




陈旭,捷银消费金融有限公司DBA
既第一篇 实战PG vector构建DBA个人知识库之一:基础环境搭建以及大模型部署 ,第二篇实战PG vector 构建DBA 个人知识库之二: 向量数据库与 PG vector 介绍 之后,
今天分享的是本系列之三: LLM+LangChain+pgvector 整合篇。
在之前的篇幅中我们完成了:
1.Llama3-Chinese 版本私有化搭建和部署已经查询API的发布
2.Embedding text2vec-base-chinese 模型的调用:文字生成向量
3.pg vector 向量数据库的安装和插入查询测试
本篇将之前的项目输出整合起来完成一个RAG的项目: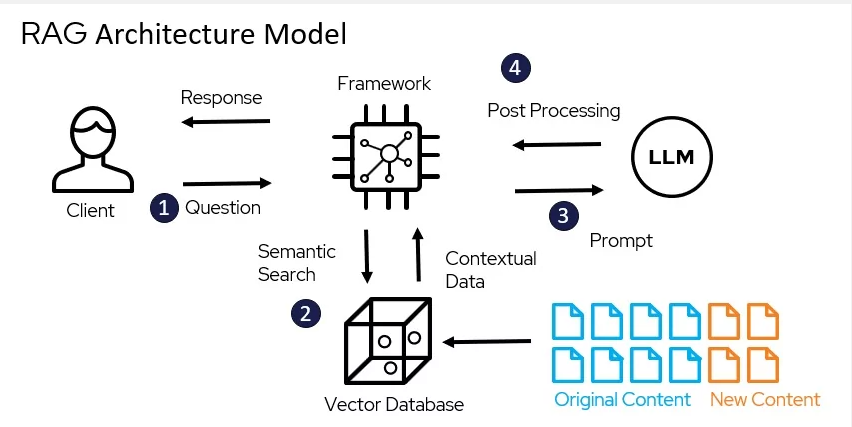
关于RAG的定义:
RAG is an AI Framework that integrates large language models (LLMs) with external knowledge retrieval to enhance accuracy and transparency.
Pre-trained language models generate text based on patterns in their training data.
RAG supplements their capabilities by retrieving relevant facts from constantly updated knowledge bases
我们看到了RAG定义中的几个关键词:AI 框架, 整合外部知识, 支持即时更新的知识库。
我们看到图中的 Original/New Connect 类似于我们的外部数据(像我们日常写的博客,笔记,邮件,电子书什么的),向量数据库Vector database 类似于存储我们外部知识的数据库:
市面上常见的向量数据库有很多种:对于DBA比较熟悉的mongo,es,pg 等等都对向量数据库有支持,图中的LLM就是我们之前搭建的大模型,最后我们可以看到Framework 在这架构图中
站在了C位,起到了整合RAG架构的核心地位。
关于Framework 我们选择 langchain, 关于langchain的定义:
LangChain is a framework for developing applications powered by large language models (LLMs).
LangChain simplifies every stage of the LLM application lifecycle:
Development: Build your applications using LangChain’s open-source building blocks and components. Hit the ground running using third-party integrations and Templates.
Productionization: Use LangSmith to inspect, monitor and evaluate your chains, so that you can continuously optimize and deploy with confidence.
Deployment: Turn any chain into an API with LangServe.
简单地说就是大模型的一个开发框架,支持开发,持续优化,部署发布API等功能。
关于 langchain 对于 pgvector 的支持: https://python.langchain.com/v0.1/docs/integrations/vectorstores/pgvector/
我们来按照官方的例子运行一下demo:
1)安装LangChain相关的package
pip3 install langchain_core
pip3 install langchain_postgres
pip3 install psycopg-c
pip3 install langchain-community
pip3 install sentence-transformers
2)我们准备一下基础数据测试数据集:
docs = [
Document(
page_content="2024年欧洲杯的冠军是西班牙队",
metadata={"id": 1, "catalog": "sports", "topic": "CCTV-足球体育新闻"},
),
Document(
page_content="2023-2024年NBA的总冠军是波士顿凯尔特人队",
metadata={"id": 2, "catalog": "sports", "topic": "CNN-篮球体育新闻"},
),
Document(
page_content="2024年9月份postgres会发布version17版本,含有大量新的功能",
metadata={"id": 3, "catalog": "tech", "topic": "开源数据库社区"},
),
Document(
page_content="2024年ORACLE发布了跨时代意义的数据库版本ORACLE 23AI,支持多模数据库,支持向量数据库",
metadata={"id": 4, "catalog": "tech", "topic": "甲骨文频道"},
),
]
3)测试程序load 数据:
from langchain_core.documents import Document
from langchain_postgres import PGVector
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_postgres.vectorstores import PGVector
# See docker command above to launch a postgres instance with pgvector enabled.
connection = "postgresql+psycopg://app_vector:app_vector@xx.xx.xxx.xxx:5432/postgres" # Uses psycopg3!
collection_name = "t_news"
embeddings = HuggingFaceEmbeddings(model_name='D:\\AI\\text2vec-base-chinese')
vectorstore = PGVector(
embeddings=embeddings,
collection_name="t_news",
connection=connection,
use_jsonb=True,
)
docs = [
...
]
print(vectorstore)
##vectorstore.(docs, ids=[doc.metadata["id"] for doc in docs])
vectorstore.add_documents(docs, ids=[doc.metadata["id"] for doc in docs])
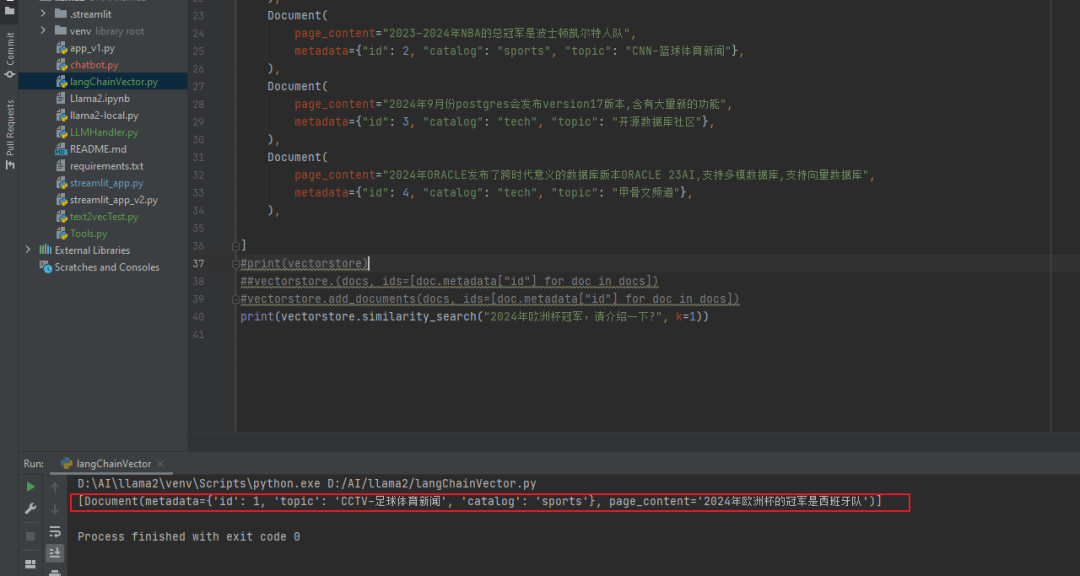
4)测试相似度检索:2024年欧洲杯冠军,请介绍一下?
vectorstore.similarity_search("2024年欧洲杯冠军,请介绍一下?", k=1)
我们可以看到embedding 模型给了我们正确的答案。
5)整合大模型接口调用:
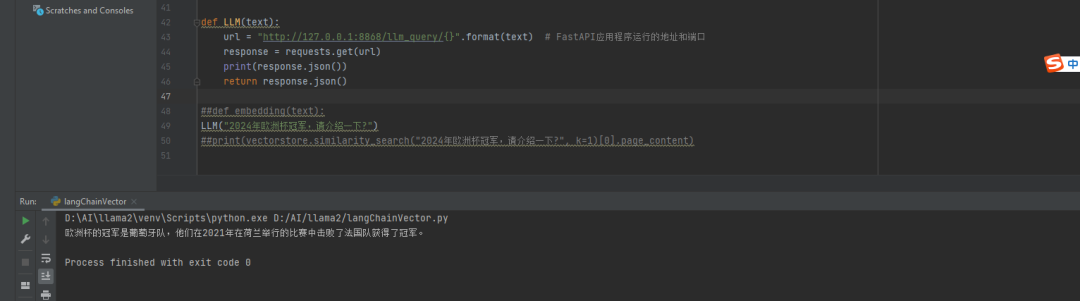
首先我们只是单纯的直接调用大模型接口,感觉他是在胡天!!!
“欧洲杯的冠军是葡萄牙队,他们在2021年在荷兰举行的比赛中击败了法国队获得了冠军。“
葡萄牙应该是2016年拿的欧洲杯冠军!!对手到是法国队。
def LLM(text):
url = "http://127.0.0.1:8868/llm_query/{}".format(text) # FastAPI应用程序运行的地址和端口
response = requests.get(url)
print(response.json())
return response.json()
##def embedding(text):
LLM("2024年欧洲杯冠军,请介绍一下?")
我们通过RAG增强式检索:
def LLM(text):
url = "http://127.0.0.1:8868/llm_query/{}".format(text) # FastAPI应用程序运行的地址和端口
response = requests.get(url)
# print(response.json())
return response.json()
def embedding(text):
return vectorstore.similarity_search(text, k=1)[0].page_content
def RAG(text):
msg = embedding(text)
print(msg)
return LLM(""""{},问题是:{}""".format(msg,text))
if "__main__" ==__name__:
print(RAG("2024年欧洲杯冠军,请介绍一下这个国家?例如这个国家人口,面积,气候"))
大模型给我们的答案:相对于合理的回答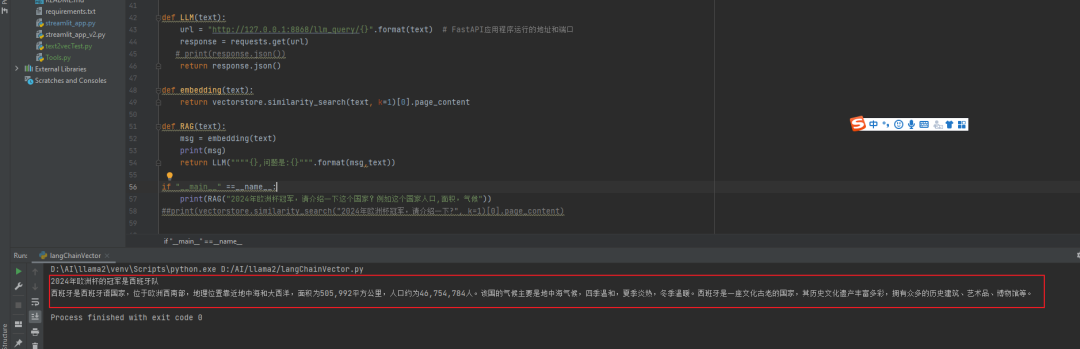
最后我们看一下 langchain 与 pg_vector 的自动整合下的数据库表的呈现:
我们发现langchain 框架会自动创建2张表 langchain_pg_collection和langchain_pg_embedding,
postgres=> \dt
List of relations
Schema | Name | Type | Owner
------------+-------------------------+-------+------------
app_vector | langchain_pg_collection | table | app_vector
app_vector | langchain_pg_embedding | table | app_vector
(5 rows)
postgres=> \d+ langchain_pg_collection
Table "app_vector.langchain_pg_collection"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
-----------+-------------------+-----------+----------+---------+----------+-------------+--------------+-------------
uuid | uuid | | not null | | plain | | |
name | character varying | | not null | | extended | | |
cmetadata | json | | | | extended | | |
Indexes:
"langchain_pg_collection_pkey" PRIMARY KEY, btree (uuid)
"langchain_pg_collection_name_key" UNIQUE CONSTRAINT, btree (name)
Referenced by:
TABLE "langchain_pg_embedding" CONSTRAINT "langchain_pg_embedding_collection_id_fkey" FOREIGN KEY (collection_id) REFERENCES langchain_pg_collection(uuid) ON DELETE CASCADE
Access method: heap
postgres=> \d+ langchain_pg_embedding
Table "app_vector.langchain_pg_embedding"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
---------------+-------------------+-----------+----------+---------+----------+-------------+--------------+-------------
id | character varying | | not null | | extended | | |
collection_id | uuid | | | | plain | | |
embedding | vector | | | | external | | |
document | character varying | | | | extended | | |
cmetadata | jsonb | | | | extended | | |
Indexes:
"langchain_pg_embedding_pkey" PRIMARY KEY, btree (id)
"ix_cmetadata_gin" gin (cmetadata jsonb_path_ops)
"ix_langchain_pg_embedding_id" UNIQUE, btree (id)
Foreign-key constraints:
"langchain_pg_embedding_collection_id_fkey" FOREIGN KEY (collection_id) REFERENCES langchain_pg_collection(uuid) ON DELETE CASCADE
Access method: heap
langchain_pg_collection 是主表记录了向量表的名字:
postgres=> select * from langchain_pg_collection;
uuid | name | cmetadata
--------------------------------------+--------+-----------
17e8df97-5db8-442f-8f49-ea6e71231802 | t_news | null
(1 row)
langchain_pg_embedding是子表记录了向量的信息:
postgres=> select count(1) from langchain_pg_embedding;
count
-------
4
(1 row)
postgres=> select * from langchain_pg_embedding;
id | collection_id |
1 | 17e8df97-5db8-442f-8f49-ea6e71231802 | [-1.3334022,0.9337577,-0.3636402,-0.053306933,0.0846217,-0.08087579,0.7735808,-0.06978625,-0.14796568,0.54863155,0.7147292,0.6
444973,-0.4289818,-0.64992523,-2.0558815,-0.09939844,0.06320713,1.2094835,0.42997867,-0.045221683,-0.74566567,0.9688923,-0.32088393,0.5072144,-0.2132386,-0.38068974,-0.063
253194,-0.5553703,-0.13070923,0.032516792,0.19199787,-0.35632166,-1.0873616,-0.1506536,0.058472667,1.0499889,-0.08423612,-0.17433228,0.771671,-0.48466313,0.57933533,2.0371
673,0.35173145,0.81162024,-0.39255375,0.90436745,0.009064911,0.2791657,-1.1032667,0.8461039,-0.78653026,0.8507371,-0.64681536,0.95859784,0.6849843,0.53893226,0.77747756,0.
0801601,0.17333724,-0.37513876,-1.2156097,0.27867568,-0.92160845,-0.5047081,0.432022,-0.13728906,-0.24497142,-0.5689873,-0.1558505,-1.9338208,-0.35952917,-0.24267699,0.268
40404,-0.17570858,1.3977934,0.3286393,0.47039926,-0.5733993,0.58036995,-0.6639077,0.19822633,-1.0455183,0.115738526,-0.49547425,-0.7333636,-0.61310935,0.3633987,0.1452295,
这里需要注意:默认langchain 自动生成的表的vector column列并没有索引,我们可以手动创建一下hnsw类型的索引:
postgres=> CREATE INDEX ON langchain_pg_embedding USING hnsw (embedding vector_cosine_ops);
ERROR: column does not have dimensions
这个索引错误是因为你在初始化向量的过程中没有指定向量的长度导致的
由于初始化函数中没有指定 vector 的长度,导致生成的表也是没有长度限制的

生成的表:langchain_pg_embedding
postgres=> \d+ langchain_pg_embedding
Table "app_vector.langchain_pg_embedding"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
---------------+-------------------+-----------+----------+---------+----------+-------------+--------------+-------------
id | character varying | | not null | | extended | | |
collection_id | uuid | | | | plain | | |
embedding | vector | | | | external | | |
document | character varying | | | | extended | | |
cmetadata | jsonb | | | | extended | | |
查看langchain 代码:构造函数中是支持传入vector长度的入参:embedding_length
vectorstore = PGVector(
embeddings=embeddings,
collection_name="t_news_2",
embedding_length =768,
connection=connection,
use_jsonb=True,
)
我们运行程序重新生成一下表:vectorstore.drop_tables() 是删除已存在的表
vectorstore.drop_tables()
vectorstore.add_documents(docs, ids=[doc.metadata["id"] for doc in docs])
再次验证vector的长度: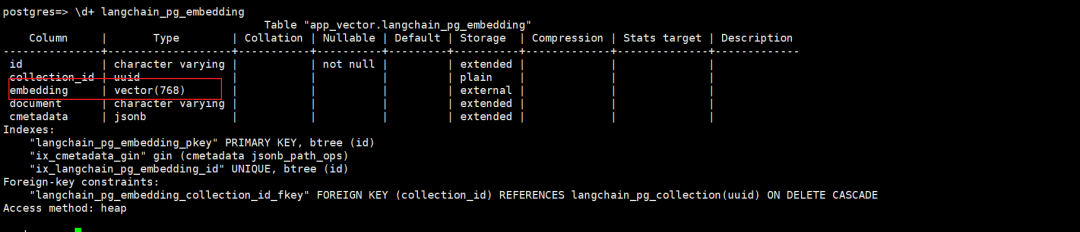
这回索引可以成功创建了:
postgres=> CREATE INDEX ON langchain_pg_embedding USING hnsw (embedding vector_cosine_ops);
CREATE INDEX
查看langchain 自动生成SQL的执行计划:我们看到了触发了我们之前创建的索引Index Scan using langchain_pg_embedding_embedding_idx on langchain_pg_embedding
explain analyze SELECT langchain_pg_embedding.id AS langchain_pg_embedding_id, langchain_pg_embedding.collection_id AS langchain_pg_embedding_collection_id,
langchain_pg_embedding.embedding AS langchain_pg_embedding_embedding, langchain_pg_embedding.document AS langchain_pg_embedding_document,
langchain_pg_embedding.cmetadata AS langchain_pg_embedding_cmetadata, langchain_pg_embedding.embedding <=>
'[-0.77009904,1.1517035,...]'
AS distance
FROM langchain_pg_embedding JOIN langchain_pg_collection ON langchain_pg_embedding.collection_id = langchain_pg_collection.uuid
WHERE langchain_pg_embedding.collection_id = 'a9112e1a-ec73-4742-9d88-806c09c525b4' ORDER BY distance ASC
LIMIT 1;
Limit (cost=12.18..24.26 rows=1 width=152) (actual time=0.164..0.165 rows=1 loops=1)
-> Nested Loop (cost=12.18..24.26 rows=1 width=152) (actual time=0.164..0.164 rows=1 loops=1)
-> Index Scan using langchain_pg_embedding_embedding_idx on langchain_pg_embedding (cost=12.03..16.08 rows=1 width=144) (actual time=0.148..0.149 rows=1 loops=1
)
Order By: (embedding <=> '[-0.77009904,1.1517035,-0.14216383,-0.7595568,...]'::vector)
Filter: (collection_id = 'a9112e1a-ec73-4742-9d88-806c09c525b4'::uuid)
-> Index Only Scan using langchain_pg_collection_pkey on langchain_pg_collection (cost=0.15..8.17 rows=1 width=16) (actual time=0.005..0.005 rows=1 loops=1)
Index Cond: (uuid = 'a9112e1a-ec73-4742-9d88-806c09c525b4'::uuid)
Heap Fetches: 1
Planning Time: 0.116 ms
Execution Time: 0.622 ms
(10 rows)
最后我们总结一下:
1.Langchain 是一个整合AI大模型调用和本地embedding 向量写入整合的一个AI开发框架,可以帮我们快速实现RAG的开发
2.langchain 和 pgvector 整合的时候,需要注意初始化pgvector 对象的时候,要制定embedding 的长度,否则自动创建的表vector是没有长度限制的,
导致不能创建索引的错误:ERROR: column does not have dimensions
Have a fun 🙂 !


