




 在本系列的前两篇文章中,我们分别将 MyScale 与流行的专用向量数据库 Pinecone 和 Zilliz 进行了对比,本文将继续对比 MyScale 与 Qdrant。
在本系列的前两篇文章中,我们分别将 MyScale 与流行的专用向量数据库 Pinecone 和 Zilliz 进行了对比,本文将继续对比 MyScale 与 Qdrant。
01
Qdrant 简介
Qdrant 是一款开源的向量数据库,可以在 Docker 和云端运行。Qdrant 具有如下特点:
高级压缩技术:Qdrant 使用二进制量化技术,将任何数值向量嵌入转换为布尔值向量,提升了多达 40 倍的搜索性能。
多租户支持:单个集合中的基于负载的分区称为多租户。Qdrant 支持多用户共享实例。
I/O Uring:Qdrant 支持 io_uring 技术,提升了吞吐量,缓解了操作系统系统调用的开销。
02
托管灵活性
在选择数据库解决方案时,考虑托管服务至关重要,它对数据库的性能、扩展能力和管理便捷性有显著影响。优秀的托管服务可以保证数据库平稳应对工作负载变化,确保服务的高可用性,并简化管理工作。
在托管方面,MyScaleDB 和 Qdrant 都提供开源版本、云端解决方案以及本地部署方案。云托管包括免费和付费等级,接下来我们将详细介绍这些选项。
云托管
MyScaleDB 的云托管服务有多种可选方案,用户可以从支持 500 万 768 维向量的免费 Pod 开始。
Qdrant 提供一个 1GB 的永久免费集群,无需任何前期费用。
本地部署
对于本地解决方案,Docker 镜像是一个常见的选项。我们可以通过以下方式启动 MyScaleDB Docker 镜像:
docker run --name MyScaleDB --net=host MyScaleDB/MyScaleDB:1.6
然后使用 ClickHouse 客户端连接到数据库:
docker exec -it MyScaleDBdb clickhouse-client
同样,Qdrant 也可以使用 Docker 本地运行:
docker run -p 6333:6333 qdrant/qdrant
02
核心功能
虽然托管选项为数据库的可访问性和可扩展性奠定了基础,但真正区分 MyScaleDB 和 Qdrant 的是核心功能。我们将深入探讨这两个平台的功能特点,以便用户更好地理解它们是如何处理复杂的向量数据操作的。
查询语言和 API 支持
Qdrant:Qdrant 拥有广泛的多语言支持,为开发者提供了 Python、Java、Go、.Net、Rust 和 TypeScript/JavaScript 的 SDK。这种广泛的语言支持确保了与各种技术栈的无缝集成。
MyScaleDB:MyScaleDB 提供了 Python、Java、Go 和 Node.JS 的 SDK,支持主流编程语言。
尽管两者都提供了广泛的多语言支持,MyScaleDB 因其对 SQL 的独特支持而脱颖而出。用户可以使用传统的 SQL 查询与 MyScaleDB 交互,它可以无缝处理向量数据库,甚至可以与传统数据库结合使用,例如:
SELECT id, date, label,distance(data, {target_row_data}) AS distFROM default.myscale_searchORDER BY dist LIMIT 10
MyScaleDB 中的 distance 方法通过测量指定向量与存储在特定列中的所有向量之间的距离来计算向量相似度。
支持的数据类型
处理多样化的数据类型是任何数据库的必要功能,向量数据库也不例外。我们来比较一下 MyScaleDB 和 Qdrant 在数据类型支持方面的表现。
Qdrant 利用 JSON 有效负载的灵活性,允许存储和查询多种数据类型,包括:
关键词:用于基于文本的搜索和过滤。
整数和浮点数:用于数值数据和范围查询。
嵌套对象和数组:用于表示复杂的数据结构。
这种以 JSON 为中心的方式提供了数据建模的灵活性,适用于各种用例。
MyScaleDB 通过利用其完整的 SQL 兼容性,将数据类型支持提升到了一个新的层次。它不仅能管理向量数据,还能处理广泛的传统数据类型,包括:
结构化数据:传统的关系数据类型,如整数、浮点数、字符串、日期等。
JSON:用于处理半结构化数据和嵌套对象。
地理空间数据:用于基于位置的查询和空间分析。
时间序列数据:用于存储和分析时间戳数据。
MyScaleDB 能够在单个平台内处理向量数据和多种传统数据类型,这一优势显著简化了数据管理过程,消除了数据孤岛,并允许用户跨数据类型进行复杂查询。
以下是一个示例表,展示了 MyScaleDB 可以管理的多样化列,包括向量数据:
CREATE TABLE default.wiki_abstract_mini(`id` UInt64,`body` String,`title` String,`url` String,`body_vector` Array(Float32),CONSTRAINT check_length CHECK length(body_vector) = 768)ENGINE = MergeTreeORDER BY idSETTINGS index_granularity = 128;
这个 SQL 命令创建了一个表,包含结构化和向量化数据,强制 body_vector 的大小为 768,并通过按 id 排序来优化查询。
TL:DR:两者都有效支持多种数值和文本数据类型,但 MyScaleDB 通过其高级 SQL 兼容性、强大的 OLAP 功能和对复杂数据结构(如地理空间和时间序列数据)的全面支持,将这一能力提升到了一个新的高度。
索引
Qdrant 使用 HNSW 索引算法,尽管在标准向量搜索中有效,但在过滤搜索操作中表现较弱。
MyScaleDB 通过引入 多尺度树图(MSTG) 算法解决了这一限制。MSTG 结合了层次树聚类和基于图的搜索,显著提高了检索速度和性能,使其在标准和复杂的过滤向量搜索操作中都能高效运行。
同时,MyScaleDB 和 Qdrant 也都支持多向量搜索。
全文搜索
全文搜索 是 Qdrant(从 0.10.0 版本开始)和 MyScaleDB 都支持的功能。

Qdrant 通过支持文本字段的分词和索引实现全文搜索,允许根据特定词语或短语进行搜索和过滤。
from qdrant_client import QdrantClient, modelsclient = QdrantClient(url="<http://localhost:6333>")client.create_payload_index(collection_name="{collection_name}",field_name="name_of_the_field_to_index",field_schema=models.TextIndexParams(type="text",tokenizer=models.TokenizerType.WORD,min_token_len=2,max_token_len=15,lowercase=True,),)
MyScaleDB 使用 Tantivy 库,该库利用 BM25 算法进行准确高效的文档检索。在 MyScaleDB 示例中,我们使用了带有英语停用词的 `stem` 分词器,它可以通过关注词的词根形式来提高搜索精度。这里我们使用了 en_wiki_abstract 表。
ALTER TABLE default.en_wiki_abstractADD INDEX body_idx (body)TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}')GRANULARITY 64;
这个命令在 en_wiki_abstract 表中的 body 列上创建了一个全文搜索索引。
TL:DR:两者都支持全文搜索,但 MyScaleDB 具备 BM25 算法和 SQL 支持,在检索文档的准确性和效率方面稍占优势。
过滤搜索
MyScaleDB 通过其 MSTG 算法及位掩码技术优化了过滤向量搜索。这一组合,再加上 ClickHouse 的高级索引和并行处理能力,使 MyScaleDB 能够高效处理大型数据集。通过采用预过滤策略,MyScaleDB 在主要的向量搜索之前缩小数据集的范围,确保只处理最相关的数据,大大提升了性能和准确性。
Qdrant 使用可过滤的 HNSW 算法,在搜索过程中应用过滤器,确保只考虑搜索图中相关的节点。
地理搜索
MyScaleDB 和 Qdrant 都支持地理搜索。MyScaleDB 提供了多个地理空间功能来支持地理搜索。例如,以下函数用于计算地球上两个点之间的距离(作为一个流形处理):
greatCircleDistance(lon1Deg, lat1Deg, lon2Deg, lat2Deg)
大语言模型 API 集成
向量搜索最大的应用场景就是大语言模型(LLM)和检索增强生成(RAG)。Qdrant 和 MyScaleDB 都支持多种 LLM API 的集成,如 LlamaIndex、LangChain 和 Hugging Face。
03
定价
Qdrant 和 MyScaleDB 都采用了免费增值的定价模式,提供适用于实验和小型项目的免费版,以及为高需求工作负载设计的付费版。两者都允许用户在无需绑卡的情况下探索其免费服务。
免费方案
Qdrant:在免费方案中提供 1GB 的存储容量。
MyScaleDB:提供跨级别的免费额度,允许存储高达 500 万个 768 维向量。相比之下,在 Qdrant 平台上达到这个存储容量将需要选择大约 275 美元/月。
付费方案
在付费方案方面,Qdrant 提供了三种云托管类型:GCP、Azure 和 AWS。
我们将比较 Qdrant 的 GCP 托管和 MyScaleDB 的付费方案,使用相同的 768 维向量来进行对比。
在 MyScaleDB 的容量型 Pods 中,每个 Pod 可存储 1000 万个向量,而性能优化设置则可以提供更低的延迟,因此也需要更多的 Pods 来存储数据。我们可以看到即使是 MyScaleDB 的性能优化 Pods,其价格也远低于 Qdrant 最经济的设置。
另一个差别是,MyScaleDB 具有高可扩展性,而 Qdrant 的扩展则是非线性的,从下图中可以看到这种区别。
03
基准测试
尽管之前的功能对比展现了两者之间的明显差异,但客观的基准测试能更具体地揭示 MyScaleDB 和 Qdrant 的性能表现。
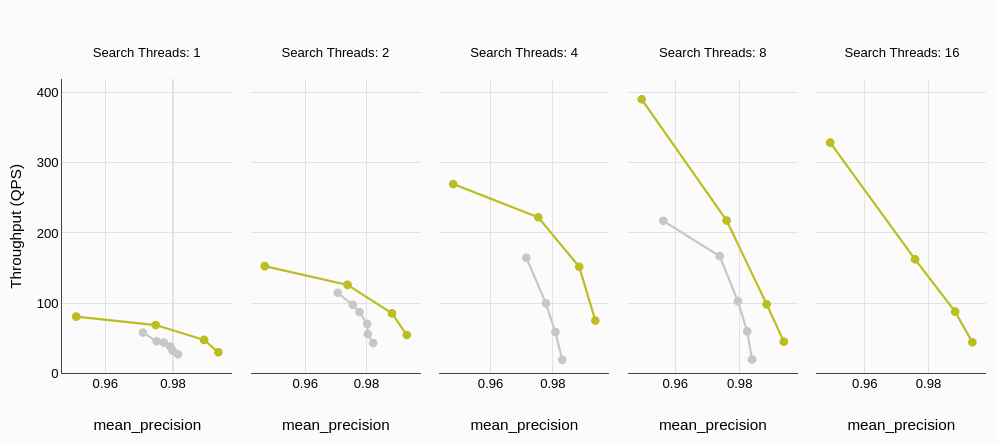
吞吐量(每秒查询次数)
吞吐量,通常以每秒查询次数(QPS)来衡量,直接反映了数据库处理并发请求的能力。基准测试结果清楚地表明,MyScaleDB 的吞吐量明显优于 Qdrant。而且,随着并发线程数量的增加,两者的性能差距显著扩大,展示了 MyScaleDB 在高负载下出色的可扩展性。
平均查询延迟
平均查询延迟,以毫秒或秒为单位,表示数据库处理查询并返回结果的平均时间。较低的延迟意味着更快的响应时间,这是实时应用和用户体验中的关键因素。
基准测试结果显示,MyScaleDB 的平均查询延迟显著低于 Qdrant。这个差别在不同的线程数量下都保持一致,表明 MyScaleDB 即使在高并发情况下也能维持低延迟。
在 P95(95百分位) 的延迟测试中也观察到类似差别,这进一步凸显了 MyScaleDB 在实际应用中较低的延迟。
构建时间
MyScaleDB(绿色;右下角的小点)不仅精度更高,而且速度几乎是 Qdrant 的 5 倍。
每月成本
成本效益在选择合适的数据库解决方案中起着至关重要的作用。正如在定价部分所提及的,MyScaleDB 通常提供了比 Qdrant 更加划算的选择,特别是在考虑到其免费计划包含的丰富资源时。
这张图进一步解释了在搜索线程数量方面的成本差异。我们可以看到,Qdrant 的成本(灰色)随着搜索线程的增加呈现陡峭的上升趋势。相比之下,MyScaleDB 的成本明显较低,即使在高线程情况下也保持相对稳定。
01
Qdrant 简介
Qdrant 是一款开源的向量数据库,可以在 Docker 和云端运行。Qdrant 具有如下特点:
高级压缩技术:Qdrant 使用二进制量化技术,将任何数值向量嵌入转换为布尔值向量,提升了多达 40 倍的搜索性能。
多租户支持:单个集合中的基于负载的分区称为多租户。Qdrant 支持多用户共享实例。
I/O Uring:Qdrant 支持 io_uring 技术,提升了吞吐量,缓解了操作系统系统调用的开销。
02
托管灵活性
在选择数据库解决方案时,考虑托管服务至关重要,它对数据库的性能、扩展能力和管理便捷性有显著影响。优秀的托管服务可以保证数据库平稳应对工作负载变化,确保服务的高可用性,并简化管理工作。
在托管方面,MyScaleDB 和 Qdrant 都提供开源版本、云端解决方案以及本地部署方案。云托管包括免费和付费等级,接下来我们将详细介绍这些选项。
云托管
MyScaleDB 的云托管服务有多种可选方案,用户可以从支持 500 万 768 维向量的免费 Pod 开始。
Qdrant 提供一个 1GB 的永久免费集群,无需任何前期费用。
本地部署
对于本地解决方案,Docker 镜像是一个常见的选项。我们可以通过以下方式启动 MyScaleDB Docker 镜像:
然后使用 ClickHouse 客户端连接到数据库:
同样,Qdrant 也可以使用 Docker 本地运行:
02
核心功能
虽然托管选项为数据库的可访问性和可扩展性奠定了基础,但真正区分 MyScaleDB 和 Qdrant 的是核心功能。我们将深入探讨这两个平台的功能特点,以便用户更好地理解它们是如何处理复杂的向量数据操作的。
查询语言和 API 支持
Qdrant:Qdrant 拥有广泛的多语言支持,为开发者提供了 Python、Java、Go、.Net、Rust 和 TypeScript/JavaScript 的 SDK。这种广泛的语言支持确保了与各种技术栈的无缝集成。
MyScaleDB:MyScaleDB 提供了 Python、Java、Go 和 Node.JS 的 SDK,支持主流编程语言。
尽管两者都提供了广泛的多语言支持,MyScaleDB 因其对 SQL 的独特支持而脱颖而出。用户可以使用传统的 SQL 查询与 MyScaleDB 交互,它可以无缝处理向量数据库,甚至可以与传统数据库结合使用,例如:
MyScaleDB 中的 distance 方法通过测量指定向量与存储在特定列中的所有向量之间的距离来计算向量相似度。
支持的数据类型
处理多样化的数据类型是任何数据库的必要功能,向量数据库也不例外。我们来比较一下 MyScaleDB 和 Qdrant 在数据类型支持方面的表现。
Qdrant 利用 JSON 有效负载的灵活性,允许存储和查询多种数据类型,包括:
关键词:用于基于文本的搜索和过滤。
整数和浮点数:用于数值数据和范围查询。
嵌套对象和数组:用于表示复杂的数据结构。
这种以 JSON 为中心的方式提供了数据建模的灵活性,适用于各种用例。
MyScaleDB 通过利用其完整的 SQL 兼容性,将数据类型支持提升到了一个新的层次。它不仅能管理向量数据,还能处理广泛的传统数据类型,包括:
结构化数据:传统的关系数据类型,如整数、浮点数、字符串、日期等。
JSON:用于处理半结构化数据和嵌套对象。
地理空间数据:用于基于位置的查询和空间分析。
时间序列数据:用于存储和分析时间戳数据。
MyScaleDB 能够在单个平台内处理向量数据和多种传统数据类型,这一优势显著简化了数据管理过程,消除了数据孤岛,并允许用户跨数据类型进行复杂查询。
以下是一个示例表,展示了 MyScaleDB 可以管理的多样化列,包括向量数据:
这个 SQL 命令创建了一个表,包含结构化和向量化数据,强制 body_vector 的大小为 768,并通过按 id 排序来优化查询。
TL:DR:两者都有效支持多种数值和文本数据类型,但 MyScaleDB 通过其高级 SQL 兼容性、强大的 OLAP 功能和对复杂数据结构(如地理空间和时间序列数据)的全面支持,将这一能力提升到了一个新的高度。
索引
Qdrant 使用 HNSW 索引算法,尽管在标准向量搜索中有效,但在过滤搜索操作中表现较弱。
MyScaleDB 通过引入 多尺度树图(MSTG) 算法解决了这一限制。MSTG 结合了层次树聚类和基于图的搜索,显著提高了检索速度和性能,使其在标准和复杂的过滤向量搜索操作中都能高效运行。
同时,MyScaleDB 和 Qdrant 也都支持多向量搜索。
全文搜索
全文搜索 是 Qdrant(从 0.10.0 版本开始)和 MyScaleDB 都支持的功能。
Qdrant 通过支持文本字段的分词和索引实现全文搜索,允许根据特定词语或短语进行搜索和过滤。
MyScaleDB 使用 Tantivy 库,该库利用 BM25 算法进行准确高效的文档检索。在 MyScaleDB 示例中,我们使用了带有英语停用词的 `stem` 分词器,它可以通过关注词的词根形式来提高搜索精度。这里我们使用了 en_wiki_abstract 表。
这个命令在 en_wiki_abstract 表中的 body 列上创建了一个全文搜索索引。
TL:DR:两者都支持全文搜索,但 MyScaleDB 具备 BM25 算法和 SQL 支持,在检索文档的准确性和效率方面稍占优势。
过滤搜索
MyScaleDB 通过其 MSTG 算法及位掩码技术优化了过滤向量搜索。这一组合,再加上 ClickHouse 的高级索引和并行处理能力,使 MyScaleDB 能够高效处理大型数据集。通过采用预过滤策略,MyScaleDB 在主要的向量搜索之前缩小数据集的范围,确保只处理最相关的数据,大大提升了性能和准确性。
Qdrant 使用可过滤的 HNSW 算法,在搜索过程中应用过滤器,确保只考虑搜索图中相关的节点。
地理搜索
MyScaleDB 和 Qdrant 都支持地理搜索。MyScaleDB 提供了多个地理空间功能来支持地理搜索。例如,以下函数用于计算地球上两个点之间的距离(作为一个流形处理):
大语言模型 API 集成
向量搜索最大的应用场景就是大语言模型(LLM)和检索增强生成(RAG)。Qdrant 和 MyScaleDB 都支持多种 LLM API 的集成,如 LlamaIndex、LangChain 和 Hugging Face。
03
定价
Qdrant 和 MyScaleDB 都采用了免费增值的定价模式,提供适用于实验和小型项目的免费版,以及为高需求工作负载设计的付费版。两者都允许用户在无需绑卡的情况下探索其免费服务。
免费方案
Qdrant:在免费方案中提供 1GB 的存储容量。
MyScaleDB:提供跨级别的免费额度,允许存储高达 500 万个 768 维向量。相比之下,在 Qdrant 平台上达到这个存储容量将需要选择大约 275 美元/月。
付费方案
在付费方案方面,Qdrant 提供了三种云托管类型:GCP、Azure 和 AWS。
我们将比较 Qdrant 的 GCP 托管和 MyScaleDB 的付费方案,使用相同的 768 维向量来进行对比。
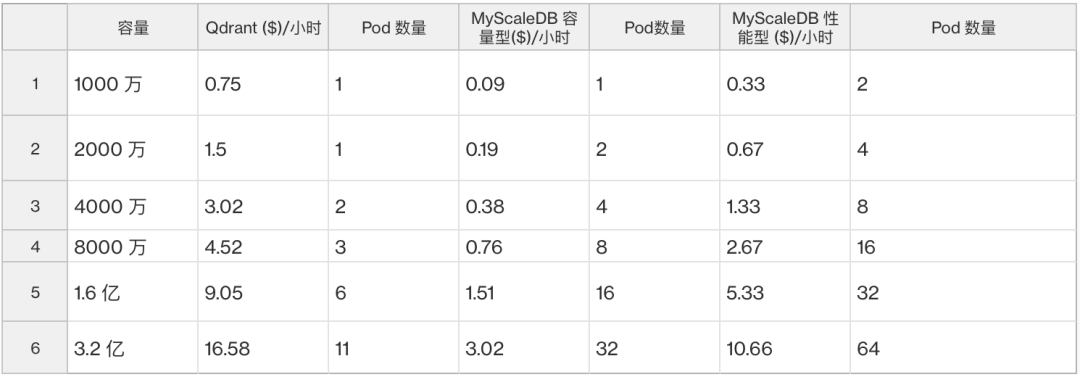
在 MyScaleDB 的容量型 Pods 中,每个 Pod 可存储 1000 万个向量,而性能优化设置则可以提供更低的延迟,因此也需要更多的 Pods 来存储数据。我们可以看到即使是 MyScaleDB 的性能优化 Pods,其价格也远低于 Qdrant 最经济的设置。
另一个差别是,MyScaleDB 具有高可扩展性,而 Qdrant 的扩展则是非线性的,从下图中可以看到这种区别。
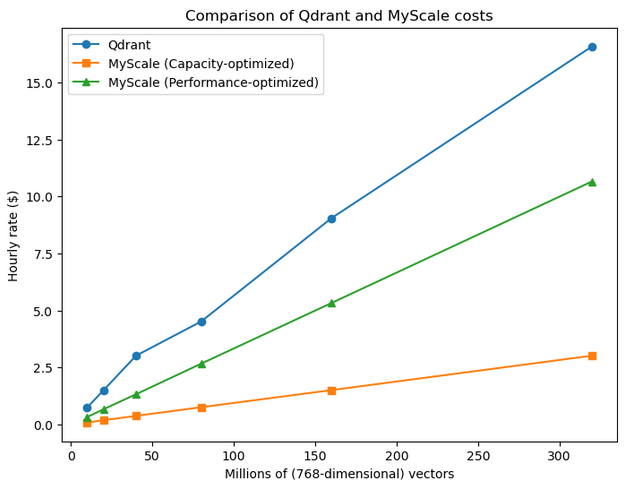
03
基准测试
尽管之前的功能对比展现了两者之间的明显差异,但客观的基准测试能更具体地揭示 MyScaleDB 和 Qdrant 的性能表现。
吞吐量(每秒查询次数)
吞吐量,通常以每秒查询次数(QPS)来衡量,直接反映了数据库处理并发请求的能力。基准测试结果清楚地表明,MyScaleDB 的吞吐量明显优于 Qdrant。而且,随着并发线程数量的增加,两者的性能差距显著扩大,展示了 MyScaleDB 在高负载下出色的可扩展性。
平均查询延迟
平均查询延迟,以毫秒或秒为单位,表示数据库处理查询并返回结果的平均时间。较低的延迟意味着更快的响应时间,这是实时应用和用户体验中的关键因素。
基准测试结果显示,MyScaleDB 的平均查询延迟显著低于 Qdrant。这个差别在不同的线程数量下都保持一致,表明 MyScaleDB 即使在高并发情况下也能维持低延迟。
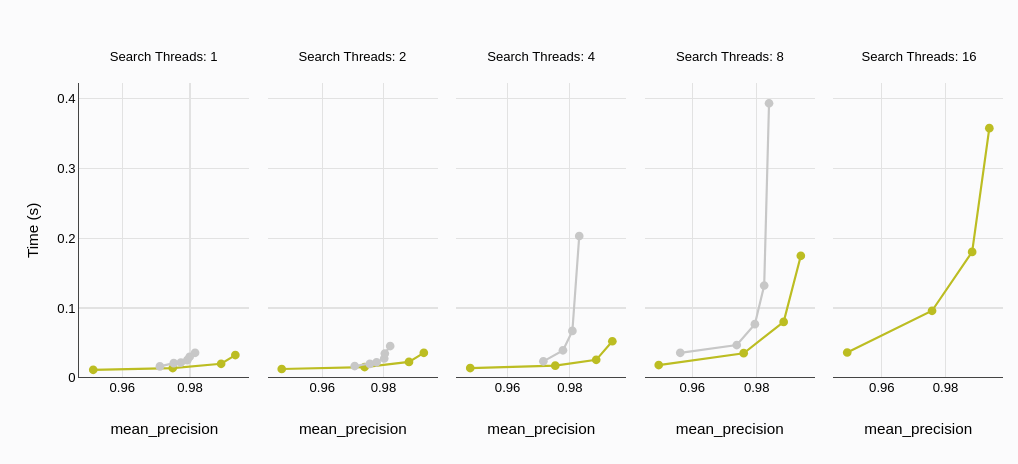
在 P95(95百分位) 的延迟测试中也观察到类似差别,这进一步凸显了 MyScaleDB 在实际应用中较低的延迟。
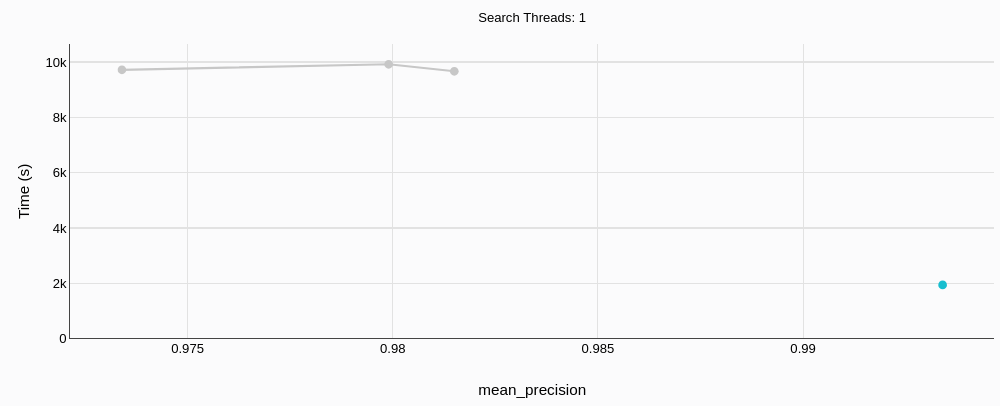
构建时间
MyScaleDB(绿色;右下角的小点)不仅精度更高,而且速度几乎是 Qdrant 的 5 倍。
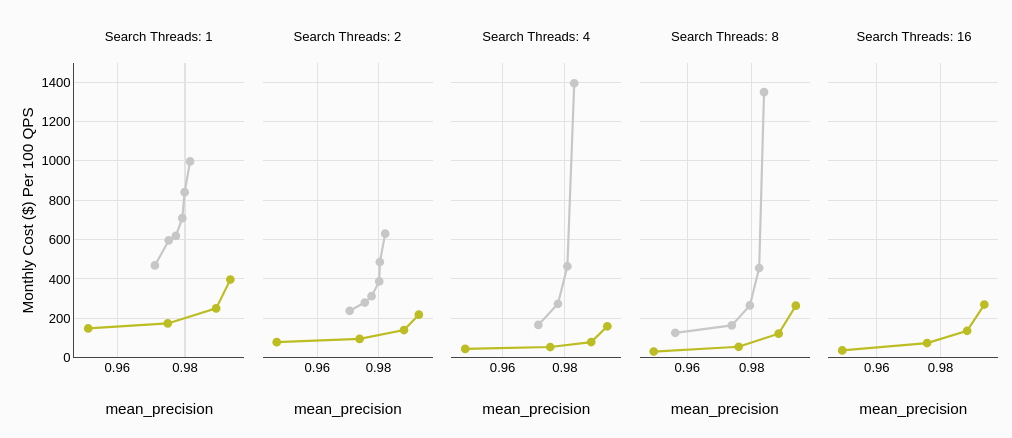
每月成本
成本效益在选择合适的数据库解决方案中起着至关重要的作用。正如在定价部分所提及的,MyScaleDB 通常提供了比 Qdrant 更加划算的选择,特别是在考虑到其免费计划包含的丰富资源时。
这张图进一步解释了在搜索线程数量方面的成本差异。我们可以看到,Qdrant 的成本(灰色)随着搜索线程的增加呈现陡峭的上升趋势。相比之下,MyScaleDB 的成本明显较低,即使在高线程情况下也保持相对稳定。
结论
Qdrant 和 MyScaleDB 都是向量数据库领域的杰出竞争者。Qdrant 作为市场的先行者,拥有更广泛的采用率,并提供稀疏向量和量化技术等特色功能。然而,MyScaleDB 在以下关键领域展现了显著的优势:
性能和可扩展性:MyScaleDB 在基准测试中表现出色,展示了卓越的吞吐量、更低的延迟,并在高负载下表现出色的可扩展性。
性价比:MyScaleDB 的免费计划内容更加丰富,付费计划的成本显著低于 Qdrant,特别是在高并发场景下。
统一数据管理:MyScaleDB 能够在单一平台上管理向量和多种传统数据类型,简化了数据处理的复杂流程,并支持复杂的跨数据查询。
SQL 驱动的简洁性:借助 SQL 的通用性和表达能力,MyScaleDB 简化了开发过程,使用户能够通过广泛采用的语言与向量数据进行交互。
基于不同的具体需求,Qdrant 的多语言支持和稀疏向量处理功能可能更为重要; 但如果性能、可扩展性、成本效益和数据管理能力是首要考虑因素,MyScaleDB 无疑是更好的选择。
我们建议用户深入分析自己的需求,并结合本次比较的洞察,做出适合用户特定数据处理和应用需求的明智选择。
了解墨奇科技 点击更多资讯

