




在当今大型系统中,资源的高效利用是至关重要的。为了应对高密度写入操作所带来的巨大资源消耗,{近似模式}(Approximation Pattern)应运而生。该模式的核心理念是通过使用“足够好”且更具成本效益的操作替代高成本的精准操作,以达到节省资源的目的,本文将为您介绍{近似模式}的应用案例、优点以及其局限性,最后对{近似模式}进行总结。
1.{近似模式}总体介绍
{近似模式}的设计初衷是为了节省系统资源。在大型系统中,特别是涉及到频繁的写入操作时,传统的精准计数往往会导致极大的资源开销。{近似模式}通过引入一定的近似算法,以牺牲一定的精确度为代价,极大地减少了写入的频率,从而在资源消耗上取得了平衡。
{近似模式}有多个变体,其中包括缓冲写入、应用固定随机写入、应用几何随机写入等。这些变体在不同的场景下可以灵活应用,具体取决于业务需求和数据特征。
2.{近似模式}应用场景
以电商系统为例,系统需要实时统计用户对商品的浏览次数。传统的方法是在商品文档中维护一个页面访问计数器。然而,在商品发布后迅速引起大量用户浏览时,传统递增操作将导致巨大的写入量,给系统资源带来巨大压力。
在电商系统中,例如一家在线购物平台开始促销活动时,新商品可能会在短时间内迅速吸引数百万用户的浏览。这种情况下,如果每次用户浏览都直接导致递增操作,将会给数据库系统带来极大的负担。
{近似模式}可以轻松解决上述问题。举例来说,我们通过在递增操作前引入随机抽取机制,仅有一小部分递增操作真正执行,而其他部分被近似为0。通过这种设计,即使在高峰时期,系统也可以在保持一定精确度的情况下显著减少写入次数。
if random(0..99) == 0:inc = 100db.col1.write({mycounter: inc})else:do nothinginc = 0
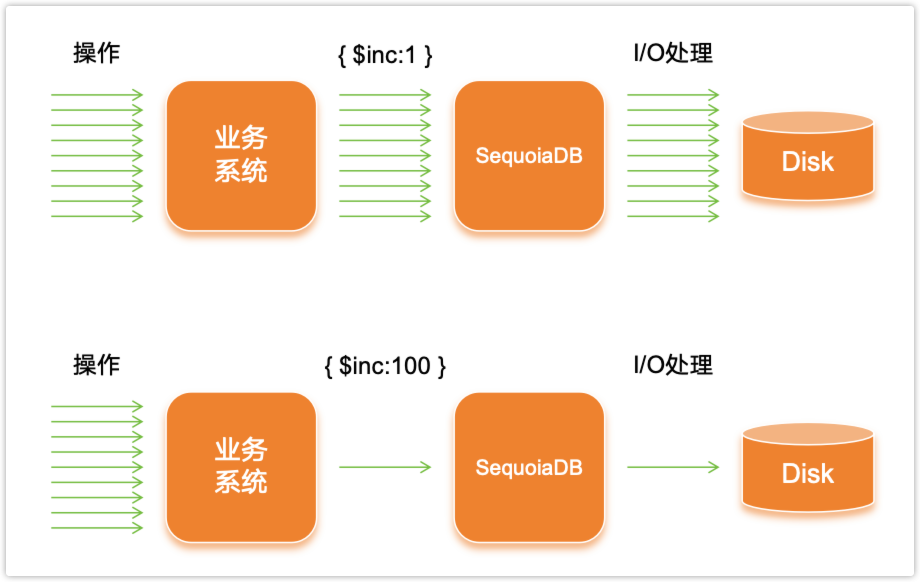
系统可以根据概率随机抽取部分递增操作,每次仅有一小部分真正执行递增,其余被近似为0。以此为例,一小时内的写入次数从原本的1000万次减少到10万次,极大地降低了系统的负载。这样的优化不仅能够提高系统的性能,更使系统能够更专注于核心业务功能,确保用户体验的流畅性。
值得一提的是,这一设计不仅适用于电商系统,同样可以在其他大规模访问的场景中发挥重要作用,为系统稳定运行提供了可行而高效的解决方案。
还有一些其它场景也适合应用{近似模式},通常属于以下类别:
数据很难正确计算
数据计算代价高昂
不精确的数字可以接受
控制精度与误差
在引入{近似模式}时,需要控制精度与误差之间的关系。设计中采用了按X递增值,抽取1/X的次数进行写入的方式。在大数字上,由于误差的相对比例较小,损失的精度可以被忽略。然而,写入间隔的增大会引入一定的误差。小计数器的影响更为显著,因此需要根据具体情况调整写入的间隔,以平衡资源消耗和计数的精确度。
3.实现{近似模式}的方法
要实现{近似模式},请采取以下步骤:
可以修改应用程序的业务逻辑,来处理写入的频率和负载,{近似模式}不需要对模式进行任何更改。
如前所述,下面的代码片段将引入近似算法,将给定值的写入次数以100进行划分:
counter = counter + 1if counter == 100:db.col1.updateOne({ "_id" : "xxxxxx" },{ $set: { "mycounter" : counter } })counter = 0else:do nothing...on_termination(counter):db.col1.updateOne({ "_id" : "xxxxxx" },{ $set: { "mycounter" : counter } })
4.使用{近似模式}的示例
{近似模式}的以下“保险业务”示例中,为满足通用需求,特别是计数器的需求,我们选择使用{近似模式}来建模网站页面访问量。该模式在数据建模方面简便易行,只需在合适的文档中添加计数器即可。
以保险产品的文档为例,我们在文档中添加了一个名为"web_page_views"的字段,用于存储网页访问量的计数,不会精确记录每次浏览,事例中按100次为间隔进行更新。文档模型如下:
{"_id": "vlog7923479273","product_name": "儿童健康险(D)",..."web_page_views": "472300"}
通过简单地在文档中添加计数器字段,无需复杂的操作,即可实现对通用需求的满足。这种模式具有较高的可维护性,且在计数操作频繁的场景下,提供了一种高效的解决方案
5.{近似模式}的优点:
降低写入次数: {近似模式}显著减少计数器的写入次数,可将写入操作的负载压力缩减为10、100甚至1000分之一。
冲突处理优雅: 在多线程同时尝试递增计数器时,可能发生写入冲突。「巨杉文档型数据库」的存储引擎通过重试的方式处理这种冲突,避免资源浪费和进程排队状态。
生成有效的近似值: {近似模式}生成的数值在统计上是有效的。对于大多数应用场景,精确度的损失是可以接受的。
6.使用{近似模式}的局限性:
引入异常值: {近似模式}为目标字段引入了一些“异常”,可能导致结果略微偏离准确的数字。这是因为在{近似模式}中,一部分写入操作有选择性地执行,而另一部分被忽略,引入了计数器的不确定性。
缓存写入的准确性下降: 对于缓存写入,如果所有进程在退出之前能够刷新写入数据,计数器仍然是准确的。然而,随着时间的推移,由于偏差的累积,报告的数字可能会等于或低于预期数字,导致准确性下降。
代码复杂度增加: 引入{近似模式}会增加代码的复杂度。应用程序不再是简单的递增计数器的写入操作,而需要生成随机数并检查是否触发写入,增加了代码的复杂性和维护成本。
总结
{近似模式}作为一种资源优化的手段,在文档型数据库中展现了强大的实用性。通过合理的近似算法设计,可以在保证业务需求的同时,显著降低系统资源的消耗。文档型数据库在{近似模式}的应用中发挥了其灵活性和横向扩展性的优势,为大规模系统的高效运行提供了可靠的支持。
问题 | 为了保持完美状态进行的写操作占用资源过高,而此完美状态并不需要。 |
解决方案 | 减少写操作频率。 增加每个写操作的负载(即批量写入)。 |
使用案例 | 网页访问统计。 其它高值计数器。 统计数据。 |
优点 | 减少写操作次数 减少对文档的写操作争用。 统计上有效的数字。 |
局限 | 可能产生不完全精确的数字。 必须在应用程序中实现。 |
