




说明
这里先不介绍ClickHouse的背景知识了,具体细节请查阅官方https://clickhouse.yandex
ClickHouse的github访问如下:
https://github.com/yandex/ClickHouse
环境

下载安装包
ClickHouse官方没有提供rpm包,但是Altinity第三方公司提供了。
下载地址:
https://packagecloud.io/altinity/clickhouse
下载的包:
clickhouse-client-19.1.7-1.el7.x86_64.rpmclickhouse-common-static-19.1.7-1.el7.x86_64.rpmclickhouse-server-19.1.7-1.el7.x86_64.rpmclickhouse-server-common-19.1.7-1.el7.x86_64.rpmclickhouse-test-19.1.7-1.el7.x86_64.rpm
创建目录
mkdir -p /data/clickhouse/tmp /data/clickhouse/logs /data/clickhouse/lockchown clickhouse:clickhouse -R /data/clickhouse
配置文件
安装好rmp包后,默认配置文件在/etc/clickhouse-server/目录下,主要涉及以下3种配置文件,也可以自定义配置文件位置,如果修改了目录记得连带修改启动脚本。
1. /etc/init.d/clickhouse-server启动脚本
vi /etc/init.d/clickhouse-server
CLICKHOUSE_USER=clickhouseCLICKHOUSE_GROUP=${CLICKHOUSE_USER}SHELL=/bin/bashPROGRAM=clickhouse-serverCLICKHOUSE_GENERIC_PROGRAM=clickhouseCLICKHOUSE_PROGRAM_ENV=""EXTRACT_FROM_CONFIG=${CLICKHOUSE_GENERIC_PROGRAM}-extract-from-configCLICKHOUSE_CONFDIR=/etc/$PROGRAMCLICKHOUSE_LOGDIR=/data/clickhouse/logsCLICKHOUSE_LOGDIR_USER=rootCLICKHOUSE_DATADIR_OLD=/data/clickhouse-oldCLICKHOUSE_DATADIR=/data/clickhouseLOCALSTATEDIR=/var/lockCLICKHOUSE_BINDIR=/usr/binCLICKHOUSE_CRONFILE=/etc/cron.d/clickhouse-serverCLICKHOUSE_CONFIG=$CLICKHOUSE_CONFDIR/config.xmlLOCKFILE=$LOCALSTATEDIR/$PROGRAMRETVAL=0CLICKHOUSE_PIDDIR=/var/run/$PROGRAMCLICKHOUSE_PIDFILE="$CLICKHOUSE_PIDDIR/$PROGRAM.pid"
主要是修改数据和日志存储目录。
2. /etc/clickhouse-server/config.xml
全局信息配置文件
<?xml version="1.0"?><yandex><logger><!-- Possible levels: https://github.com/pocoproject/poco/blob/develop/Foundation/include/Poco/Logger.h#L105 --><level>trace</level><!-- <level>error</level> --><log>/data/clickhouse/logs/clickhouse-server.log</log><errorlog>/data/clickhouse/logs/clickhouse-server.err.log</errorlog><size>1000M</size><count>10</count><!-- <console>1</console> --> <!-- Default behavior is autodetection (log to console if not daemon mode and is tty) --></logger><!--display_name>production</display_name--> <!-- It is the name that will be shown in the client --><http_port>8123</http_port><tcp_port>9000</tcp_port><!-- Port for communication between replicas. Used for data exchange. --><interserver_http_port>9009</interserver_http_port><!-- Hostname that is used by other replicas to request this server.If not specified, than it is determined analoguous to 'hostname -f' command.This setting could be used to switch replication to another network interface.--><!--每个节点配置本机主机名--><interserver_http_host>ckprd1</interserver_http_host><!-- Listen specified host. use :: (wildcard IPv6 address), if you want to accept connections both with IPv4 and IPv6 from everywhere. --><!-- <listen_host>::</listen_host> --><!-- Same for hosts with disabled ipv6: --><listen_host>0.0.0.0</listen_host><!-- Path to data directory, with trailing slash. --><path>/data/clickhouse/</path><!-- Path to temporary data for processing hard queries. --><tmp_path>/data/clickhouse/tmp/</tmp_path><!-- <timezone>Europe/Moscow</timezone> --><timezone>Asia/Shanghai</timezone><!--集群相关配置--><include_from>/etc/clickhouse-server/metrika.xml</include_from><remote_servers incl="clickhouse_remote_servers" /><zookeeper incl="zookeeper-servers" optional="true" /><macros incl="macros" optional="true" /></yandex>
3. /etc/clickhouse-server/metrika.xml
集群信息配置文件
<?xml version="1.0"?><yandex><!-- cluster setting --><clickhouse_remote_servers><mcd_prod_cluster_1st><!-- shard01 --><shard><!-- Optional. Shard weight when writing data. Default: 1. --><weight>1</weight><!-- Optional. Whether to write data to just one of the replicas. Default: false (write data to all replicas).1. internal_replication为false时候,(前提是往分布表写入数据)会自动往同一shard下所有备份表写入相同数据,不需要任何其他外力,单独设置这个参数即可;但是会出现各备份之间数据不同步的情况,因为此种情况下往分布式表里面写数据,后台算法会先按照weight将数据分成shard数量堆,然后将对应堆的数据分别写入该shard下面的所有备份表中,有可能存在同样的数据写入A备份成功但是写入B备份失败的情况,这里是没有校验的;2. internal_replication为true时,一定要配合zookeeper和ReplicatedMergeTree引擎表使用,如果不配合这些,经本人测试查询数据时会出现严重错误,请切记--><internal_replication>false</internal_replication><replica><host>ckprd1</host><port>9000</port></replica><replica><host>ckprd2</host><port>9000</port></replica></shard><!-- shard02 --><shard><weight>1</weight><internal_replication>false</internal_replication><replica><host>ckprd3</host><port>9000</port></replica><replica><host>ckprd4</host><port>9000</port></replica></shard></mcd_prod_cluster_1st></clickhouse_remote_servers><!-- ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/hits', '{replica}')1. /clickhouse/tables/{layer}-{shard}/hits作为整体可以理解为表在zookeeper中的定位和识别符2. 同一个{layer}-{shard}下面的表互为备份,会自动同步3. layer我将之理解为集群识别符,虽然其可以与上面clickhouse_remote_servers配置中的cluster名称不一样;同一个配置文件是可以配置多个集群的,因此有layer这一说法4. hits可以与表名相同,但是表名改变时这里不会变,因为这里的含义是,表在zookeeper中的定位和识别符5. replica是备份序号的识别符,只要不同即可,可以设置为与该节点hostname相同(注意replica一定要不同)6. macros中的值设置会对应到ReplicatedMergeTree中的变量(就是大括号的部分),这样在每个节点建立local表时,可以使用完全相同的SQL语句,因为变量由这里的配置控制--><macros><layer>mcd_prod_cluster_1st</layer><!--根据前面shard的配置,例子中总共2个shard--><shard>shard01</shard><!--每个节点配置本地主机名即可,或者唯一的数字id--><replica>ckprd1</replica></macros><!-- 监听网络(貌似重复) --><networks><ip>::/0</ip></networks><!-- zookeeper --><zookeeper-servers><node index="1"><host>ckprd1</host><port>2181</port></node><node index="2"><host>ckprd2</host><port>2181</port></node><node index="3"><host>ckprd3</host><port>2181</port></node></zookeeper-servers><!-- 数据压缩算法 --><clickhouse_compression><case><min_part_size>10000000000</min_part_size><min_part_size_ratio>0.01</min_part_size_ratio><method>lz4</method></case></clickhouse_compression></yandex>
ClickHouse常用架构
•单实例1.单机部署,安装好rpm包后,简单修改配置文件即可启动;2.单实例不建议线上使用,只做功能测试;3. MergeTree,引擎适用于单机实例,查询性能非常高。
•分布式+高可用集群
ClickHouse引擎有很多,而每个引擎实现的功能不同,目前在实现分布式高可用的方案中主要有如下两种方式:
1.基于Zookeeper实现分布式
基于Zookeeper来实现。同一集群配置多个分片,而每个节点都配置同样的配置文件。ReplicatedMergeTree里共享同一个Zookeeper znode路径的表,就可以实现相互同步数据。
2.ReplicatedMergeTree
复制引擎,基于MergeTree实现数据复制。Distributed,分布式引擎,本身不存储数据,将数据分发汇总。
分布式高可用集群架构
以下是2个分片、2个副本集的架构,Zookeeper机器可以跟ClickHouse共用,但是如果压力较大,IO消耗较多,可能会延迟,生产环境建议分开部署
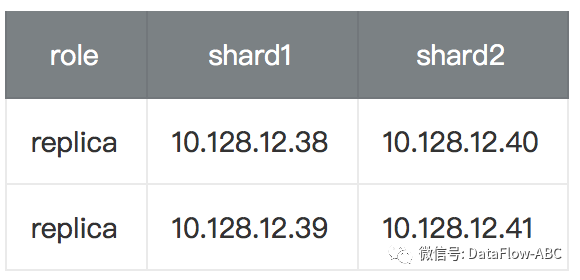
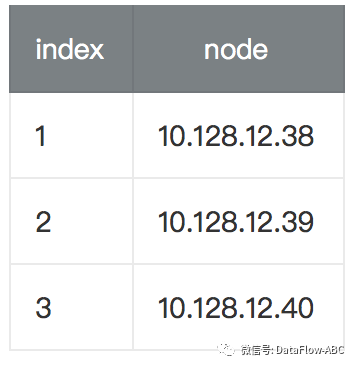
zookeeper集群:
建议3.4.9之后的版本
server.1=192.168.12.38:2888:3888
2888 leader/follower传输信息端口,3888选举端口
server.2=192.168.12.39:2888:3888
2888 leader/follower传输信息端口,3888选举端口
server.3=192.168.12.40:2888:3888
2888 leader/follower传输信息端口,3888选举端口
启动、停止和重启操作
/etc/init.d/clickhouse-server start
/etc/init.d/clickhouse-server stop
/etc/init.d/clickhouse-server restart
访问
clickhouse-client -h ckprd1
clickhouse-client -u default --password password -hckprd1
