




检索增强生成(RAG)作为人工智能领域的重大进步,改变了聊天机器人与用户互动的方式。RAG将检索方法与生成式人工智能相结合,使聊天机器人能够从大型外部数据源中提取实时数据,并生成准确且相关的回答。这种创新简化了聊天机器人的开发流程,并确保其能够适应不断变化的数据,这对于客户支持等需要及时准确信息的领域至关重要。
然而,传统的 RAG 系统在需要快速决策的场景中(例如预约或处理实时请求)表现欠佳。Agentic RAG 应用通过引入智能体来解决这个问题。这些智能体能够自主地检索、验证和处理数据,赋予人工智能在行动中做出决策的能力。与主要用于检索数据和生成回答的标准 RAG 不同,Agentic RAG 应用更适合处理需要快速准确决策的复杂情况,例如医学诊断或客户服务。
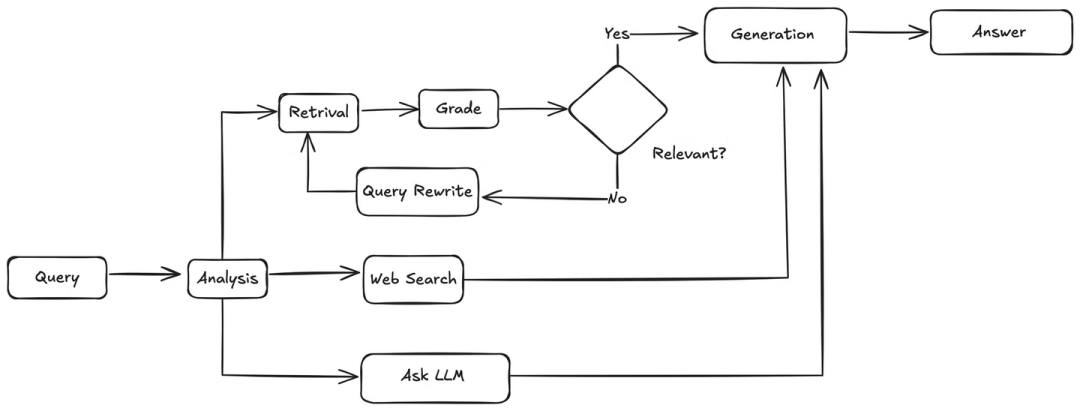
本文将构建一个智能的主动问答 (Q&A) 系统,该系统可以根据用户的查询动态决定是使用知识库还是进行互联网搜索。为此,我们将集成以下工具:
LangChain:作为系统的核心框架,LangChain 将管理系统与语言模型和其他工具的交互。它将根据用户查询,智能地选择搜索知识库还是互联网。
MyScaleDB:作为高性能向量数据库,MyScaleDB 将存储表示知识库的 embedding 向量。当用户查询与知识库相关时,系统将利用 MyScaleDB 高效地搜索和匹配相关信息。
VoyageAI:VoyageAI 提供多种 embedding 模型,用于从文本中生成 embedding 向量,从而更好地编码知识以进行搜索和匹配。
Tavily:当用户的问题需要最新或外部数据时,Tavily 将从互联网获取实时信息,确保系统始终提供准确的答案。
在开始构建 Agentic RAG 应用之前,你需要安装必要的 Python 库并获取所需的 API 密钥:
1. 安装 Python 库
pip install -U langchain-google-genai langchain-voyageai langchain-core langchain-community
这将安装 LangChain 及其相关组件,包括与 Google 生成式 AI、VoyageAI 和 MyScaleDB 交互的模块。
2. 设置 API 密钥
接下来是设置所需的API密钥以使用 Gemini(Google 生成式 AI)和 Tavily 搜索。对于 MyScale,用户可以按照此快速入门指南进行操作。
import os# MyScale API凭据os.environ["MYSCALE_HOST"] = "msc-24862074.us-east-1.aws.myscale.com"os.environ["MYSCALE_PORT"] = "443"os.environ["MYSCALE_USERNAME"] = "your_myscale_username"os.environ["MYSCALE_PASSWORD"] = "your_myscale_password"# Tavily API密钥os.environ["TAVILY_API_KEY"] = "your_tavily_api_key"# Gemini的Google API密钥os.environ["GOOGLE_API_KEY"] = "your_google_api_key"
请将上述代码中的占位符替换为你的实际 API 密钥。
注意:所有这些工具都提供免费版本以测试其功能。因此,可以在各自的平台上创建帐户并获取 API 密钥。
接下来,我们需要准备知识库数据。为了提高系统处理和检索信息的效率,我们需要将文本数据拆分成更小的块。LangChain 提供了 `CharacterTextSplitter` 工具,可以根据字符数量将文本拆分为可管理的块:
from langchain_text_splitters import CharacterTextSplitterwith open("myscaledb_summary.txt") as f:state_of_the_union = f.read()text_splitter = CharacterTextSplitter(separator="\\n\\n",chunk_size=1000,chunk_overlap=200,length_function=len,is_separator_regex=False,)texts = text_splitter.create_documents([state_of_the_union])
`CharacterTextSplitter` 根据字符计数将文本拆分成较小的可管理块。
注意:本文将使用一个包含 MyScaleDB 基本信息的 txt 作为示例。你可以根据实际需求替换为其他数据源。
完成文本数据拆分后,我们需要生成 embedding 向量并将它们存储到知识库中。我们将使用 VoyageAI 的 embedding 模型生成文本块的向量表示,并将它们存储在 MyScaleDB 数据库中:
from langchain_voyageai import VoyageAIEmbeddingsfrom langchain_community.vectorstores import MyScaleembeddings = VoyageAIEmbeddings(voyage_api_key="your_voyageai_api_key",model="voyage-law-2")vectorstore = MyScale.from_documents(texts,embeddings,)retriever = vectorstore.as_retriever()
`.from_documents` 方法会自动将文本文档转换为 embedding 向量,并将它们存储到 MyScaleDB 数据库中。
在 LangChain 中,工具是智能体可以利用的功能,用于执行超出文本生成的特定任务。通过为模型配备工具,它可以与外部数据源进行交互,获取实时信息,并为用户查询提供更准确和相关的答案。
在本应用程序中,我们为智能体开发了两个不同的工具,用于根据用户的查询决定使用哪个工具:
MyScaleDB 检索工具:
当查询与 MyScaleDB 或 MyScale 相关时,智能体将使用该工具从我们自定义的知识库中检索信息。我们可以使用 create_retriever_tool 方法将上面创建的 MyScaleDB 向量数据库转换为 LangChain 工具:
from langchain.tools.retriever import create_retriever_toolretriever_tool = create_retriever_tool(retriever,"retrieve_myscale_content","用于返回有关MyScaleDB的信息。",)
Tavily 搜索工具:
对于需要最新信息的其他查询,智能体将使用该工具执行实时互联网搜索。LangChain 通过其社区包提供了对 Tavily 搜索工具的内置支持:
from langchain_community.tools import TavilySearchResultstool = TavilySearchResults(max_results=5,search_depth="advanced",include_answer=True,name="live_search",description="用于搜索互联网上的最新新闻。",)tools = [retriever_tool, tool]
`TavilySearchResults` 工具被设置为查找最新的新闻,最多有 5 个结果和高级搜索深度,包括直接答案。最后,将这两个工具添加到一个列表中。
注意:每个工具的描述非常重要,因为它们帮助智能体确定何时以及如何使用每个工具。
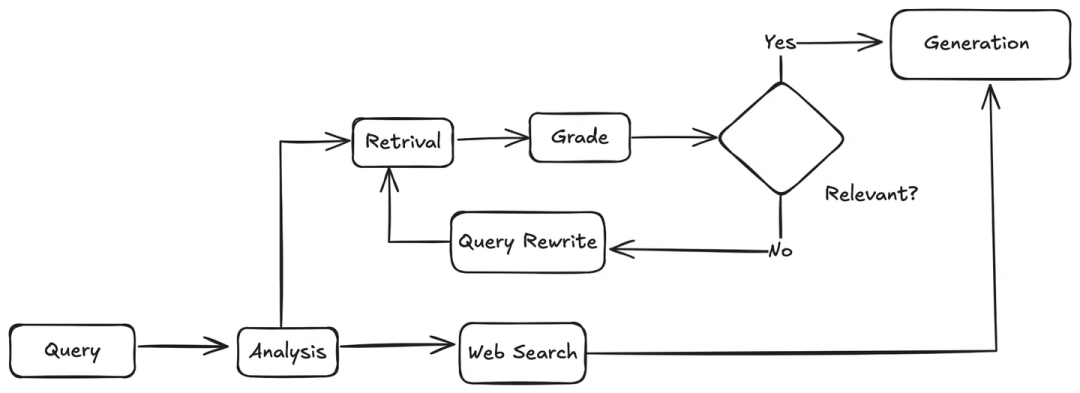
定义好所需的工具后,我们需要设计 Agentic RAG 应用的完整工作流程,包括具体步骤和执行的检查:
用户查询分析: 当用户提交查询时,智能体首先会对其进行分析,理解其意图和上下文。
工具选择: 根据分析结果,智能体将决定使用哪个工具来获取信息:
如果查询与 MyScaleDB 或 MyScale 相关,则选择 MyScaleDB 检索工具从知识库中检索信息。
如果查询需要最新信息或与知识库无关,则选择 Tavily 搜索工具执行实时互联网搜索。
信息检索:
MyScaleDB 检索工具: 智能体将使用用户查询作为检索条件,从 MyScaleDB 数据库中检索相关的文本块。
Tavily 搜索工具: 智能体将使用用户查询作为搜索词,调用 Tavily 搜索 API 获取实时互联网信息。
相关性检查 (仅限 MyScaleDB 检索工具): 对于从 MyScaleDB 检索到的文本块,智能体会进行相关性检查,确保检索到的信息与用户查询相关:
如果文本块相关,则直接进入步骤 5。
如果文本块不相关,则智能体会尝试对用户查询进行改写,并使用改写后的查询重新执行步骤 3。
答案生成: 智能体将检索到的相关信息(来自 MyScaleDB 或 Tavily)传递给大型语言模型 (LLM)。LLM 结合这些信息和用户查询,生成最终的答案。
# 标准库导入from typing import Literal, Annotated, Sequence, TypedDict# Langchain Core导入from langchain_core.messages import BaseMessage, HumanMessagefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_core.pydantic_v1 import BaseModel, Field# Langchain和外部工具from langchain import hubfrom langchain_google_genai import ChatGoogleGenerativeAI# LangGraph导入from langgraph.graph.message import add_messagesclass AgentState(TypedDict):messages: Annotated[Sequence[BaseMessage], add_messages]
def agent(state):messages = state["messages"]model = ChatGoogleGenerativeAI(model="gemini-1.5-pro",temperature=0,max_tokens=None,timeout=None,max_retries=2,)model = model.bind_tools(tools)response = model.invoke(messages)return {"messages": [response]}
智能体确保检索到的文档与用户的查询相关。`grade_documents` 函数将分析检索到的文档以检查其相关性。如果检索到的文档相关,智能体将决定生成答案;否则,它将重写用户的查询。
def grade_documents(state) -> Literal["generate", "rewrite"]:# 评分的数据模型class Grade(BaseModel):"""用于相关性检查的二进制分数。"""binary_score: str = Field(description="相关性分数 'yes' 或 'no'")# LLMmodel = ChatGoogleGenerativeAI(model="gemini-1.5-pro",temperature=0,max_tokens=None,timeout=None,max_retries=2,)llm_with_tool = model.with_structured_output(Grade)# 提示prompt = PromptTemplate(template="""你是一个评分员,正在评估检索到的文档与用户问题的相关性。这是检索到的文档:{context}这是用户问题:{question}如果文档包含与用户问题相关的关键词或语义意义,请将其评分为相关。给出一个二进制分数 'yes' 或 'no',以指示文档是否与问题相关。""",input_variables=["context", "question"],)# 链chain = prompt | llm_with_toolmessages = state["messages"]last_message = messages[-1]question = messages[0].contentdocs = last_message.contentscored_result = chain.invoke({"question": question, "context": docs})score = scored_result.binary_scoreif score == "yes":return "generate"else:return "rewrite"
def rewrite(state):messages = state["messages"]question = messages[0].contentmsg = [HumanMessage(content=f"""查看输入并尝试推理出底层的语义意图/含义。这是初始问题:-------{question}-------制定一个改进的问题:""",)]# LLMmodel = ChatGoogleGenerativeAI(model="gemini-1.5-pro",temperature=0,max_tokens=None,timeout=None,max_retries=2,)response = model.invoke(msg)return {"messages": [response]}#生成最终答案一旦确认检索到的文档与用户的查询相关,智能体将检索到的文档发送给最终答案生成。def generate(state):messages = state["messages"]question = messages[0].contentlast_message = messages[-1]docs = last_message.content# 提示prompt = hub.pull("rlm/rag-prompt")# LLMllm = ChatGoogleGenerativeAI(model="gemini-1.5-pro",temperature=0,max_tokens=None,timeout=None,max_retries=2,)# 链rag_chain = prompt | llm | StrOutputParser()# 运行response = rag_chain.invoke({"context": docs, "question": question})return {"messages": [response]}
from langgraph.graph import END, StateGraph, STARTfrom langgraph.prebuilt import ToolNode# 定义一个新的图表workflow = StateGraph(AgentState)# 定义我们将在之间循环的节点workflow.add_node("agent", agent) # 智能体节点retrieve = ToolNode([retriever_tool])workflow.add_node("retrieve", retrieve) # 检索节点search = ToolNode([tool])workflow.add_node("search", search) # 搜索节点workflow.add_node("rewrite", rewrite) # 重写节点workflow.add_node("generate", generate) # 生成节点
`add_node` 函数将节点添加到图表中。第一个参数是节点的名称,第二个参数是它所代表的函数。
在 LangGraph 中,节点代表不同的处理步骤,而边缘定义了基于特定条件的节点之间的转换关系。边缘控制着应用程序的完整流程。
为工具定义条件边缘
首先,我们需要定义一个条件判断节点,根据用户的查询选择使用 MyScaleDB 检索工具还是 Tavily 搜索工具。如果查询中包含关键词 “myscaledb” 或 “myscale”,则认为用户查询与 MyScaleDB 相关,智能体将使用 MyScaleDB 检索工具;否则,智能体将使用 Tavily 搜索工具。
def tools_condition(state) -> Literal["retrieve", "search"]:messages = state["messages"]question = messages[0].content.lower()if "myscaledb" in question or "myscale" in question:return "retrieve"else:return "search"
添加边缘
现在,将边缘添加到工作流图中。
workflow.add_edge(START, "agent")workflow.add_conditional_edges("agent",tools_condition,{"search": "search","retrieve": "retrieve",},)workflow.add_conditional_edges("retrieve",grade_documents,)workflow.add_edge("retrieve", "generate")workflow.add_edge("search", "generate")workflow.add_edge("generate", END)workflow.add_edge("rewrite", "agent")# 编译图表graph = workflow.compile()
`add_edge` 函数定义了从一个节点到另一个节点的直接转换。`add_conditional_edges` 函数允许我们根据条件指定转换。第一个参数是源节点,第二个参数是条件函数,第三个参数是一个字典,将可能的条件结果映射到目标节点。
现在,我们来可视化最终的图表,看看节点和边缘是如何连接的。
from IPython.display import Image, displaytry:display(Image(graph.get_graph(xray=True).draw_mermaid_png()))except Exception:# 这需要一些额外的依赖项,是可选的pass
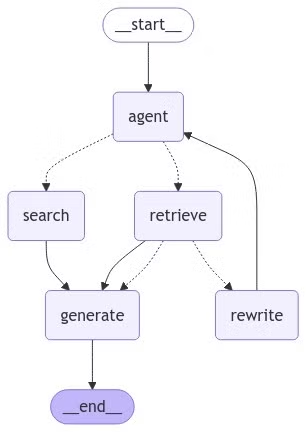
执行图表
最后,执行图表,看看我们的问答系统如何运作。
inputs = {"messages": [("user", "OpenAI最近发布了哪个模型?"),]}for output in graph.stream(inputs):for value in output.items():print(value["messages"][0], indent=2, width=80, depth=None)
它将生成如下输出:
OpenAI最近发布了一个名为 OpenAI o1 的新生成AI模型。这个模型在“推理”能力方面表现出色,可以自我核实事实并解决编码和数学等复杂问题。它于2024年9月12日发布,适用于 ChatGPT Plus 和 Team 用户。
当进行关于 MyScaleDB 的查询时,如下所示:
inputs = {"messages": [("user", "什么是MyScaleDB?"),]}for output in graph.stream(inputs):for key, value in output.items():print(value["messages"][0], indent=2, width=80, depth=None)
输出将类似于:
"MyScaleDB 是一个基于开源 ClickHouse 构建的高性能云数据库,专为人工智能和机器学习应用而设计。它支持结构化和非结构化数据,非常适合管理大量数据和执行复杂的分析任务。"
结论
现在,你已成功构建了一个动态的问答系统,它能够根据用户查询智能选择使用知识库还是执行实时互联网搜索。通过集成 LangChain、MyScaleDB、VoyageAI 和 Tavily 等工具,这个适应性强的 AI 智能体能够高效处理复杂问题。如果感兴趣的话, 你可以继续探索这些工具,以进一步增强你的 AI 应用程序!
了解墨奇科技 点击更多资讯

