




导言
Iceberg社区正在推进一个重磅更新row-level delete, row-level delete功能是支持update/delete/merge into等DML语义的重要前提。本文将会解读下row-level delete的设计思路,当前社区进展。
Row-level delete实现方式
简单的说row-level delete是指根据一个条件从一个数据集里面删除指定行。它实现方式可以分为Copy on Write模式和Merge on Read模式,其中Copy on Write模式可以保证下游的数据读具有最大的性能,而Merge on Read模式保证上游数据插入、更新、和删除的性能,减少传统Copy on Write模式下写放大问题。Iceberg社区在去年已经有Copy on Write[1]和Merge On Read[2]的设计,目前我正在进行Merge on Read模式的研发,之前根据社区Merge on Read的设计文档实现了一版的PoC,对整个架构会熟悉些,所以带大家聊一聊
Copy on Write模式
Copy no Write模式指的是在进行更新数据时,先将数据拷贝出来进行相应的更新,再替换掉原先的数据。得益于Iceberg的Overwrite
接口,Row-level delete 的copy on write模式实现起来比较简单,具体有如下步骤:
根据filter找到需要读取的文件,通过Iceberg的 FindFiles
类就可以:
filesToDel = FindFiles.in(table).withRecordsMatching(filter).collect()
将文件读出来对其中记录进行删除,例如,可以利用Spark DataFrame API通过上面一步的文件构建data frame,再根据filter进行过滤得到filesToAdd。 通过Iceberg的 Overwrite
接口写入:
val txn = table.newTransaction()val overwrite = txn.newOverwrite()filesToDel.map(overwrite.deleteFile)filesToAdd.map(overwrite.addFile)overwrite.commit()txn.commitTranscation()
Copy on Write模式的实现方式不需要太多的依赖也比较简单,社区并没有在代码仓库中实现,但是各大使用厂商都有自己的实现,例如苹果、鹅厂都有Copy on Write的实现。
Merge on Read模式
新的概念
为了实现基于Merge on Read的Row-level delete,需要引入如下概念:
delete file:(删除文件)描述了在读取数据时那些需要被删除的行的数据集, 它可以使用基于位置的数据集(position-based delete file)来描述,也可以使用基于值数据集(value-based delete file)来描述。
sequence number: (序列号)描述Iceberg文件的顺序数,序列号越小,生成该文件的时间越早。它决定了删除文件是否应该和对应的数据文件进行合并,当删除文件的序列号大于数据文件的序列号时,需要进行数据合并。
有了delete file
和sequence number
的就可以正确的读取出执行了row-level delete后的数据集。
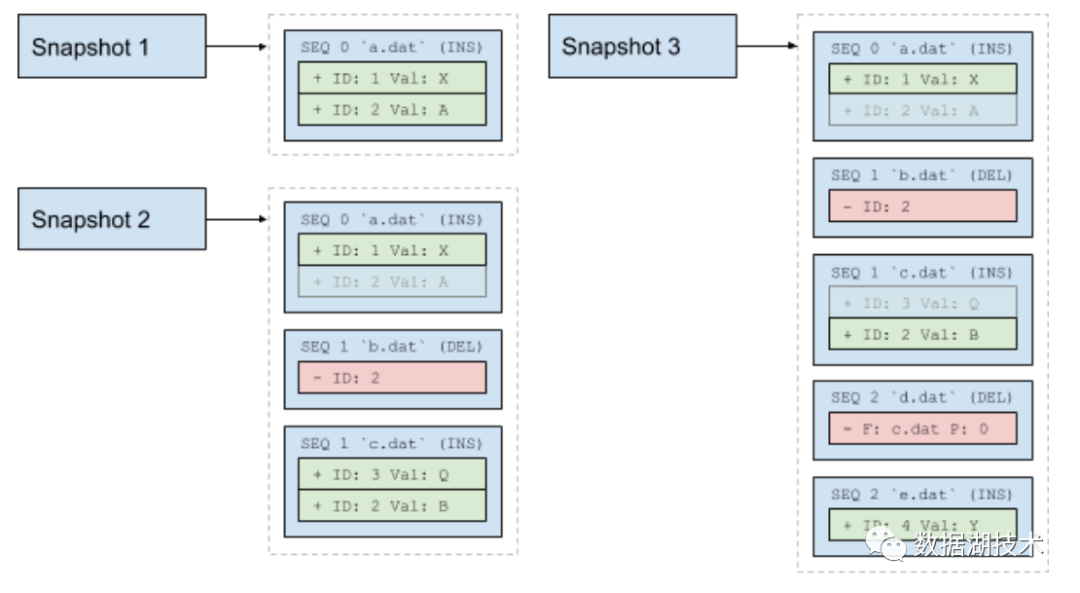
例如,在上图中的snapshot 2,b.dat是一个删除文件,因为它的序列号大于a.dat, 表示这个删除文件应该与数据文件a.dat进行合并,但是它的序列号小于数据文件c.dat的序列号,说明不用与c.dat进行合并,所以最后snapshot 2里面包含的数据是:{(1, X), (3, Q), (2, B)}
。
第二个例子是snapshot 3,这里包含了一个基于文件名和位置的删除文件,它的序列号大于数据文件a.dat和c.dat的序列号,表示最后的结果集需要和这两文件进行合并,所以最后snapshot 3的数据集是 {(1, X), (2, B), (4, Y)}
。
元数据改造
从Iceberg的Spec里可以看出,Iceberg表的元信息由三级元信息表示,Snapshot
, Manifest
, DataFile
。为了支持Merge On Read模式,必须对三个元信息进行一定的改造。
DataFile
DataFile
表示真实数据文件的结构体,需要扩展以下列:
sequence number (可选): 一个递增序列号,用来表示该文件被添加的顺序,如果一个数据文件的序列号小于一个待删数据集文件,那么在读取数据文件时需要合并待删数据集文件。file type(可选):表示该文件包含的数据是真正插入的数据还是待删数据集文件。
ManifestFile
ManifestFile
描述一个数据文件的集合,需要扩展以下属性:
minimum sequence number (可选): ManifestFile包含的数据文件的最小的序列号 sequence number : 当它包含数据文件没有序列号时,默认的序列号为该序列号。
Snapshot
Snapshot
包含了一个快照里Manifest文件的集合, 需要扩展如下属性:
maximum sequence number: 当前快照包含的文件里最大序列号
删除文件生成与写入
row-level delete的一个关键步骤是如何生成删除文件,目前社区在这块还没有太多的详细的设计,但是大致的方向是为表添加metadata column,然后在计算引擎侧根据表达式生成。我之前提出一个方案在Iceberg层面为表添加metadata column,但是Iceberg项目owner提出应该在计算引擎侧支持project metadata column的接口SupportsMetadataColumns
,然后由Iceberg去实现这个接口。他在Spark社区提了一个project metadata columns的PR:https://github.com/apache/spark/pull/28027。
删除文件Spec
目前社区上定义了position-based delete file, 它的schema如下:
| Field id, name | Type |
|---|---|
1 file_path | required string |
2 position | required long |
file_path
是Datafile中存储的path,position
是记录在文件的索引。需要注意的是,在写入删除文件的时候必须保证记录是根据file_path
和position
进行排序的,这样可以方便后续读取数据时进行基于merge sort的anti join. 同时一般情况下写入的delete file的格式和表的文件格式保持一致。
关于value-based delete file的schema还在讨论中,目前待定的方案如下:
| Field id, name | Type |
|---|---|
1 field_ids | required list<int> |
2 values | required list<binary> |
数据读取流程
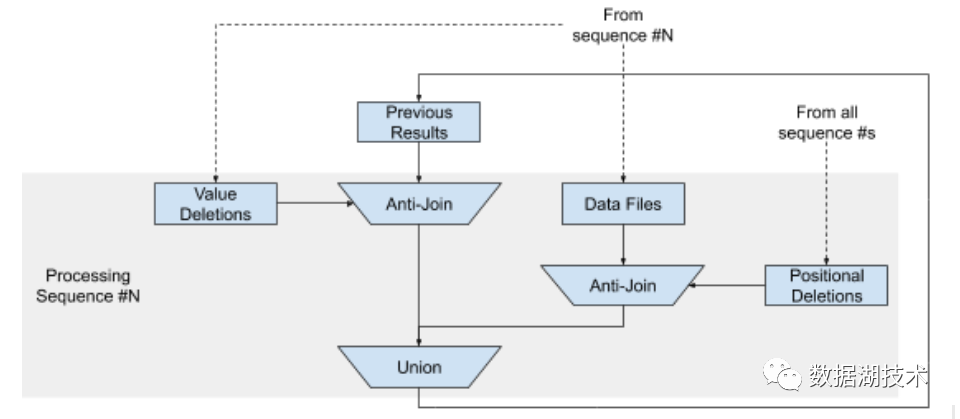
找到一个数据文件具有最小的序列号(seq0),任何小于该文件序列号的delete file都可以忽略
对于任意序列号为seq0的数据文件,过滤掉所有在 file and position based delete file中表示的行,并进行合并得到res0
对于后续每个大于seq0的序列号从小到大依次找到对应的data file 或者delete file:
a. 如果对应的是delete file, 就用之前的结果集与value based delete file进行anti join 得到res1
b. 如果对应的是data file, 用 file-position-based的delete文件过滤掉响应的记录得到res2
c. 合并res1和res2
任务计划生成
数据读取时一个重要的工作是如何生成负载均衡的并行任务避免数据倾斜,当前,Iceberg会根据用户设置的target split size, filter,以及一些权重信息等生成一个FileScanTask
的集合。而Row-level delete 添加了删除文件,那么就需要考虑到删除文件的读写代价,同时还需要考虑数据文件和删除文件做合并需要的消耗,目前社区暂时还没有定义如何根据这些代价生成任务。但是可以根据元信息进行一定的优化:
当进行3.a步骤时,我们可以根据manifest的最小序列号判断是否当前manifest里有data file需要与之合并 当进行与position-based delete file进行合并时,可以通过文件的low bound和upper bound进行过滤
合并数据文件和删除文件
如果是基于位置的删除文件,那么合并的算法是基于merge sort的anti join。
如果是基于值的删除文件,如果删除文件中的记录比较少,可以利用基于HashSet的anti join,但是如果记录比较多,可能会由一些其他服务转换成基于位置的删除文件进行处理。
社区进度
由于需要对元数据进行改造,社区升级了table spec的版本。当前社区正在积极地整合关于添加序列号的升级以及元信息变更带来的一些兼容性改动,包括同时支持v1 write path, v2 write path,删除文件读写,列的排序属性定义等事宜。
参考文献
[1]: Proposal: Iceberg Merge-on-Read [2]: Updates/Deletes/Upserts in Iceberg 欢迎关注我们公众号 
欢迎阅读Iceberg系列文章
