





FastDFS是一款开源的轻量级的分布式文件系统,功能主要包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了文件大容量存储和高性能访问的问题。FastDFS特别适合以文件为载体的在线服务,如图片、视频、文档等等。FastDFS 专为互联网应用量身定做,解决大容量文件存储问题,追求高性能和高扩展性,它可以看做是基于文件的 key/value 存储系统,key 为文件 ID,value 为文件内容。
FastDFS架构:
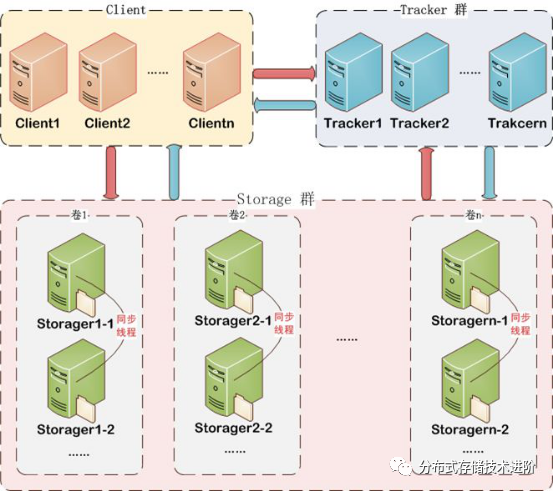
FastDFS有三个角色:跟踪服务器(tracker server)、存储服务器(storage server)和客户端(client)。
storage server:存储服务器(又称:存储节点或数据服务器),以组(卷,group或volume)为单位组织,一个group内包含多台storage机器,数据互为备份。文件和文件属性(meta data)都保存到存储服务器上。Storage server直接利用OS的文件系统调用管理文件。
storage接受到写文件请求时,会根据配置好的规则(后面会介绍),选择其中一个存储目录来存储文件。为了避免单个目录下的文件数太多,在storage第一次启动时,会在每个数据存储目录里创建2级子目录,每级256个,总共65536个子目录,新写的文件会以hash的方式被路由到其中某个子目录下,然后将文件数据直接作为一个本地文件存储到该目录中。
tracker server:跟踪服务器,主要做调度工作,起负载均衡的作用。负责管理所有的storaget server和group信息。
每个storage启动后连接到tracker, 告知自己所属的group的信息,并保持周期性的心跳上报,tracker根据storage的心跳信息,建立group==>[storage server list]的映射表。所有的tracker都接受stroage的心跳信息,生成group和storage server对应的映射表信息,在客户端进行读写时,提供给客户端存储服务节点的属组、IP等相关信息。相当于FastDFS的大脑,不论是上传还是下载都是通过tracker来分配存储服务器等资源。
client:客户端,作为业务请求的发起方。需要注意的是:
FastDFS不是通用的文件系统,只能通过专有API访问,目前提供了C、Java和PHP API, 实现了基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。
上传机制:
◆ 客户端先发送请求给Tracker服务,tracker经过对存储服务节点的筛选后,返回给客户端可以写入的存储服务节点的IP、端口号等信息;
(tracker选择存储服务节点的机制:先从所有的group中轮询,按照剩余空间多的优先的规则,选出其中一个group;然后轮询group中的存储节点,按一定的优先规则,选中最合适的storage server給客户端,注:优先级在storage上配置)
◆ 客户端拿到IP、端口后,向该存储服务器发出上传文件的请求;存储服务器收到请求后,先筛选出一个存储目录,再生成文件的fileid.
(storage server先为文件分配一个数据存储的目录,多个存储目录轮询,剩余空间多的优先; 选定存储目录之后,storage会为文件生一个Fileid,由storage server ip、文件创建时间、文件大小、文件crc32和一个随机数拼接而成)
◆ 存储服务器将文件内容写入磁盘并返回给客户端file_id、路径信息、文件名、文件索引信息FID等信息,客户端保存相关信息,上传完毕。
(当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。)
下载机制:
◆ 客户端发送带有文件名信息的请求到Tracker服务,获取存储服务器的ip地址和端口信息;
◆ 客户端根据返回的IP地址和端口号请求下载文件,存储服务器接收到请求后返回文件给客户端。
客户端发送download请求给某个tracker,必须带上文件名、文件索引FID等信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。由于group内的文件同步时在后台异步进行的,所以有可能出现在读到时候,文件还没有同步到某些storage server上,为了尽量避免访问到这样的storage,tracker根据一定的规则,优先选择源头storage, 并通过时间戳的机制做筛选。
文件索引FID中带了文件所在group组,tracker服务筛选后,选中最合适的storage server,提供给客户端。
客户端连接tracker返回的存储服务器,向存储服务器发出下载请求;
存储服务器根据“文件存储虚拟磁盘路径”和“数据文件两级目录”可以很快定位到文件所在目录,并根据文件名找到客户端需要访问的文件。
从FastDFS的整个设计看,基本是以简单为原则。比如以服务器为单位备份数据,简化了tracker的管理工作;storage直接借助本地文件系统原样存储文件,简化了storage的管理工作;文件写单份到storage即为成功、然后后台同步,简化了写文件流程。弱一致性模型,对存储硬件的配置要求要稍低,相对比较经济。
新版本对小文件合并做了优化,极大提升了存储空间的利用率。加上快速定位目标文件的方式,使得fastdfs在处理海量小文件时有很大的优势。
Tracker server作为中心结点,在内存中记录分组和Storage server的状态等信息,不记录文件索引信息,占用的内存量很少。不会成为系统瓶颈。
以group为单位组织存储能方便的进行应用隔离、负载均衡、副本数定制(group内storage server数量即为该group的副本数),比如将不同应用数据存到不同的group就能隔离应用数据。
另外还支持在线扩容机制,增强系统的可扩展性,主备Tracker服务,增强系统的可用性等特点。一个分组的存储服务器访问压力较大时,可以在该组增加存储服务器来扩充服务能力(纵向扩容)。当系统容量不足时,可以增加组来扩充存储容量(横向扩容)。
FastDFS主要的缺点个人理解主要集中在数据可靠性和接口通用性相对比较差。
写一份即成功:从源storage写完文件至同步到组内其他storage的时间窗口内,一旦源storage出现故障,就可能导致用户数据丢失,而数据的丢失对存储系统来说通常是不可接受的。
客户端只能通过FastDFS提供的专用API进行文件上传、下载等操作,不支持POSIX通用接口访问,通用性较低。
没有元数据的管理,并且客户端必须要存储服务端返回的文件名、FID等信息,必要的时候需要添加文件网关,实现文件索引查询等接口。
