




ECML PKDD(European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases)是欧洲地区一项重要的学术会议,专注于机器学习及知识发现领域。会议旨在促进研究人员、实践者和产业界的交流与合作,汇聚来自全球的专家,分享最新的研究成果、技术和应用。ECML PKDD涵盖了广泛的主题,包括但不限于数据挖掘、预测建模、半监督学习、强化学习及其在各个领域的应用,如生物信息学、金融、社会网络等。会议通常包括主题演讲、论文展示、工作坊和教程,为参与者提供了一个深入探讨前沿研究与技术的机会。通过这样的互动平台,推动着机器学习与数据科学的理论与实践发展,对相关学科的进步产生了积极影响。《Subgraph Retrieval Enhanced by Graph-Text Alignment for Commonsense Question Answering》这篇论文由蚂蚁集团联合北京大学、北京师范大学撰写,提出了通过图-文本对齐技术增强子图信息提取来解决常识问答的方法。

导读:常识回答是NLP领域的一个重要任务,它要求机器根据常识进行推理。之前的研究主要采用了一种提取-建模的范式来利用KG中的信息:首先基于预设规则提取相关子图,然后设计多种策略来改善提取的结构知识的表示和融合。尽管它们取得了一定的效果,但仍存在两个挑战。一方面,基于规则的方法提取的子图可能忽略关键节点,导致子图大小不可控。另一方面,图和文本模态之间的不对齐削弱了知识融合的有效性,最终影响了任务性能。为了解决上述问题,本文提出了一个新颖的框架:Subgraph Retrieval Enhanced by Graph-Text Alignment(SEPTA)。首先,本文将知识图谱转化为子图向量数据库,并利用BFS和消息传递机制之间的相似性,采用了一种BFS方式的子图采样策略来避免信息丢失。此外,我们提出了一种双向对比学习方法来进行图-文本对齐,这有效地提高了子图检索和知识融合的效果。最后,本文通过一个预测模块将所有检索到的信息结合并进行推理。在五个数据集上的广泛实验证明了框架的有效性和鲁棒性。
论文链接:https://link.springer.com/chapter/10.1007/978-3-031-70365-2_3
01 动机
常识问题回答(CSQA)是自然语言理解中的一项关键任务,它要求系统能够根据常识进行推理。例如,一个典型的CSQA问题可能是:“如果我把一块冰放在一个热的房间里,它会怎么样?”要回答这个问题,系统需要具备关于物理世界的基本常识,例如“冰在加热时会融化”。
然而,现有的CSQA系统在处理这类问题时存在一些挑战。首先,常识知识通常不会在预训练文本语料库中明确表达,因此系统难以从文本中学习到这些知识。其次,即使系统能够获取到相关的常识知识,如何有效地将这些知识与问题文本进行融合,并进行合理的推理,也是一个挑战。
为了解决这些问题,一些研究者开始探索利用知识图谱(KG)来增强CSQA系统的性能。知识图谱是一种结构化的常识知识表示方式,它将世界知识表示为一组实体和关系。通过将知识图谱与CSQA系统结合,可以为系统提供更丰富的常识知识来源,并帮助系统更好地进行推理。
然而,现有的基于知识图谱的CSQA系统主要遵循一个“提取-建模”的范式,即首先从知识图谱中提取与问题相关的子图,然后对这些子图进行建模和融合。这种范式存在一些局限性:
1. 子图提取的局限性:基于规则的方法在提取子图时,可能会忽略一些关键的节点和关系,导致提取到的子图不完整或不准确。
2. 图-文本模态的不对齐:在将提取到的子图与问题文本进行融合时,图和文本之间的模态差异可能会导致知识融合的效果不佳,影响最终的回答准确性。
为了克服这些局限性,本文提出了一个名为SEPTA(Subgraph REtrieval Enhanced by GraPh-Text Alignment)的新颖框架。
02 方法
SEPTA框架的核心思想是通过改进子图提取和图-文本对齐的方式,来增强CSQA系统的性能。具体来说,SEPTA框架包括以下几个关键组件:
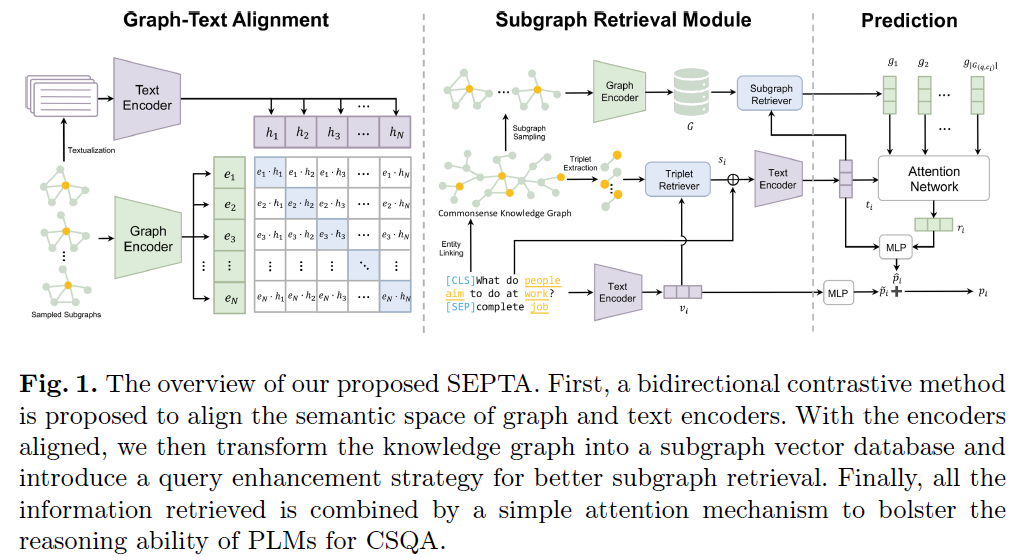
1. 图-文本对齐模块
该模块旨在通过对比学习等方法,对图和文本编码器的嵌入空间进行对齐,以促进图和文本之间的知识融合。具体来说,该模块包括以下几个步骤:
图-文本对的构造:为了进行图-文本对齐,首先需要构造大量的图-文本对。本文提出了一种基于图的文本描述生成方法,通过遍历知识图谱中的实体和关系,生成相应的文本描述。
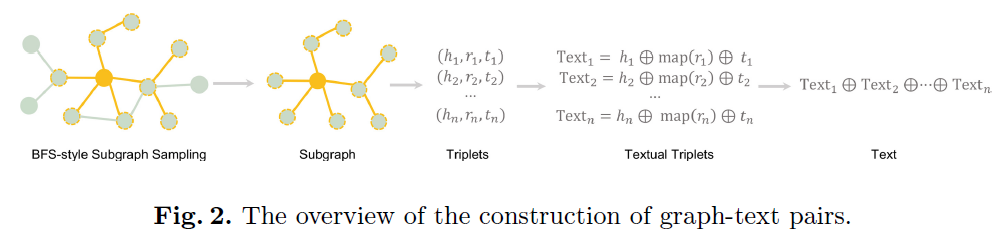
对比学习:在生成了图-文本对之后,本文使用对比学习的方法来对齐图和文本的嵌入空间。具体来说,使用InfoNCE损失函数,通过在批次内进行负采样,来优化图和文本编码器的参数,使其在嵌入空间中更接近。
通过这个模块,SEPTA框架能够使图和文本的嵌入空间更加一致,从而促进后续的子图检索和知识融合过程。
2. 子图检索模块
该模块旨在通过改进的子图提取和查询增强策略,从知识图谱中检索到更准确、更相关的子图。具体来说,该模块包括以下几个步骤:
向量数据库构造:首先,本文通过BFS从知识图谱中抽取若干子图。然后使用对齐的图编码器和文本编码器对其进行编码,并存储在向量数据库中。
查询增强:在进行子图检索时,本文提出了一种查询增强策略。通过在问题文本中进行实体链接,找到与问题相关的实体,并根据这些实体在知识图谱中检索到相关的三元组。这些三元组被添加到原始的问题文本中,作为查询的一部分。
子图检索:最后,本文使用余弦相似度等方法,根据增强后的查询,在子图向量数据库中检索到最相关的子图。
通过这个模块,SEPTA框架能够更准确地检索到与问题相关的子图,为后续的知识融合和推理提供更丰富的信息。
3. 预测模块
该模块旨在结合检索到的子图和问题文本,通过多头注意力等机制,进行有效的知识融合和推理,并最终生成回答。具体来说,该模块包括以下几个步骤:
知识融合:首先,本文使用多头注意力机制,将检索到的子图向量与问题文本的嵌入进行融合。这种方式能够将子图中的知识与问题文本中的信息进行有效的结合。
推理:在知识融合的基础上,预测模块使用一个线性层来对融合后的信息进行推理,并生成最终的回答。
通过这个模块,SEPTA框架能够根据检索到的子图和问题文本,进行有效的知识融合和推理,并生成准确的回答。
03 实验
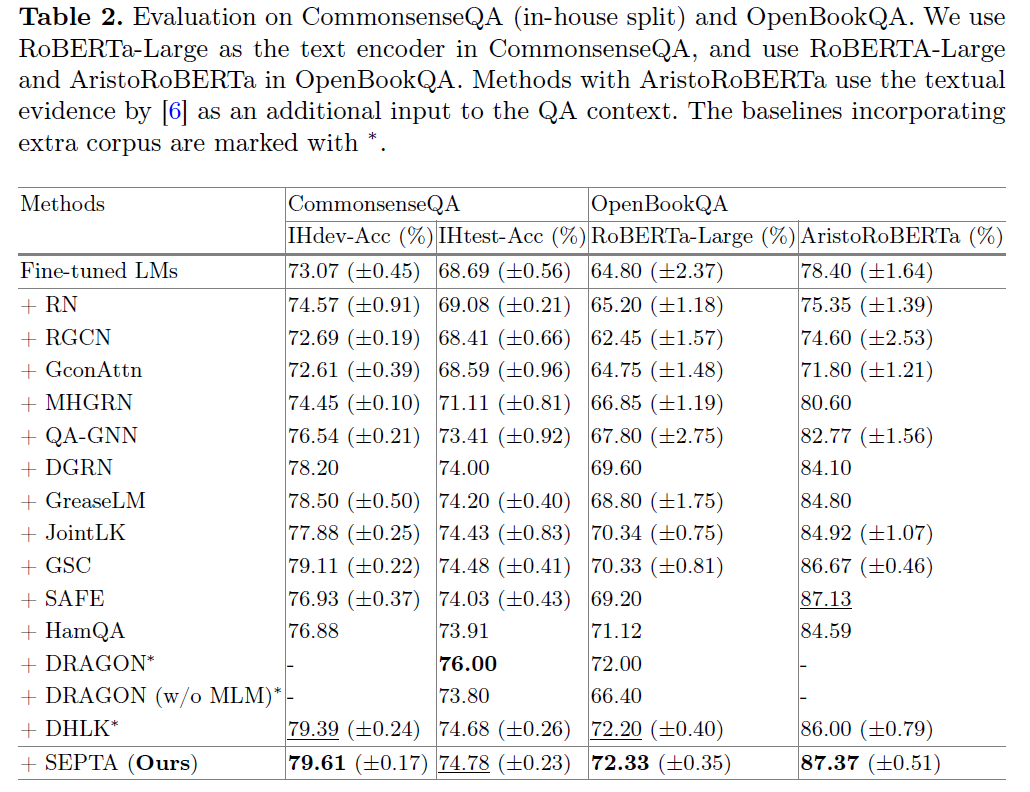
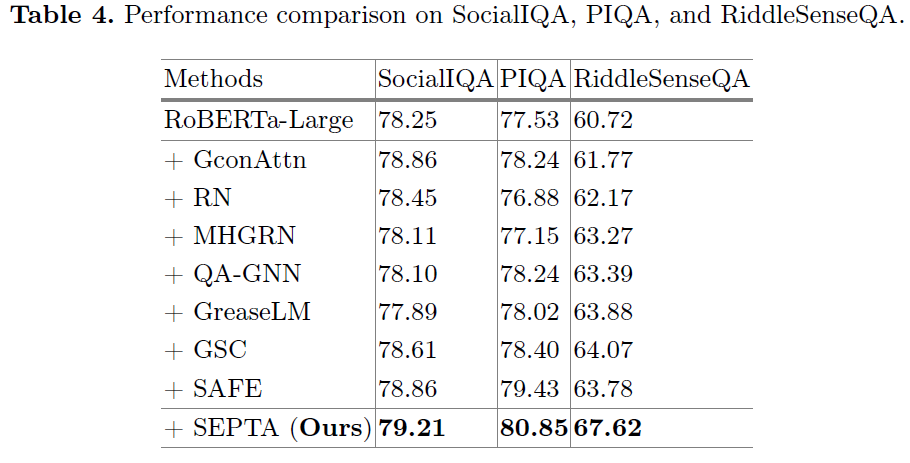
本文在五个常识问答数据集(CommonsenseQA、OpenBookQA、SocialIQA、PIQA、RiddleSenseQA)上进行了广泛的实验,使用ConceptNet作为知识图谱。

实验结果显示,在所有数据集上,相比于没有引入额外知识的方法,SEPTA都取得了最好的性能。而相比于使用额外语料库的基线模型,SEPTA也取得了可比的性能。
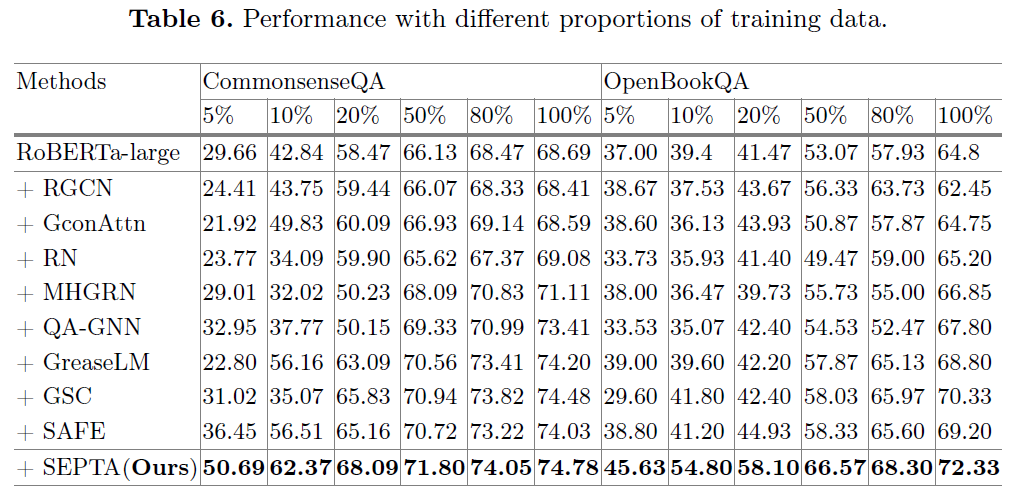
此外,为了评估SEPTA的鲁棒性,本文使用不同比例的训练数据(5%、10%、20%、50%和80%)在低资源设置下进行了实验。实验结果表明,SEPTA在所有设置下都表现出良好的性能,并且当训练数据较少时,SEPTA的性能优势更加明显。
04 总结
本文提出了一个名为SEPTA的新颖框架,用于常识问题回答。该框架通过图-文本对齐和子图检索来增强知识的表示和融合,从而提高了任务的性能。实验结果表明,SEPTA在多个数据集上都取得了更好的性能,并且具有较强的鲁棒性。这个框架为常识问题回答提供了一个新的思路,并为未来的研究提供了基础。


欢迎关注TuGraph代码仓库✨
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics
