




背景
PolarDB-X V2.4 版本新增支持了列存查询加速能力,在成本低廉的 OSS 存储底座上,构建了一套成熟的列存 SQL 引擎,为查询分析提供了更为优越的性能、更高的成本效益以及查询加速能力。
列存查询加速基于存算分离的架构:列存引擎(Columnar)负责列存索引的构建,实时消费分布式事务的 binlog,同步到列存索引并持久化到 OSS 存储;计算引擎(CN)负责列存查询和事务管理。对于一条列存查询,CN 需要从远端的 OSS 存储拉取对应的数据进行 MPP 计算。在享受存算分离架构带来的便利和可扩展性的同时,我们也面临着新的挑战,查询的一致性和兼容性正是其中之一。围绕这一点,我们做了大量的工作来保障列存查询的一致性、新鲜度以及兼容性。
一致性快照构建原理
列存索引存储模型
在介绍列存一致性快照读的原理前,我们需要先了解列存索引的存储模型:
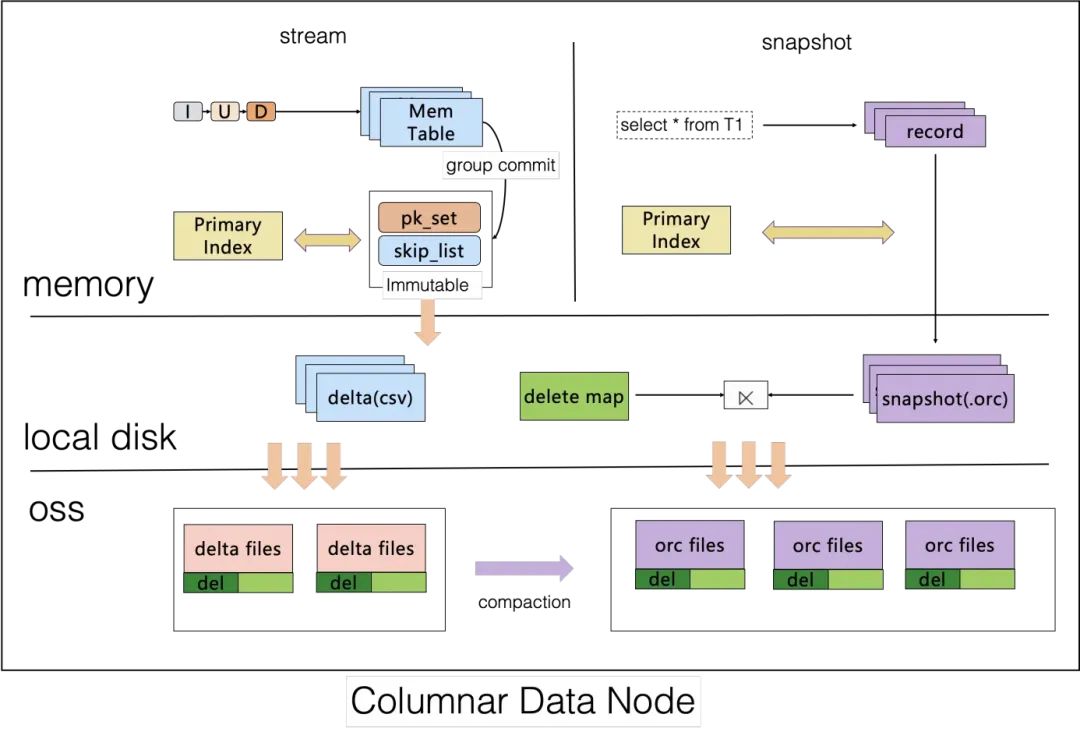
PolarDB-X 列存索引的存储采用 Delta + Main + 标记删除的组织结构(Delete-and-Insert),构建的数据会以 CSV + ORC + Delete bitmap 的格式存储在 OSS 上。
其中,CSV 和 Delete bitmap 支持追加写入,增量数据的 Update 操作会拆分为 Insert + Delete,在每个 Group commit 周期内,Insert 数据将会追加写到 CSV 的尾部,Delete 操作将会通过主键索引找到删除的数据对应的位置,生成对应的 bitmap 追加写到 Delete bitmap 尾部。在增量数据超过一定阈值时,列存引擎会异步地进行 compaction,将增量文件转储为查询友好的 ORC。
相较于 Copy-on-Write 和 Merge-on-Read,这一模式既实现了行存到列存数据的低延迟同步,也不会对查询侧引入过大的额外开销。
关于列存索引构建的更多细节,可以参考:PolarDB-X HTAP新特性 ~ 列存索引
列存索引版本链和多版本并发控制
列存引擎的每次 Group commit 追加写和 Compaction,都意味着一个新版本的列存快照对外可见,每个快照由 TSO (Timestap Oracle) 唯一标识。每生成一个列存快照,列存引擎都会将这个快照的信息写入 GMS,包括 TSO、追加写入的文件位置和长度、Compaction 删除和新增的文件等。这些列存快照在逻辑上构成了列存的版本链,如下图:

PolarDB-X 的列存查询同样需要考虑多版本并发控制。不同于行存的是,列存索引的写请求来自于内部的列存引擎节点,只有读请求是直接来自于用户,因此可以简化为如下模型:

其中,列存引擎的 Group commit 和 Compaction 会通过两阶段提交的方式不断延长版本链,在 prepare 阶段在版本链上申请一个新的版本,在增量数据完全写入到 OSS 后,进行 commit,使版本链上的这个节点对外可见。另外,为了防止版本链无限延长,列存引擎还会发起 purge,清理过旧的版本,释放 GMS 和 OSS 的空间。
而列存查询引擎需要对外提供并发的查询能力。MPP 集群中的 leader CN 会主动感知版本链的新版本,并广播到其余的 CN,使得不论哪个 CN 承接流量都能查询到该版本的列存快照。用户的每条列存查询会随机路由到一个 CN,随后,该 CN 会作为 MPP 查询的协调者(Coordinator),在版本链上找到当前可见的最新列存版本,构建列存 ReadView。一个列存 ReadView 包含了 TSO、该版本对应可见的文件列表以及增量文件的可见位点。随后,协调者会根据 ReadView 构造列存 Scan 算子,并将这些文件的 Scan 任务根据一定的规则下发到所有计算节点(Worker)。基于按文件哈希和按分区哈希的调度规则,我们保证了每个计算节点的本地缓存亲和性,这一特性将在下一章展开介绍。
为了防止快照被过早地清理而导致查询失败,Leader CN 会定时收集所有 CN 上活跃的列存 ReadView,得到列存活跃事务的下水位线,并通知列存引擎低于该下水位线的版本才可以被清理。
基于列存索引的版本链,我们还提供了一致性行列混合快照的能力。由于列存 Group commit 机制的存在,列存的一次追加写对应多个行存的事务,因此在行列混合查询时,为了保证行存和列存快照的一致性,我们以列存快照的最新 TSO 为准,借助行存 innodb 存储的 MVCC 机制,在行存上使用该 TSO 进行快照读。
快速构建 MPP 一致性快照
不同于存算一体的系统可以原地利用写缓存查询增量数据,PolarDB-X 的计算节点在查询增量数据时,依然需要从远端 OSS 拉取数据,这要求我们更精细化地设计缓存系统,以降低列存查询的延迟,提升用户体验。为了优化列存一致性快照的构建效率和查询效率,我们引入了亲和性缓存,采取了多种优化手段,来加速快照信息的构建和增量数据的查询。
具有节点亲和性的缓存
列存查询引擎的本地缓存采取了内存 + 本地磁盘的多级缓存,包括:
ORC block cache + 本地磁盘文件片段缓存
文件元信息缓存
增量数据的多版本缓存 (多版本的 CSV + 多版本的 delete bitmap)
列存 ReadView 缓存
对于一条 MPP 列存查询,协调者会基于列存 ReadView 构造每个 Scan 算子需要扫描的文件任务。为了最大化利用每个计算节点的本地缓存,最小化 cache miss 概率,我们需要保证缓存的节点亲和性,即对于所有的列存查询,同一个文件的 Scan 任务尽可能地调度到同一个计算节点。
此外,对于增量数据,我们针对其特性设计了多版本的缓存数据结构,以优化增量数据的读取开销,缓存整体设计如下:

相对固定的调度算法,保证缓存的节点亲和性
在进行 Scan 任务的调度时,针对不同的场景,我们引入了两种调度算法:
分区级别哈希,进行存储计算一致的路由调度。在理想情况下,我们希望最小化数据在计算节点间的 shuffle 代价,例如在进行 join 时,我们希望将 join key 相同的数据分片调度到同一个节点进行计算,在保证结果正确的同时减少数据的传输代价。因此,我们采取了存储和计算一致的分片路由算法,使得同一个分区的数据无需进行额外的 shuffle 即可直接对接下游的算子。基于这一前提,我们固定分片的路由逻辑,使同一分区的 Scan 任务固定路由到某个 CN 上。详细介绍可以参考:PolarDB-X列存查询引擎
文件级别哈希,按照文件名哈希调度到固定的 CN。对于查询命中单个分区或者分区间数据倾斜严重的场景,分区级别调度将会产生长尾现象。因此,协调者会计算分区级别调度的倾斜程度,针对分区级别调度退化的场景,我们会采取文件级别调度的策略,对文件名使用固定的哈希算法进行打散,保证同一文件固定调度到某个 CN 上。
对于任意一条 MPP 查询的 Scan 算子,其调度逻辑一定会命中这两者的其中之一。由此可得,在缓存空间足够大的情况下,任何一份数据至多只会产生两次 cache miss。得益于这一调度机制,PolarDB-X 的列存查询面对不同负载都能自适应调整调度逻辑,同时保证了一定的缓存节点亲和性。
CSV 多版本缓存设计
为了保证写入的性能和查询的新鲜度,增量数据采用了可追加写的 CSV。正由于其按行存储的特性,查询性能天然劣于 ORC,另一方面,CSV 文件反映了最新写入的增量数据,其查询性能直接影响了用户列存查询的使用体验。倘若在增量文件读取时出现瓶颈,在用户侧就会反映为有数据写入时查询性能的抖动。为此,我们在 CSV 缓存的设计上尽可能地进行数据复用,同时用空间换时间,在计算节点将按行存储的 CSV 转为按列存储的 Chunk 缓存,以减小增量数据读取的代价。
基于 CSV 的追加写特性,如 T0 快照的 CSV 文件包含 2700 行数据,T1 快照追加写了 300 行,T2 快照又追加写了 200 行。那么对于 T2 的查询和 T3 的查询,其前 2700 行数据和前 3000 行数据的缓存是可以复用的。因此,我们使用了分段进行多版本缓存的思路,尽可能进行缓存复用,整体设计如下图所示:

CSV 缓存使用跳表维护多版本的缓存节点,在叶子节点,指向对应版本追加的所有 Chunk。在查询引擎中,数据和中间结果均以 Chunk 的形式存储,默认情况下,每个 Chunk 包含 1000 行数据,按列组织在内存中。CSV 缓存直接保留 Chunk,使得执行器可以直接利用缓存数据,省去了 CSV 行转列的开销。基于上图的缓存结构,我们主要介绍查询、加载新版本和缓存 Purge 这 3 个流程的处理逻辑:
查询:用户查询某个版本的数据时,如 T2,则通过跳表找到这一版本的叶子节点,按顺序返回从最早的版本到该版本追加的所有 Chunk,即得到这一版本对应的数据。
加载新版本:当用户查询到尚未加载的新版本数据,或计算节点进行缓存预热时,需要加载新版本。此时,计算节点会从远端拉取追加的 CSV 部分,解析后转为 Chunk,同时在跳表中新增该节点。
缓存 Purge:如果每次追加写的数据量较小,则会生成很多版本,每个版本的 Chunk 行数都很小,导致内存碎片,同时也会无法利用列式计算的优势。因此,对于不会被查询的旧版本缓存,我们会定期进行 Purge 和整合,将碎片 Chunk 整合为大 Chunk。对于已删除的 CSV 文件,则会直接从缓存中剔除。
Delete bitmap 多版本缓存设计
对于删除操作,列存引擎会通过主键索引找到这一批删除操作对应的所有删除位置,即删除的是哪一个文件中的第几行,按照文件聚合后,生成一个 bitmap。在这里,我们选择了 RoaringBitmap 作为存储结构,在我们的 benchmark 测试中,其具有较高的压缩率和良好的性能。生成对应的 RoaringBitmap 后,列存引擎会将其序列化,按照固定的格式追加写入 Delete Bitmap 文件,供查询引擎拉取使用。与 CSV 类似地,Delete bitmap 的缓存也采取了多版本的设计思路,整体设计如下图所示:

对于 Delete bitmap 的多版本缓存,与 CSV 缓存类似,我们同样会先从文件中加载和解析每个版本追加删除的 RoaringBitmap,以及其对应的文件(File ID)和版本(TSO),在内存中以链表或跳表的形式组织起来。但在生成某个版本的 Bitmap 时,我们并不是合并在该版本前的所有增量 Bitmap,而是先在内存中维护一个最新的 Bitmap T,再减去(逻辑异或)与最新版本的相差的这几个版本的 Bitmap。由于用户查询的一般都是较新版本的数据,这一优化在版本链很长时优化明显。
在进行列存查询时,我们需要将 ORC 或 CSV 的数据和 Delete bitmap 进行合并,删除对应的行,以得到正确的快照数据。如图,当我们需要 File ID 为 2 的文件在 T1 时刻的快照时,将 Bitmap T 减去 Δ3 和 Δ2,得到了 T1 版本的 Bitmap,再将其应用于 Chunk 上,即生成了 T1 时刻的快照。
整体接入内存管理和 spill,防止大查询拖慢整体性能
对于上述这些缓存,我们会统一纳入内存管理机制,防止过多耗内存的大查询和一些常驻的缓存拖垮整体的性能。当内存不足时,计算节点会触发 spill,将缓存落盘,释放内存。详细介绍可以参考:PolarDB-X 如何用 15M 内存跑 TPC-H 1G?
数据预热
列存查询引擎的缓存通过空间换时间的方式,优化了从远端拉取数据的代价,加速了列存快照的生成和查询。但需要注意的是,当有新数据写入,用户查询这一新版本的数据时,由于缓存中尚未加载这一版本的数据,必然发生 cache miss,因而只能从远端 OSS 拉取新数据。这一问题会导致列存查询的性能抖动,每当新数据写入,对应列存索引上的查询就会由于 cache miss 卡顿一下,这会极大影响用户体验。因此,我们引入了数据预热机制,主动从 OSS 拉取元数据和增量数据到计算节点的本地磁盘和内存缓存中。目前,这一特性正在灰度中,未来会正式上线。
增量数据的旁路加载
列存引擎在处理增量数据时,为了减少网络 IO 次数,提升上传效率,会先将数据攒批落盘到本地,再上传到远端的 OSS。因此,对于比较新的增量数据,除了持久化在 OSS 之外,列存引擎的本地磁盘上也保留了一份缓存。由于 OSS 的 Appendable Object 相较于普通文件在首次拉取新写入的内容时存在较大的延迟,为了进一步加速增量数据的查询,我们引入了旁路加载的机制。即计算节点拉取数据时,如果列存引擎的本地磁盘中存在该数据,则直接通过内部的网络请求拉取数据,不再从 OSS 拉取。如下图红色虚线标识的链路。旁路加载的特性会在未来的版本正式上线。

高级特性之列存闪回查询(Flashback Query)
基于列存版本链和高效的列存快照生成技术,我们可以很自然地在列存索引上实现闪回查询。默认情况下,用户只能查询最近一段时间内的数据,即尚未被列存引擎清理的快照。对于有闪回查询需求的用户,可以开启列存快照保存功能,手动或自动地保存指定时间点的列存快照,使这一版本的快照不被清理。在闪回查询时,用户可以指定时间或 TSO,列存查询引擎将在版本链上找到与指定时间最接近的一个版本,构建列存快照进行查询。由于闪回查询不同于常规的业务流量,不具有时间上的局部性,因此列存查询引擎在进行闪回查询时会绕过主链路上的缓存,直接从远端拉取数据进行查询,避免缓存污染。这一特性将在后续的文章中详细介绍,敬请期待。
兼容性之 DDL 下的列存查询
多版本列存 Schema

目前,PolarDB-X 的列存索引已经支持了 Schema 多版本的能力,详细介绍见:PolarDB-X列存索引全面支持Schema多版本
列存索引在进行 DDL 时,不会立即进行物理文件的类型转换和整合,而是通过多版本 Schema 的方式,维护一个新版本的 Schema,新写入的数据以新 Schema 的格式进行存储。在查询引擎中,我们维护了多版本 Schema 到具体的 ORC/CSV 文件的映射关系。查询时,若扫描到最新版本的数据,则直接解析返回结果;若扫描到旧版本的数据,则在解析数据时进行列映射、类型转换和默认值填充。在这一机制的基础上,我们未来可以提供 Schema Traversal 能力,即恢复出指定时间的 Schema,或按照指定时间点的 Schema 查询数据。
列存 Schema Compaction
DDL 是数据库的家常便饭,对于许多快速迭代的业务系统,频繁的 DDL 是在所难免的。基于上文的异步 DDL 方案,不难看出,列存查询的代价和 DDL 的次数正相关,尤其是当用户反复修改同一列的列类型时,最早一个版本的数据需要进行多步的类型转换,这是难以接受的。因此,列存的 Compaction 任务同时也会对旧版本数据进行类型转换,将所有的旧版本 Schema 转换为最新版的 Schema,保证同一个版本的快照中不会存在过多版本的 Schema,降低了后续列存查询的开销。
全类型兼容性
基于 MySQL 生态,PolarDB-X 的列存查询提供了和行存一致的类型兼容性。对于 CSV 文件,我们采取了兼容 MySQL 原生 Binlog Write_rows_log_event 的存储格式,在查询时进行解析。对于 ORC 文件,由于原生的 ORC 格式与 MySQL 类型系统并不直接兼容, 因此我们进行了大量的改造和优化,尤其是针对 Decimal、时间类型、字符串等类型,在提高压缩率的同时,保证了和 MySQL 类型的兼容性。
在发生 DDL 后,列存查询引擎需要在查询时进行类型转换,为了保证和行存一致的 MySQL 兼容性,我们忠于 MySQL 的逻辑,妥善处理了数值精度和数据截断等问题。
