




SIMD 简介
众所周知,计算机程序需要编译成指令才能让 CPU 识别并执行运算。所以,CPU 指令处理数据的能力是衡量 CPU 性能的重要指标。
为了提高 CPU 指令处理数据的能力,半导体厂商在 CPU 中推出了一些可以同时并行处理多个数据的指令 —— SIMD[1] 指令。
SIMD 的全称是 Single Instruction Multiple Data,中文名“单指令多数据”。顾名思义,一条指令处理多个数据。
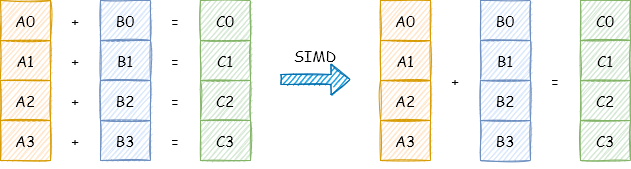 如上图所示:
如上图所示:
一个普通加法指令,一次只能对两个数执行一个加法操作。 一个 SIMD 加法指令,一次可以对两个数组(向量)执行加法操作。
SIMD 简史
经过多年的发展,支持 SIMD 的指令集有很多。各种 CPU 架构都提供各自的 SIMD 指令集,本文的介绍以 x86 架构为主。

1997 年,Intel 推出了第一个 SIMD 指令集 —— MultiMedia eXtensions(MMX)。MMX 指令主要使用的寄存器为 MM0 ~ MM7,大小为 64 位。
1999 年,Intel 在 Pentium III 对 SIMD 做了扩展,名为 Streaming SIMD eXtensions(SSE)。SSE 采用了独立的寄存器组 XMM0 ~ XMM7,64位模式下为 XMM0 ~ XMM15 ,并且这些寄存器的长度也增加到了 128 位。
2000 年,Intel 从 Pentium 4 开始引入 SSE2。
2004年,Intel 在 Pentium 4 Prescott 将 SIMD 指令集扩展到了 SSE3。
2006 年,Intel 发布 SSE4 指令集,并在 2007 年推出的 CPU 上实现。
2008 年,Intel 和 AMD 提出了 Advanced Vector eXtentions(AVX)。并于 2011 年分别在 Sandy Bridge 以及 Bulldozer 架构上提供支持。AVX 对 XMM 寄存器做了扩展,从原来的128 位扩展到了256 位。
2013年,Intel 在发布的 Haswell 处理器上开始支持AVX2。同年,Intel 提出了 AVX-512。
2016 年,Xeon Phi x200 (Knights Landing) 是第一款支持了 AVX-512 的 CPU。如扩展名所示,AVX-512 主要改进是把 SIMD 寄存器扩展到了 512 位。
如何使用 SIMD?
编译器自动向量化。
一些比较简单的场景,编译器可以自动将目标代码向量化(auto vectorization)。
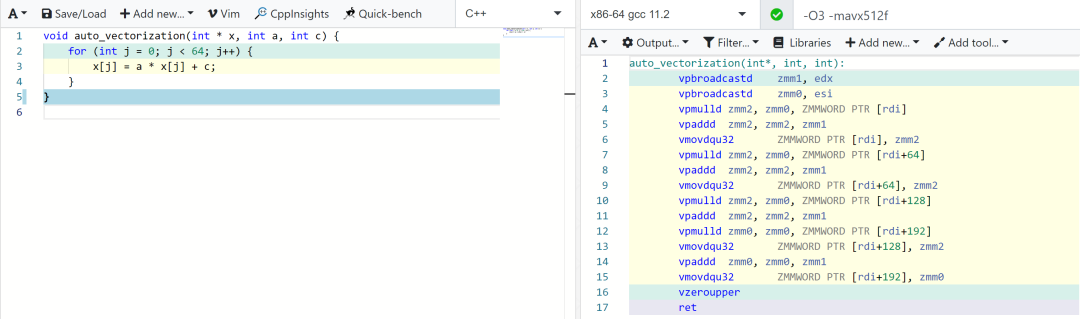
使用 GCC 可以通过 -S 参数,输出中间汇编文件,以检查是否自动将代码进行向量化了:
以 v 开头的指令,如 vpmulld、vpaddd、vmovdqu 都是向量化指令。 xmm、ymm、zmm 分别表示 128 位、256 位 和 512 位的向量化使用的寄存器。 本例中使用了 -mavx512f 编译选项要求编译器使用 AVX512,所以汇编代码使用的寄存器是 512 位的 zmm 系列。 本例中将数组 x 的长度固定为 64 个 int(512 位的倍数),是为了让实例生成的汇编代码更加简洁,不是向量化的强制要求。
编译器扩展的向量支持[2]。
让编译器进行自动向量化,其实有点“看运气”的成分。你可以使用编译器扩展的向量支持能力来实现向量化。如:
#include <iostream>
#include <string.h>
#include <string>
// v16si 表示 16 个 int 的向量(数组),长度为 64 字节
typedef int v16si __attribute__ ((vector_size (64)));
std::string toString(const v16si & v) {
std::string s = "[ ";
for (int i = 0; i < 16; i++) {
s += std::to_string(v[i]) + " ";
}
s += "]";
return s;
}
int main() {
v16si v0, v1;
memset(&v0, 0, sizeof(v0));
memset(&v1, 0, sizeof(v1));
std::cout << "v0: " << toString(v0) << std::endl;
std::cout << "v1: " << toString(v1) << std::endl;
v0 = v0 + 1; // v0 + {1, 1, ..., 1}
std::cout << "v0 = v0 + 1: " << toString(v0) << std::endl;
v1 = v1 + 2; // v1 + {2, 3, ..., 2}
std::cout << "v1 = v1 + 2: " << toString(v1) << std::endl;
v0 = v0 + v1;
std::cout << "v0 = v0 + v1: " << toString(v0) << std::endl;
v1 = v0 * v1;
std::cout << "v1 = v0 * v1: " << toString(v1) << std::endl;
v16si a = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};
v16si b = {0, 2, 4, 6, 8, 1, 3, 5, 7, 9, 10, 11, 12, 13, 14, 15};
// Vectors are compared element-wise producing 0 when comparison is false
// and -1 (constant of the appropriate type where all bits are set) otherwise.
auto c = a > b;
std::cout << "c = a > b: " << toString(c) << std::endl;
auto d = (a > b) ? v0 : v1;
std::cout << "d = (a > b) ? v0 : v1: " << toString(d) << std::endl;
return 0;
}
编译:g++ -o built-vec -mavx512f built-vec.cc
-mavx512f 表示使用 AVX512 指令集。如果 CPU 不支持 AVX512,可以使用其它 SIMD 指令集。相关编译选项有:-mmmx、-msse、-msse2、-msse3、-mssse3、-msse4.1、-msse4.2、-msse4、-mavx、-mavx2、-mavx512f、-mavx512pf、-mavx512er、-mavx512cd、-mavx512vl、-mavx512bw、-mavx512dq、-mavx512ifma、-mavx512vbmi。
指令封装
参考 The Intel Intrinsics Guide[3] 这里,主流的几个编译器 gcc、clang 和 msvc 都将 SIMD 指令封装成 C 函数,方便使用,具体可以参考官方文档。
参考资料
SIMD: https://en.wikipedia.org/wiki/SIMD
[2]扩展的向量支持: https://gcc.gnu.org/onlinedocs/gcc/Vector-Extensions.html
[3]The Intel Intrinsics Guide: https://software.intel.com/sites/landingpage/IntrinsicsGuide/
