损坏
包括存储的checksum,单个实例的检查,定期执行 global offline checks 等。
7. 经验和教训
这部分提到几点,感兴趣的可以细看:
分布式,并发和云计算
模块化,抽象和分层架构
容量规划
应用层的假设
全球同步备份
数据损坏和组件失败
测试和增量部署
人为因素
最后几部分介绍了 Mesa 生产环境的指标、Mesa 相关工作以及总结等,不再细说。
到此,关于 Google Mesa 基本介绍完了,希望大家能够结合论文深入理解。笔者将在下篇文章中介绍 Doris 与 Mesa 的关系。如果读者深入学习的话,可能已经知道了,Doris的存储借鉴了 Mesa。
