今天分享的是一篇在 Meta KDD CUP 2024 中获得第三名的方案: WeKnow-RAG: An Adaptive Approach for Retrieval-Augmented Generation Integrating Web Search and Knowledge Graphs WeKnow-RAG: 一种集成网络搜索和知识图谱的自适应检索增强生成方法论文链接:https://arxiv.org/pdf/2408.07611
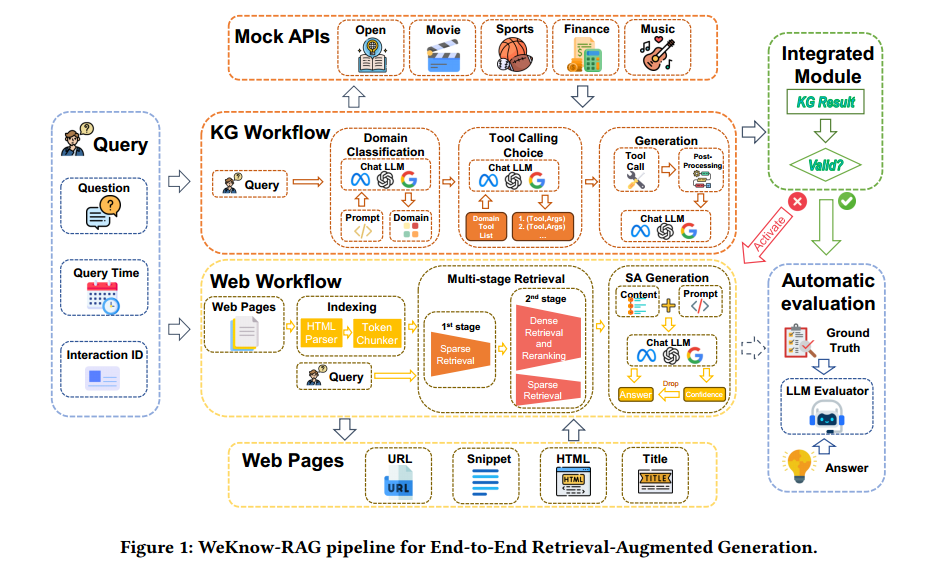
摘要 本文提出了一种名为 WeKnow-RAG 的新方法,其将网络搜索与知识图谱集成到“检索增强生成 (RAG)”系统中。该方法通过结合知识图谱的结构化表示与密集向量检索的灵活性,提升了 LLM 回答的准确性和可靠性。具体而言,本文采用多阶段网页检索方法,结合稀疏和密集检索技术,以平衡检索的效率和准确性。此外,其引入自我评估机制,帮助模型评估生成答案的可信度,从而减少虚假信息。最后,采用一个自适应框架,智能地结合基于知识图谱和网页检索的 RAG 方法。 方法 本文提出了一种名为WeKnow-RAG的端到端检索增强生成方法,如图1所示。该方法主要包括一个基于网络的工作流,一个基于知识图谱的工作流和集成方法三部分。下面将详细介绍每个部分。 Web-based RAG:基于网络的检索增强生成
1. Web Content Parsing (网络内容解析)
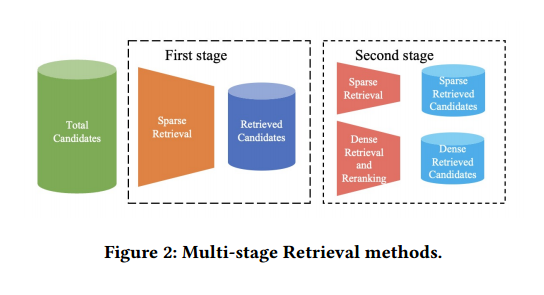
使用BeautifulSoup库解析原始HTML源代码,提取网页内容,获取结构化数据。 采用基于token的分块方法,将文档分成多个段落,以提高问答的性能。 3. Multi-stage Retrieval (多阶段检索) 为了平 衡查询检索相关段落的有效性和效率,本文采用多阶段检索策略,如图2所示。 使用稀疏检索(如BM25算法)从页面结果块和代码片段块中快速筛选候选文档。 使用将稀疏寻检索(BM25)与密集检索(嵌入相似度)结合的模式进行混合搜索,其中稀疏检索器擅长基于关键字找到相关文档,而密集检索器擅长基于语义相似度识别相关文档。密集检索方法包括密集嵌入检索和重排序方法。 4. Answer Generation with Self-Assessment (带有自我评估的答案生成) 本文提出了一种自我评估机制,用于评估生成答案的置信度并判断其是否适合被采纳。该机制指示大型语言模型(LLM)生成与答案对应的置信水平(高、中、低)。只有当置信度达到指定要求时,答案才会被接受。如果置信度低于设定的阈值,则认为 LLM 对回答该问题的置信度不足,并输出“I don 't know”。 Knowledge Graphs(知识图谱) 1. Domain classification (领域分类)
通过调用LLM将问题分类到相应的领域,如电影、体育、金融和音乐等。同时要求模型只有在确定性大于90%的情况下能够做出决定。当确定性低于这个阈值时,域被归类为开放领域。 2. Query generation (问题生成) 根据问题的领域分类结果,采用不同的提示词,通过LLM生成结构化的分析结果,进而解析成KG API兼容的结构化查询。 3. Answer Retrieval and Post-processing (答案检索和后处理) 通过API接口在KG上执行结构化查询来检索候选答案。采用基于规则的系统,利用机器学习技术来处理时间推理、数值计算和逻辑推理问题。通过这种混合方法,可以识别检索数据和问题假设之间的不一致性,有效地解决具有挑战性的假前提问题。 Integrated method(集成方法) 本文提出了一个自适应框架,根据不同领域的特点和信息变化速度,智能地平衡知识图谱(KGs)和基于web的RAG方法的使用。 对于信息变化速度小的领域,遵循KG Workflow输出的优先级规则,而不激活整个基于web的RAG Workflow。
对于信息逐渐变化的领域保持了KGs的首要地位,同时结合定期更新来捕获最新信息。更新频率由特定于领域的变化检测算法确定,该算法由LLM控制。
总结 WeKnow-RAG通过结合网络搜索和知识图谱,提出了一种新颖的检索增强生成方法。该方法开发了一个领域特定的知识图谱增强 RAG 系统,能够适应不同类型的查询和领域,从而提升事实和复杂推理任务的性能。同时,引入了一种多阶段的网页检索方法,利用稀疏和密集检索技术,有效平衡了信息检索的效率与准确性。此外,实施的自我评估机制进一步提高了整体回答质量。而且,该框架根据不同领域的特征,智能地结合了基于知识图谱和网页的 RAG 方法。最终,WeKnow-RAG 在不同领域和问题类型的准确性和减少幻觉方面取得了显着提高。