




在数据库管理的日常工作中,我们经常会遇到数据库性能下降的问题。本文将围绕Halo数据库的性能优化展开,帮助读者理解常见性能问题的成因,并提供实用的解决建议。
数据库性能问题的常见原因
硬件资源不足:数据库服务器的CPU、内存、磁盘I/O等硬件资源不足是性能问题的常见原因。当硬件资源达到瓶颈时,数据库的性能会明显下降。
查询优化不足:复杂的查询语句、缺乏合适的索引、大量的子查询和联合查询等都可能导致查询性能下降。
并发连接过多:当数据库面临大量的并发连接时,如果连接池大小设置不当,可能导致性能下降。
锁争用:数据库中的锁争用也是一个常见的性能问题。锁争用可能导致事务执行延迟,从而影响数据库的整体性能。
其中锁的争用是日常业务中常见的问题。
锁存在的意义
每当多个会话同时访问数据库的同一数据时,理想状态是为所有的会话提供高效的访问,同时还要维护严格的数据一致性。这个数据的一致性通过什么来维护呢?
MVCC: 每个SQL语句看到的都只是当前事务开始的数据快照,而不是底层数据的当前状态。这样可以保护语句不会看到可能由其他相同数据行上执行更新的并发事务造成的不一致的数据,为每一个数据库会话提供事务隔离。MVCC避免了传统的数据库的锁定方法,将通过锁争夺最小化的方法来达到多会话并发访问时的性能最大化的目的。
Halo提供了多种锁模式用于控制对表中的数据的并发访问,其中最主要的是表级锁与行级锁,此外还有页及锁和咨询锁等等,接下来主要介绍表级锁与行级锁。
表级锁
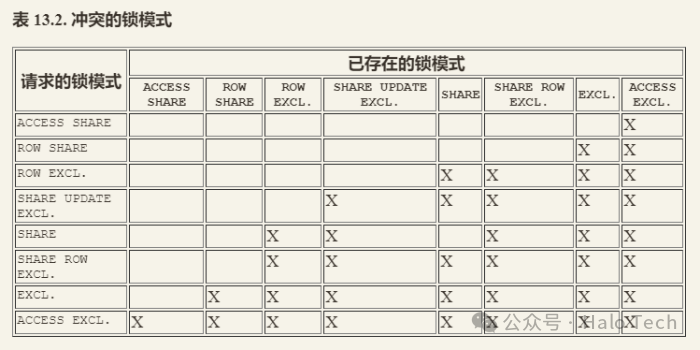
ACCESS SHARE :SELECT命令在被引用的表上获得一个这种模式的锁。通常,任何只读取表而不修改它的查询都将获得这种锁模式。
ROW SHARE:SELECT FOR UPDATE和SELECT FOR SHARE命令在目标表上取得一个这种模式的锁 (加上在被引用但没有选择FOR UPDATE/FOR SHARE的任何其他表上的ACCESS SHARE锁)。
ROW EXCLUSIVE:命令UPDATE、DELETE和INSERT在目标表上取得这种锁模式(加上在任何其他被引用表上的ACCESS SHARE锁)。通常,这种锁模式将被任何修改表中数据的命令取得。
SHARE UPDATE EXCLUSIVE:由VACUUM(不带FULL)、ANALYZE、 CREATE INDEX CONCURRENTLY、REINDEX CONCURRENTLY、 CREATE STATISTICS以及某些ALTER INDEX 和 ALTER TABLE的变体获得(详细内容请参考这些命令的文档)。
SHARE:由CREATE INDEX(不带CONCURRENTLY)取得。
SHARE ROW EXCLUSIVE:由CREATE TRIGGER和某些形式的 ALTER TABLE所获得。
EXCLUSIVE:由REFRESH MATERIALIZED VIEW CONCURRENTLY获得。
ACCESS EXCLUSIVE:由ALTER TABLE、DROP TABLE、TRUNCATE、REINDEX、CLUSTER、VACUUM FULL和REFRESH MATERIALIZED VIEW(不带CONCURRENTLY)命令获取。很多形式的ALTER INDEX和ALTER TABLE也在这个层面上获得锁(见ALTER TABLE(7))。这也是未显式指定模式的LOCK TABLE命令的默认锁模式。
表级锁一旦被获取,一个锁通常将被持有直到事务结束。但是如果在建立保存点之后才获得锁,那么在回滚到这个保存点的时候将立即释放该锁。这与ROLLBACK取消保存点之后所有的影响的原则保持一致。同样的原则也适用于在PL/pgSQL异常块中获得的锁:一个跳出块的错误将释放在块中获得的锁。
下表13.2冲突的锁模式
行级锁
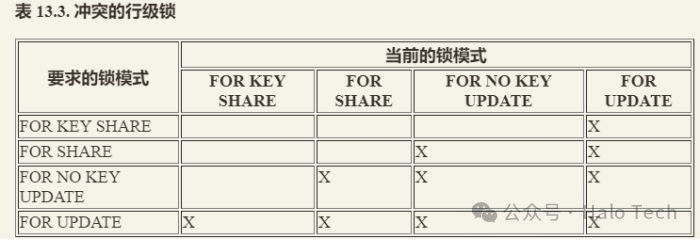
FOR UPDATE :FOR UPDATE会导致由SELECT语句检索到的行被锁定,就好像它们要被更新。这可以阻止它们被其他事务锁定、修改或者删除,一直到当前事务结束。也就是说其他尝试UPDATE、DELETE、SELECT FOR UPDATE、SELECT FOR NO KEY UPDATE、SELECT FOR SHARE或者SELECT FOR KEY SHARE这些行的事务将被阻塞,直到当前事务结束。反过来,SELECT FOR UPDATE将等待已经在相同行上运行以上这些命令的并发事务,并且接着锁定并且返回被更新的行(或者没有行,因为行可能已被删除)。
FOR NO KEY UPDATE:行为与FOR UPDATE类似,不过获得的锁较弱:这种锁将不会阻塞尝试在相同行上获得锁的SELECT FOR KEY SHARE命令。任何不获取FOR UPDATE锁的UPDATE也会获得这种锁模式
FOR SHARE:行为与FOR NO KEY UPDATE类似,不过它在每个检索到的行上获得一个共享锁而不是排他锁。一个共享锁会阻塞其他事务在这些行上执行UPDATE、DELETE、SELECT FOR UPDATE或者SELECT FOR NO KEY UPDATE,但是它不会阻止它们执行SELECT FOR SHARE或者SELECT FOR KEY SHARE。
FOR KEY SHARE:行为与FOR SHARE类似,不过锁较弱:SELECT FOR UPDATE会被阻塞,但是SELECT FOR NO KEY UPDATE不会被阻塞。一个键共享锁会阻塞其他事务执行修改键值的DELETE或者UPDATE,但不会阻塞其他UPDATE,也不会阻止SELECT FOR NO KEY UPDATE、SELECT FOR SHARE或者SELECT FOR KEY SHARE。
Halo不会在内存里保存任何关于已修改行的信息,因此对一次锁定的行数没有限制。不过,锁住一行会导致一次磁盘写,例如, SELECT FOR UPDATE将修改选中的行以标记它们被锁住,并且因此会导致磁盘写入。
下表13.3是冲突的行级锁。
问题诊断与解决建议
查看锁情况:使用以下SQL语句可以查看当前数据库中的锁情况:
SELECT a.locktype, a.database, a.pid, a.mode, a.relation, b.relname FROM pg_locks a JOIN pg_class b ON a.relation = b.oid WHERE upper(b.relname) = 'YOUR_TABLE_NAME';
通过查看锁情况,我们可以了解哪些事务正在等待锁,从而定位锁争用的源头。
如果不是锁的问题,也可以看看系统占用&CPU排名前10的进程、这个指令也可以看看关于halo 用户的高占用进程,查到pid
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
查找锁对应的SQL语句:根据上面查出的pid,使用以下SQL语句可以查找锁对应的SQL语句:
SELECT procpid, START, now() - START AS lap, current_query FROM (SELECT backendid, pg_stat_get_backend_pid (S.backendid) AS procpid,pg_stat_get_backend_activity_start (S.backendid) AS START,pg_stat_get_backend_activity (S.backendid) AS current_queryFROM (SELECT pg_stat_get_backend_idset () AS backendid) AS S) AS SWHERE current_query <> '<IDLE>' and procpid='YOUR_PID'ORDER BY lap DESC;
要快速解出这种状态,terminate最大的锁对应的PID即可。也是一种可行的方法
select pg_terminate_backend(23043);
通过查看锁对应的SQL语句,我们可以了解锁争用的原因,从而针对性地优化查询语句或事务逻辑。
查询优化:针对查询性能问题,我们可以通过优化查询语句、添加合适的索引、避免使用大量的子查询和联合查询等方式来提高查询性能。同时,调整PostgreSQL的配置参数,如shared_buffers、work_mem、effective_cache_size等,也可以帮助提高数据库性能。
调整并发连接:针对并发连接过多的问题,我们可以通过调整数据库连接池的大小来平衡并发连接和数据库性能之间的关系。使用连接池可以避免频繁地创建和销毁数据库连接,从而提高数据库性能。
优化事务隔离级别:针对锁争用问题,我们可以通过优化事务隔离级别或调整锁等待时间来减少锁争用。例如,将事务隔离级别从可重复读(REPEATABLE READ)调整为读已提交(READ COMMITTED)可以减少锁争用。
总结
Halo数据库性能优化是一个持续的过程,需要不断地进行问题诊断和优化调整。通过理解常见性能问题的成因和采取相应的解决建议,能持续提高数据性能和稳定性。读者们如果在日常中遇到什么问题,希望能对我们的产品多多提问。
