




Etcd相关
Raft
主要看 http://thesecretlivesofdata.com/raft/ 这个里面的动画演示,看完就明白了,关注leader election 和 log replication 部分的内容
另外2个关键性问题:
日志复制的时候要求majority node都get到,这个majority包含不包含本身,与此同时结合2个node能不能组一个etcd集群来考虑
选举的时候term的概念了解下,然后关注下网络分裂的时候的情况,可以自己本地启个etcd集群试试,看看日志就明白了
日常维护问题
存储空间上限限制,-quota-backend-bytes配置,默认限制是2GB,最高上限为8GB,建议改大,否则会碰到Error: etcdserver: mvcc: database space exceeded的问题,这个之前在云翼有碰到,不知道后来弄了没
历史数据保留的问题 –auto-compaction-retention=1 只保留一个小时,否则还是存储空间的问题
日常的备份问题 etcdctl snapshot save backup.db
最重要的问题,etcd这个玩意和以前zookeeper一样,太稳定了,要么就不挂,挂了就不好(知道)恢复,日常多做做预案演练
Etcd的抢锁逻辑
etcd可以实现类似redis setnx的功能,这部分具体看看scheduler怎么用来抢锁的,在cmd/kube-scheduler中(不同版本路径不太一样自己找吧)leaderelection.RunOrDie 中,主要逻辑就是去拿锁,拿不到就间隔时间不断试,拿到就干活,顺道不断续锁,我本来还以为另外的会拿不到锁的时候watch下等通知呢,另外代码有点绕,只能看到是去创建了个endpoint,setnx的逻辑是写在了etcdhelper里面,所有的create的时候都是PrevExist: etcd.PrevNoExist
informer相关
单独列一个是因为k8s的组件获取数据都是用informer来实现到的,现在各种operator,底层最重要的东西也是informer。
informer的作用:一方面实现了一个apiserver的cache层,另外也实现了事件的回调,当你关注的资源add update delete的时候你都可以直接收到消息,方便你的开发。这个之前都是靠自己用http client去写的watch逻辑,后面还是直接用informer来开发,方便的多。
具体实现分析:
介绍见 https://www.kubernetes.org.cn/2693.html ,大体过程就是
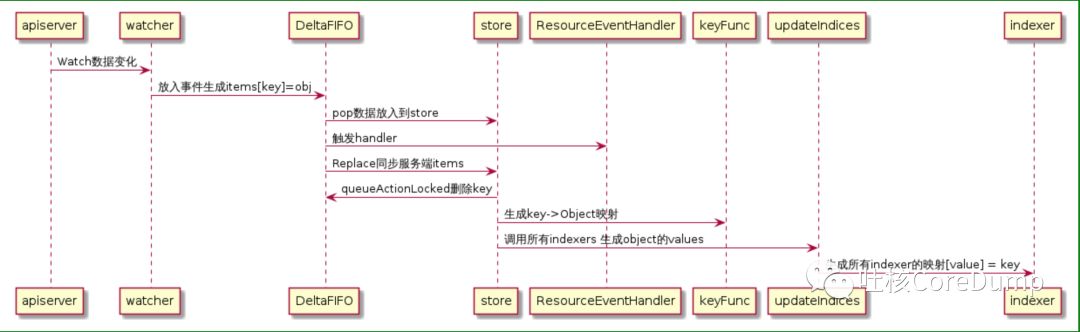
informer启动的时候通过reflector把所有数据丢到localStore中,然后reflector开始watch
watch的变更丢到了一个deltaFifo中,然后一方面pop数据到localStore中,另外一方面通知eventHandler去通知注册的func
apiserver相关
apiserver是etcd里面的数据对外的一个统一入口,这点要想下,为什么controller scheduler 不直接去访问etcd,早期的scheduler据徐总说就是直接访问etcd的哦
apiserver中几个关键东西,admission 未来可以作为自定义apiserver功能开发的一个很好的入口,不像现在好多定制修改直接都是代码相关地方改了,admission这里可以编译进去,也可以用admission webhook的方式来实现
apiserver 在一个大的集群中 99%的请求都是来自于configmap更新,所以慎用configmap,另外可以改造下,给configmap的默认改成不是实时更新的。不是远端更新了,pod那也就更新了,作为一个feature。这个问题当时在云翼考虑到configmap大小的问题(其实是etcd的限制),无意间避过了,JDOS这里定制修改了下。
适当调大apiserver的最大请求数值 max-requests-inflight max-mutating-requests-inflight (读和写最大请求,默认400,200) 其实没上面的问题正常就够了,建议改大
可以搭建多个apiserver来满足不同的需求,通过开启不同的admission的方案,我觉得不错,反正我是这么弄的
还有什么关注点,修改点?
scheduler相关
调度的主体逻辑要看下,predict priority preempt(可以忽略,毕竟在线服务不可能开这个功能)
predict中最主要地方是resourcePredict相关的以及nodeSelector或者nodeAffinity相关的,以及podAntiAffinity的required相关的,另外做了一个自定义的比较有意义的一个app在一个node上的上限限制
prority 最主要的2个,balanced_resource (通过算cpu和mem使用率差的绝对值来保证cpu mem消耗的都差不多,不要cpu用的过多,没有内存了),least_request(优先用机器空闲的机器),与此同时有个相对的most_requsest 不过这个没有启用,但是可以写个if else用来解决GPU资源碎片的问题,image_locality(废物策略,只有当镜像名一样的时候才有用,没有考虑层的信息),interpod_affanity 只用了prefered 让同APP尽量散开,同时predict那加限制,防止资源不足时又都落到一台机器上
scheduler这可能有什么性能问题,怎么优化,predict不要筛选过多的节点。能不能并行? 按pod hash 再一致性hash决定谁处理 ?
多scheduler 会不会有脑裂问题 ?官方修过一波,但原理上是不是还有可能 ? 为了和kube-batch一类的服务怎么并行 ?
调度器再看看有没有别的方案?除了k8s这种,mesos 怎么搞的? yarn怎么搞的? borg 怎么搞的?
controller相关
service的实现要看下,又是service controller 又是endpoint controller 各自干什么的
rc和deployment的区别是什么来着看下:
Replication Controller全部功能:Deployment继承了上面描述的Replication Controller全部功能。
事件和状态查看:可以查看Deployment的升级详细进度和状态。 kubectl rollout history ?
回滚:当升级pod镜像或者相关参数的时候发现问题,可以使用回滚操作回滚到上一个稳定的版本或者指定的版本。
版本记录: 每一次对Deployment的操作,都能保存下来,给予后续可能的回滚使用。
暂停和启动:对于每一次升级,都能够随时暂停和启动。
多种升级方案:Recreate:删除所有已存在的pod,重新创建新的; RollingUpdate:滚动升级,逐步替换的策略,同时滚动升级时,支持更多的附加参数,例如设置最大不可用pod数量,最小升级间隔时间等等。
deployment是怎么调整rs的副本数的,(maxUnavaliable 可以用来当并发度控制 maxSurge 可以用来加速上线,旧的没有停掉的情况下就可以拉新的起来)
rs里面可以修改下用来自定义上线顺序,以及添加暂停点的功能,这个之前写过
别的资源的controller好像基本都不用,先不用关注了,有个garbage controller要关注下,好几次都是新旧版本使用不一样,这个controller导致了问题
node挂了自动踢node上的pod的逻辑怎么优化下,要不要禁用掉,怎么禁用 ?禁用了,这个需求怎么解决
kubelet相关
和docker交互的逻辑,加的新restartPolicy的策略的原理
kubelet对pod的整体处理流程都过一遍
hosts的更新逻辑,这个之前碰到的坑,可以修改这里解决下
volume manager的逻辑 configmap secret flexvolumeplugin desireState ,再问问伟伟
cgroup的管理,主要那几个文件,功能和意义,这个之前貌似写过,另外能不能在线修改pod的request ?
容器间的cgroup namespace哪些是公用的,哪些不是
访问apiserver的参数配置,防止心跳请求被限速,node被认为unready,还是configmap的坑 kube-api-qps kube-api-burst
lifecycle 怎么实现的,http请求的,和脚本的,时间延迟的设计,重试的逻辑
eviction 和pleg 是干嘛的,里面的逻辑
GPU的管理,早期的版本,以及新的device-plugin
还有什么?
大规模集群问题
https://applatix.com/making-kubernetes-production-ready-part-2/
https://github.com/feiskyer/kubernetes-handbook/blob/master/practice/big-cluster.md
其他待续,更新到博客上,这里不更新
