





MySQL 多索引变更
sysbench的测试表
sbtest1为例。
mysql> show create table sbtest1\G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int NOT NULL AUTO_INCREMENT,
`k` int NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> select count(*) from sbtest1;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.14 sec)
mysql> explain select count(*) from sbtest1 where k=456174 and c like '58241701921-%';
+----+-------------+---------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | sbtest1 | NULL | ref | k_1 | k_1 | 4 | const | 2 | 11.11 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
k_1(k)。数据库索引创建原则应当尽量兼顾多个业务查询场景,优先考虑重要业务场景等。假设经过综合分析后,应该创建一个新索引
k_2(k,c)。同时由于这个新索引能覆盖老的单列索引
k_1,所以新索引创建后老的索引也可以删除。
-- 创建新的索引
alter table sbtest1 add key k_2(k,c);
-- 验证业务 SQL 执行计划和性能
-- 删除老的索引
alter table sbtest1 drop key k_1 ;
alter table sbtest1 add key k_2(k,c) ,drop key k_1;
autocommit=0)。即使会话开启了事务,做了 DDL 后,DDL 成功时也会自动提交事务。所以一个好的经验是尽量不要在事务里使用 DDL,会导致事务被提前提交,可能带来业务异常。撇开会话事务的干扰,DDL 自身也应该是一个事务。多个索引变更操作要么全部成功,要么全部失败。我们可以用下面的方法验证一下这个。
mysql> insert into sbtest1(k,c,pad) select k,c,pad from sbtest1 limit 2;
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> show indexes from sbtest1;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| sbtest1 | 0 | PRIMARY | 1 | id | A | 986400 | NULL | NULL | | BTREE | | | YES | NULL |
| sbtest1 | 1 | k_1 | 1 | k | A | 181043 | NULL | NULL | | BTREE | | | YES | NULL |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.00 sec)
mysql> alter table sbtest1 add unique key k_2(k,c) ,drop key k_1;
ERROR 1062 (23000): Duplicate entry '501462-68487932199-96439406143-93774651418-41631865787-964060727' for key 'sbtest1.k_2'
mysql> show indexes from sbtest1;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| sbtest1 | 0 | PRIMARY | 1 | id | A | 986400 | NULL | NULL | | BTREE | | | YES | NULL |
| sbtest1 | 1 | k_1 | 1 | k | A | 181043 | NULL | NULL | | BTREE | | | YES | NULL |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.00 sec)
for i in `seq 3600`;do echo `date`; mysql -h10.0.0.66 -uu_test -P3306 -p123456 sysbenchdb -c -A -e "explain select count(*) from sbtest1 where k=456174 and c like '0620892854%';"; sleep 0.5; done
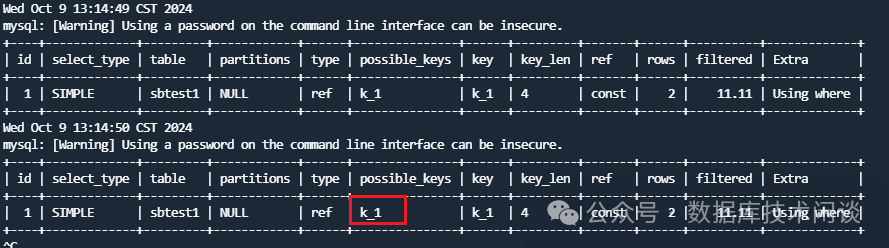
mysql> alter table sbtest1 add key k_2(k,c) ,drop key k_1;
Query OK, 0 rows affected (5.75 sec)
Records: 0 Duplicates: 0 Warnings: 0
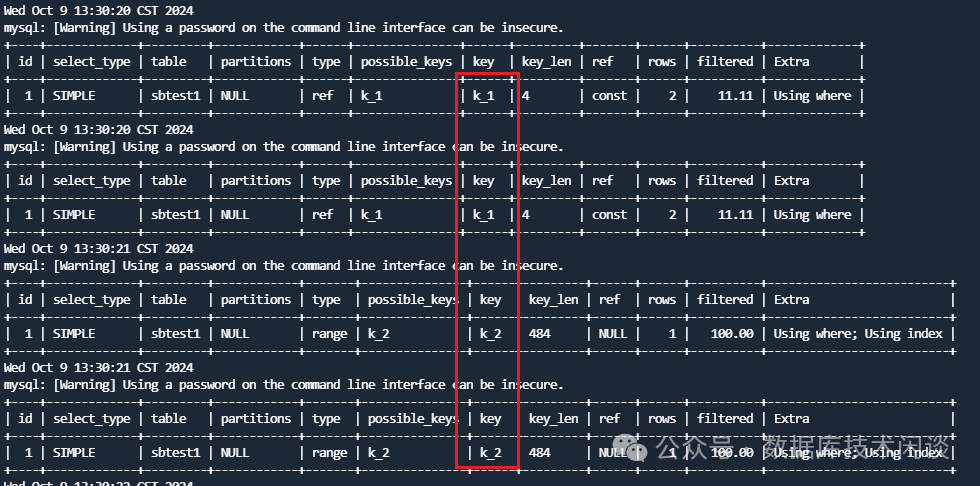
k_1平滑迁移到
k_2。
OB 多索引变更观察
sbtest1。然后同样的运行上面的观察语句。
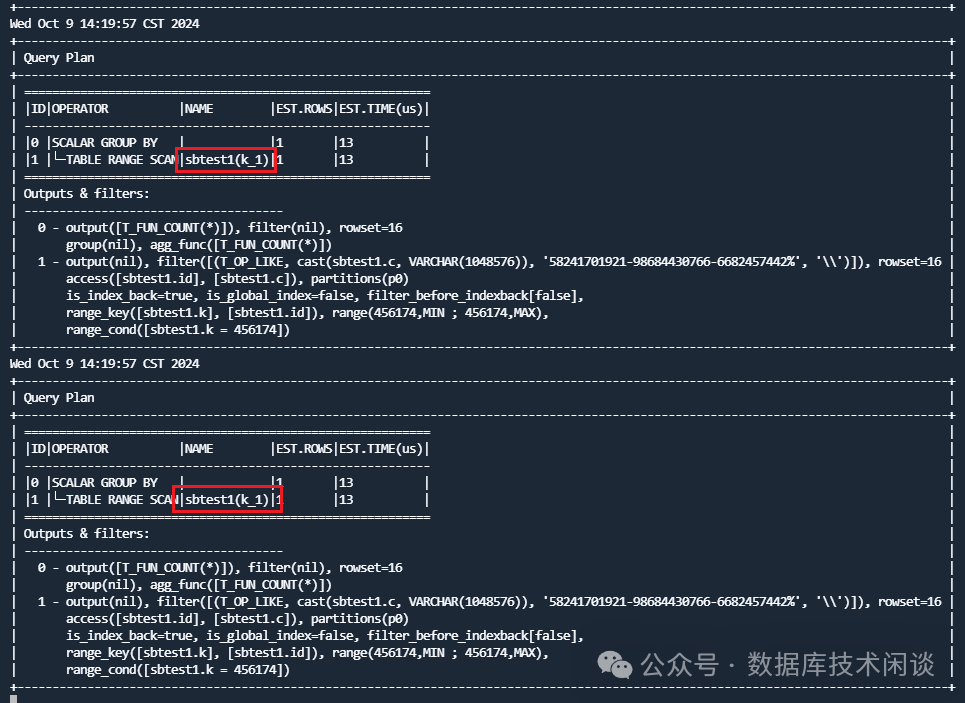
for i in `seq 36000`;do echo `date`; obclient -h127.1 -uu_test@obmysql -P2881 -p'123456' -c -A sysbenchdb -e "explain select count(*) from sbtest1 where k=456174 and c like '58241701921-98684430766-6682457442%';"; sleep 0.5 ;done
k_1。
obclient [sysbenchdb]> alter table sbtest1 add unique key k_2(k,c) ,drop key k_1;
ERROR 1062 (23000): Duplicate entry '501462-68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441' for key 'k_2'
obclient [sysbenchdb]> show indexes from sbtest1;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
| sbtest1 | 0 | PRIMARY | 1 | id | A | NULL | NULL | NULL | | BTREE | available | | YES | NULL |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
1 row in set (0.003 sec)
obclient [sysbenchdb]> select now();
+---------------------+
| now() |
+---------------------+
| 2024-10-09 14:30:17 |
+---------------------+
1 row in set (0.000 sec)
obclient [sysbenchdb]> alter table sbtest1 add key k_2(k,c) ,drop key k_1;
Query OK, 0 rows affected (8.673 sec)
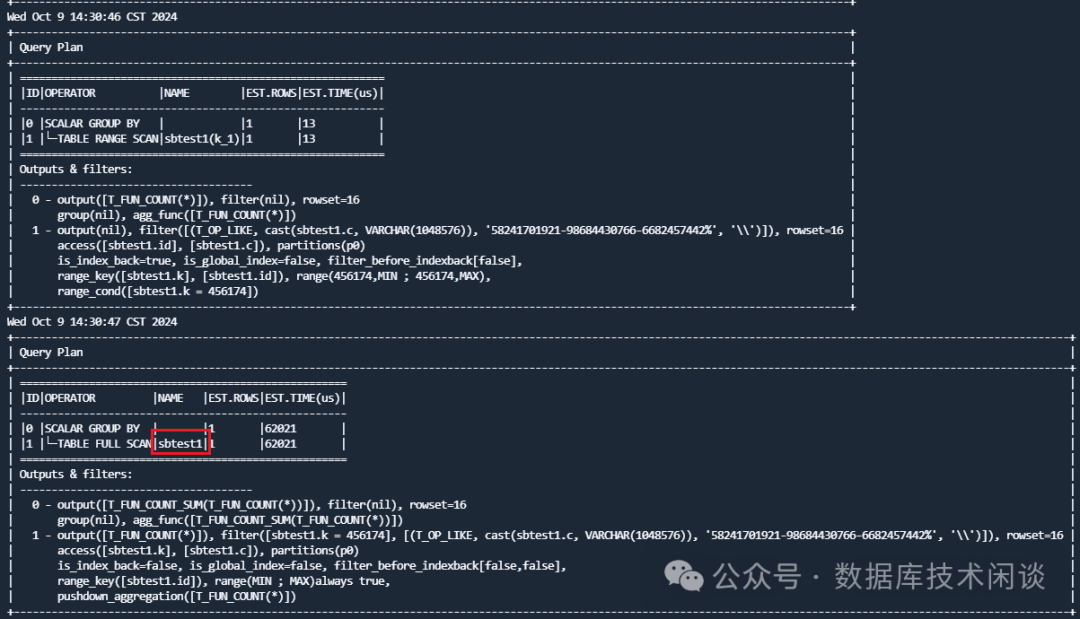
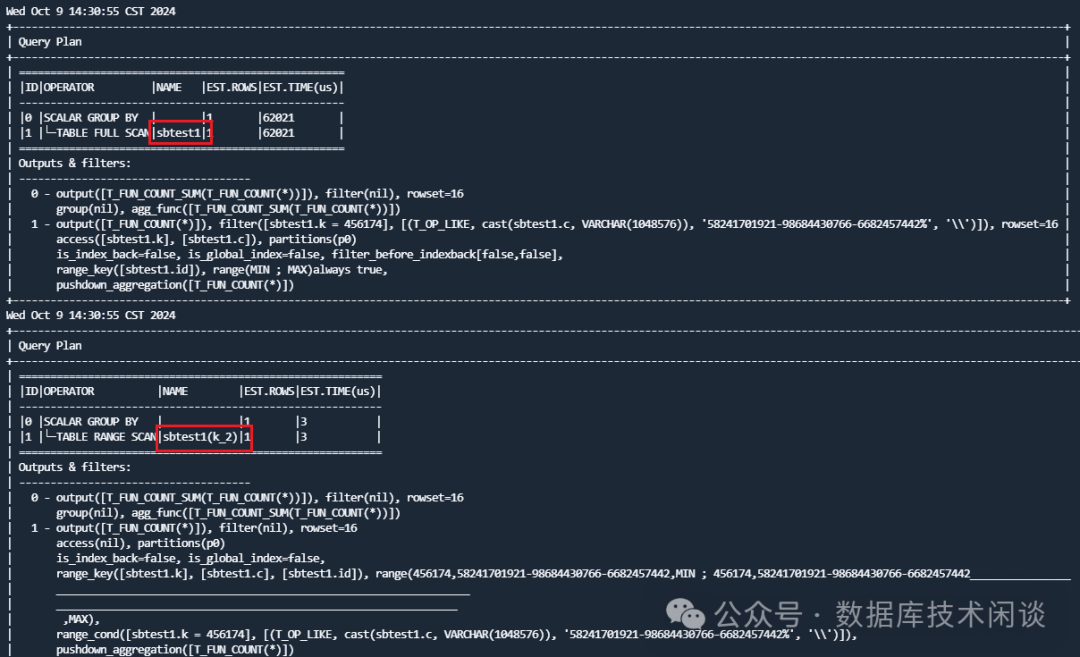
最后执行计划用上了新的索引。
OB DDL 观察
__all_ddl_operation用于观察 DDL 的执行细节过程。
select o.tenant_id, o.gmt_create, o.database_id, d.database_name, o.table_id, t.table_name, o.operation_type, o.ddl_stmt_str
from oceanbase.__all_ddl_operation o left join oceanbase.`__all_database` d on (o.database_id=d.database_id)
left join oceanbase.__all_table t on (o.table_id=t.table_id)
where o.gmt_create >='2024-10-09 14:30:17'
order by o.gmt_create ;
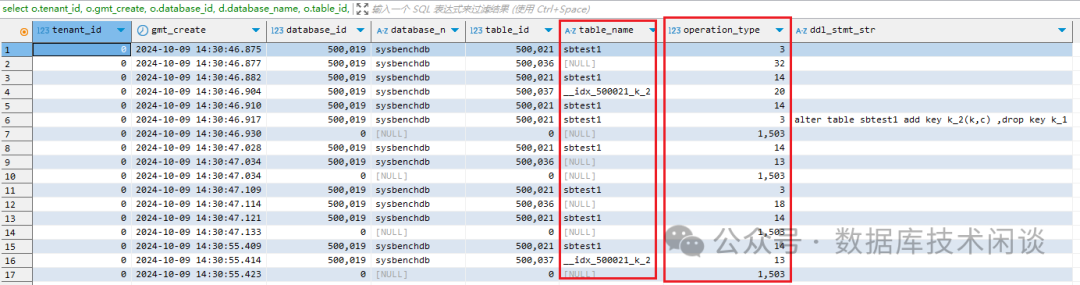
operation_type是枚举类型,含义不明。此外,部分记录的列
table_name为空(有些是索引名。)。
| 类型ID | 类型标识符 | 类型描述 |
|---|---|---|
| 3 | OB_DDL_ALTER_TABLE | ALTER TABLE 语句 |
| 13 | OB_DDL_MODIFY_INDEX_STATUS | 修改索引状态 |
| 14 | OB_DDL_MODIFY_TABLE_SCHEMA_VERSION | 修改SCHEMA版本 |
| 15 | OB_DDL_MODIFY_TABLE_OPTION | 修改表的选项 |
| 18 | OB_DDL_DROP_INDEX | 删除索引 |
| 20 | OB_DDL_CREATE_INDEX | 创建索引 |
| 32 | OB_DDL_RENAME_INDEX | 重命名索引 |
| 1503 | OB_DDL_END_SIGN | DDL结束信号 |
DROP INDEX
比ADD INDEX
先结束。DROP INDEX
之所以看不到索引名,是因为索引已经 DROP 了,无法关联获取索引名称。有 4 次 DDL 结束信号。OB 没有去保证 DDL 事务原子性,而可能是将 DDL 语句多个变更操作分拆为多个独立的子任务,每个子任务有独立的事务。子任务(原子变更任务)之间的依赖关系由用户自己负责。
OB 的这个做法初衷应该是为了发挥分布式架构的优势,提升 DDL 的效率(特别是大表变更)。这个变化带来的风险确实很大。这个设计后期估计会调整,具体行为会如何到时候再看。
更多思考
ONLINE DDL, 有些是
OFFLINE DDL。如果混合了二者,那最终呈现的效果是
ONLINE DDL还是
OFFLINE DDL呢?
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001432372是 4.3.3 最新的
ONLINE DDL和
OFFLINE DDL能力列表。如果仔细阅读这份文档,你会发现要考虑的场景很多,还真没有一个简单的答案。
兼容 MySQL 的国产数据库还有 TiDB、PolarDB-X、PolarDB(MySQL)、TDSQL、GoldenDB、GaussDB(MySQL)。有环境的有兴趣的也可以跑一下上面这个案例场景,看看结果如何。欢迎留言分享。
文章转载自数据库技术闲谈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
