业务架构设计里面最重要的一环就是数据库模型设计,由于单机计算和存储能力的限制,很多业务架构师不得不考虑对大表进行拆分,通过中间件或者其他手段进行分库分表,实现资源扩展的能力,因此很多时候,MySQL生态中流传的是单表不要超过500万行。一般来说,分库分表解决方案解决了如下问题:
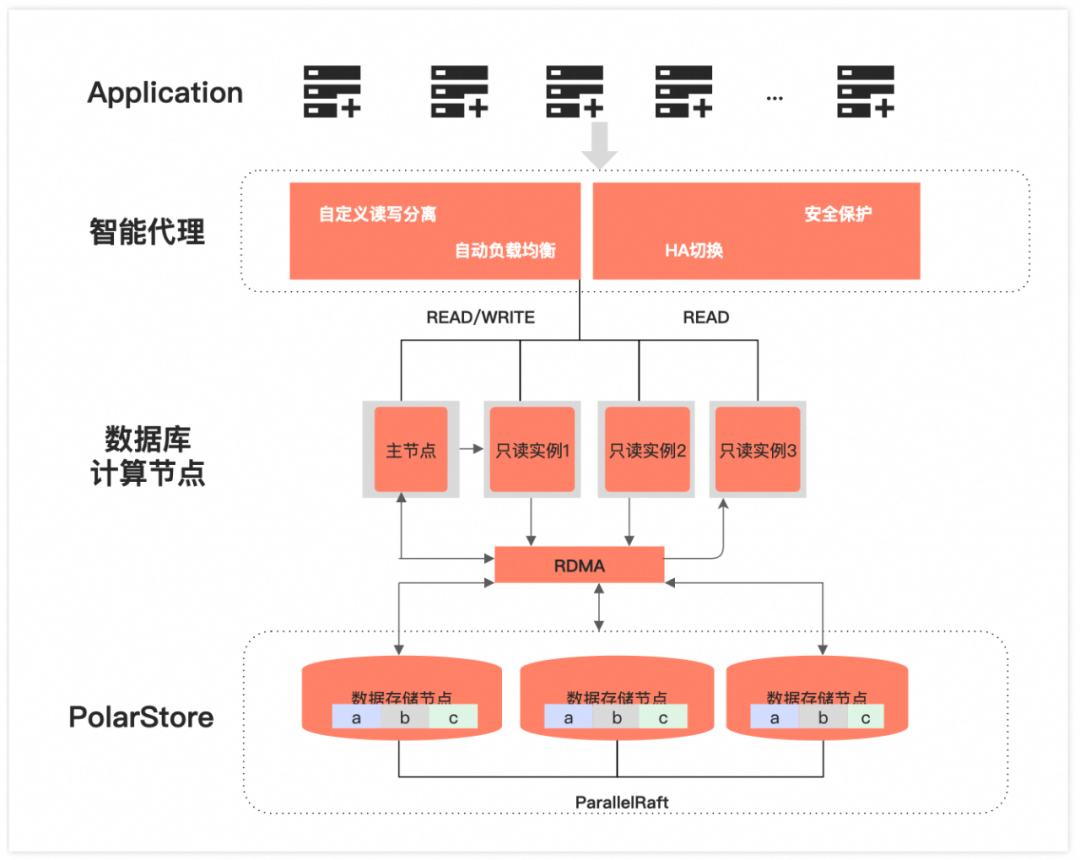
随着数据量的日益增长,运维团队为了确保业务的稳定性,不得不开始考虑数据拆分的问题。由于分库分表带来的兼容性挑战,业务代码也需进行相应修改,这意味着开发团队需要参与架构改造,并重写SQL语句以适应新的分库分表结构。业务团队往往将重点放在业务发展上,在此期间难以抽出精力进行系统的拆分。这导致拆分工作只能不断推迟,直到最终不得不执行。在此期间,整体系统的稳定性始终面临风险。在MySQL生态中,通常建议单表的行数不超过500万行,这一准则背后有其深厚的历史背景。资源方面来说,早期服务器 IO 能力比较低,单表过大会增加 B-tree 索引的高度,进而导致 IO 问题。同时磁盘容量也比较低,要考虑存储上限以及备份空间的问题。从运维层面来说,旧版本MySQL(5.5以前)基本不支持在线DDL,在对大表进行维护时,可能会导致业务异常。阿里云瑶池旗下的云原生数据库PolarDB采用共享分布式存储架构,与传统MySQL数据库相比,提供了显著更强的大表处理能力。许多传统的分库分表场景变得不再必要。目前,PolarDB公共云已有大量用户的单表数据超过10 TB或10亿行。分库分表相较于单表会带来极大的复杂性提升,因此,在非必要的情况下,不应过早进行过度优化。很多业务在快速发展阶段,开始考虑数据拆分的原因其实并不是计算能力遇到了瓶颈,而是海量数据的存储到达了单实例上限,但是由于最初设计的时候没有考虑到海量数据的使用方式,或是在业务逻辑中,数据无法进行清理或归档。PolarDB采用了计算存储分离和共享分布式存储架构。相比于传统针对单机系统设计的MySQL,分布式的存储设计让 PolarDB 的实例目前最多支持 1 PB 的存储空间,PolarDB的存储是由一组Chunk Server通过 RDMA 硬件连接在一起(PFS技术), 对上层提供块设备接口,而计算节点通过RDMA网络将存储挂载到计算节点中,从上往下看,底层的Chunk对于计算是完全透明的。近乎海量的存储空间,用户不用苦恼于磁盘容量限制和扩缩容问题,只需专注于业务的需求设计,并且不用进行分库分表的数据拆分,极大减轻了业务系统的复杂程度。
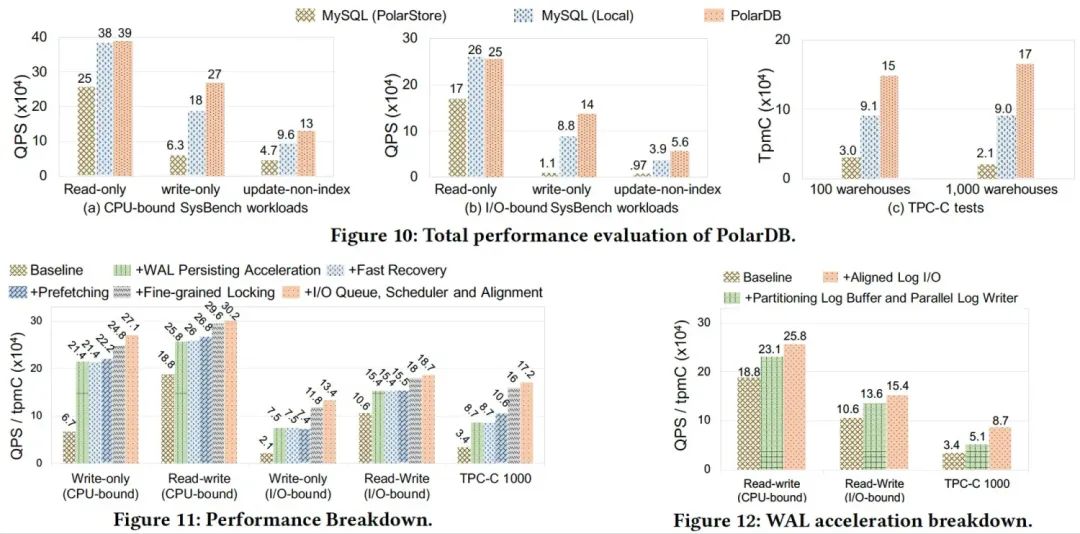
限制单机实例的其中最大因素之一是大表的性能问题,为了让大表不再成为数据库使用的瓶颈,PolarDB 做了大量的探索和验证。针对大表插入场景的痛点,我们研究了引入瓶颈的各个模块机制,进行了相应的优化,通过基准测试和实际业务场景验证,最多能有 10 倍性能提升,其中包括:PolarDB 优化了单实例的索引大锁,创新性提出了允许并发分裂的 Polar Index,这优化了大量并发访问的冲突开销。在某一个线上业务实际场景中,性能能够有3倍的提升,在TPCC 场景下更是能够有11倍的性能提升。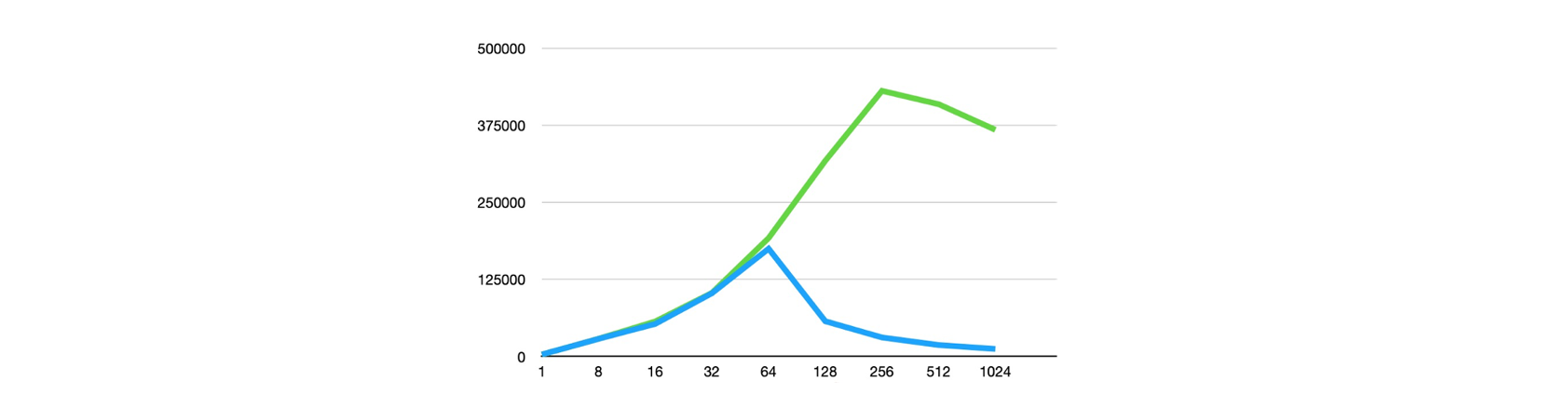
随着数据的持续写入,数据表文件的扩展是不可避免的。高频的数据插入,同样会增加了表空间扩展的频次。在 MySQL 中,表空间扩展是一个很“重”的操作,高频的操作会直接影响到事务的执行性能。为了优化大表插入场景下,文件扩展的开销,PolarDB 基于底层自研分布式文件系统,在表文件扩展的过程中,最低程度修改文件系统元信息,使得文件扩展中,锁开销不再成为瓶颈。这极大程度提升了 PolarDB在数据大批量写入场景下的性能。
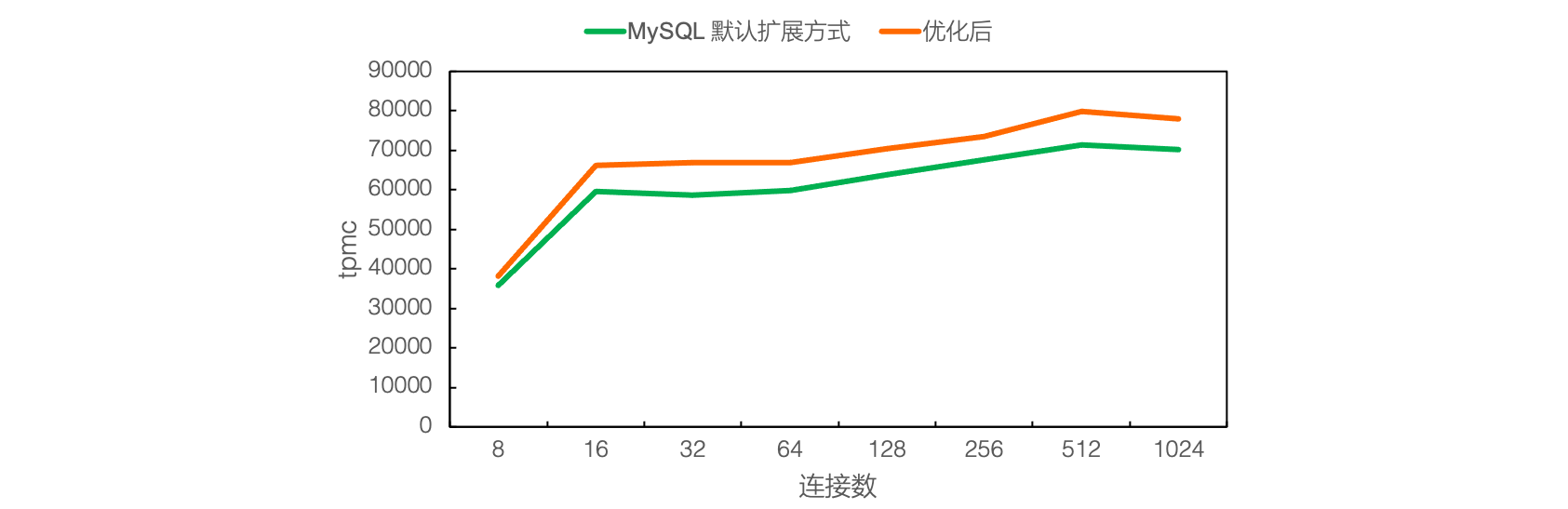
高负载的插入,必然伴随着大批量Redo日志的产生,为了保证事务的持久性,需要在Redo日志都落盘后,事务才可以返回,因此Redo日志写入的延迟和吞吐是直接影响数据库性能。PolarDB创新性提出了Redo并行写入机制,解决大表日志落盘痛点,当前Redo最高吞吐达到 4GB/s,单实例 IO 吞吐极限能到 5.2GB/s。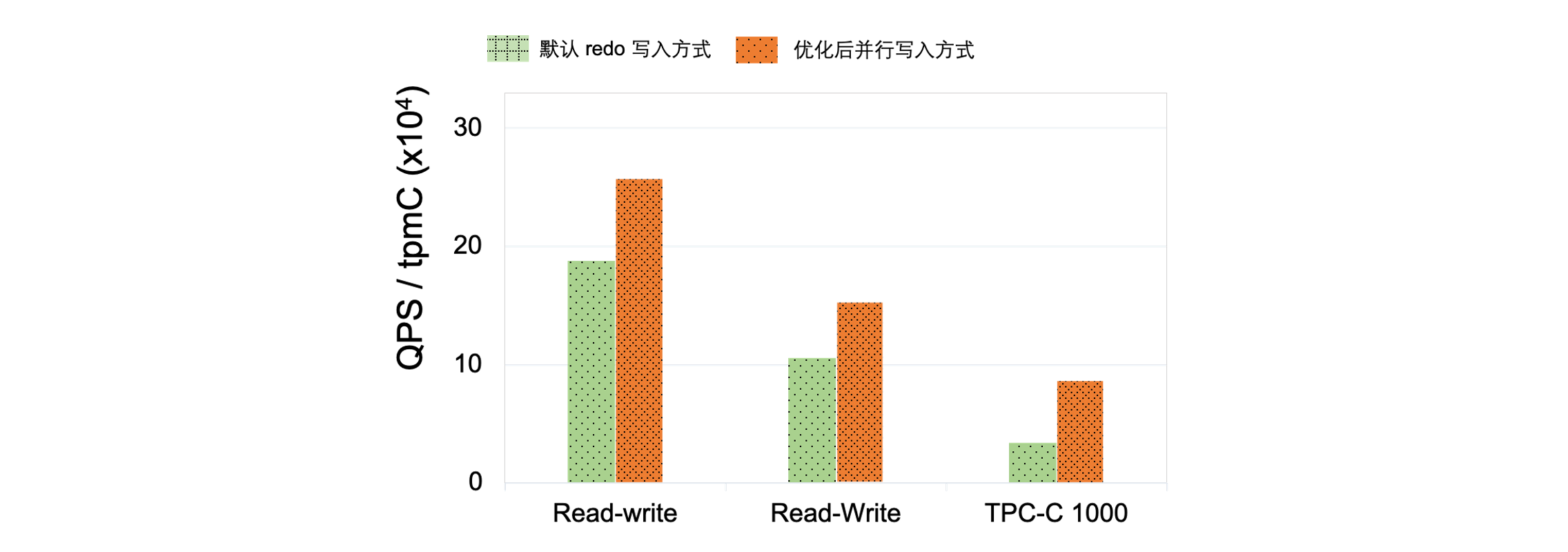
▶︎ 2.2.4 逻辑预读、IO 调度、并行二级索引插入优化等整体来看,针对云上数据库痛点(结合线上经验与系统实验),PolarDB在单实例大表的性能满足绝大部分的业务需求。▶︎ 2.2.5 性能数据
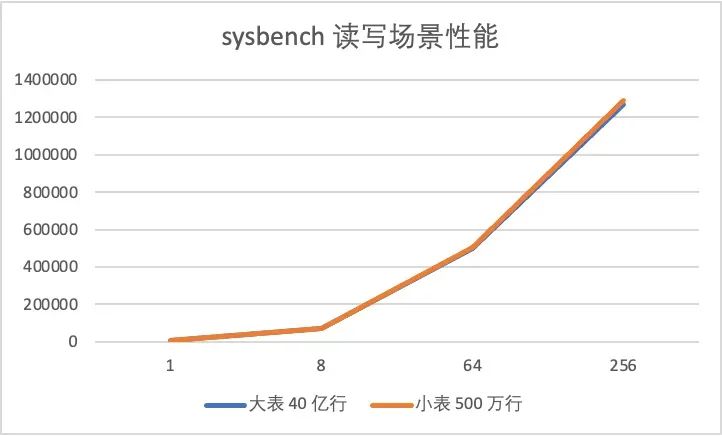
我们分别用 sysbench 插入 400 亿行数据(10 TB),作为对照,PolarDB还插入了 40 亿行数据(1 TB)、500 万行数据(125 GB)。整体上看,单大表的性能和单小表的性能在高并发场景下基本趋近,此外,真实生产环境中不会像压测场景下出现如此密集的写入导致脏页维持在非常高的水位,完全可以承载一般业务流量。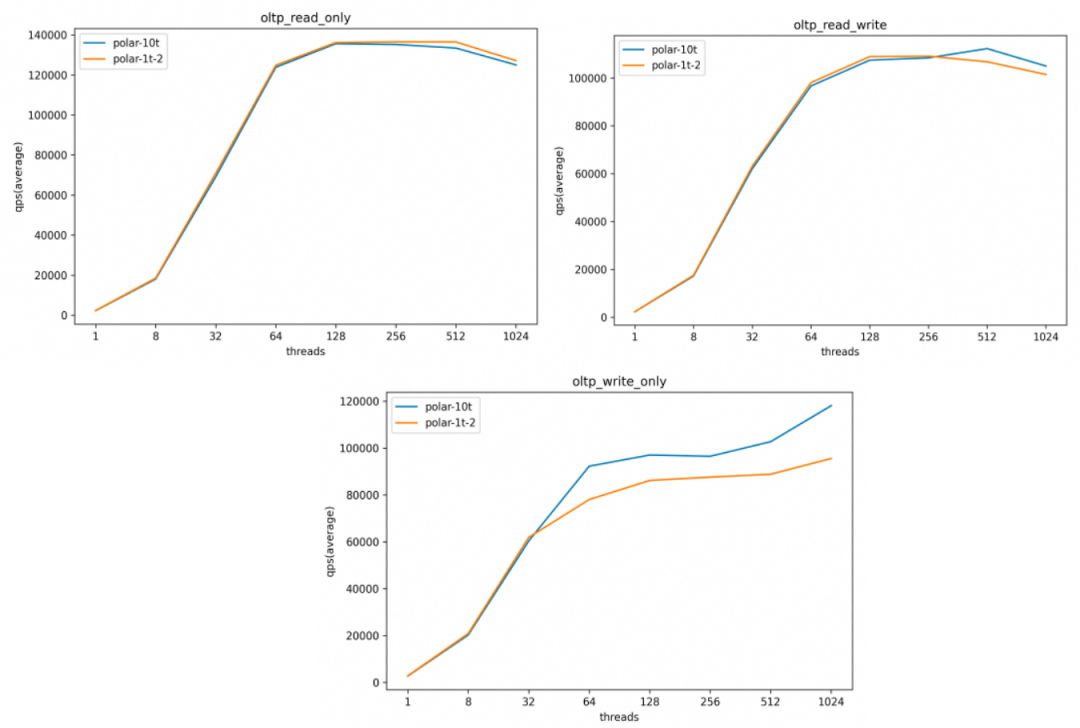
40 亿行和 500 万行性能对比
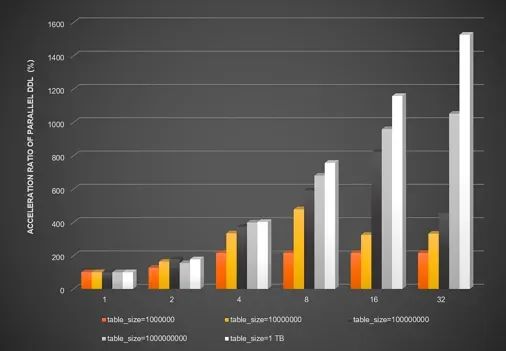
传统的DDL操作基于单核和传统硬盘设计,导致针对大表的DDL操作耗时较久,延迟过高。以创建二级索引为例,过高延迟的 DDL 操作会阻塞后续依赖新索引的DML查询操作。多核处理器的发展为并行DDL使用更多线程数提供了硬件支持,而固态硬盘(Solid State Disk,简称SSD)的普及使得随机访问延迟与顺序访问延迟相近,使用并行DDL加速大表的索引创建显得尤为重要。PolarDB的并行DDL功能,能够充分发挥数据库硬件资源,大幅降低DDL的执行耗时,避免阻塞后续相关的DML操作,缩短执行DDL操作的窗口期。并行DDL上线以来,已经实际帮助大量客户解决了大表添加索引的痛点问题。根据真实用户反馈,启用并行DDL功能后,对于一张5 TB、60亿行的大表,仅需1小时即可完成二级索引的添加。下图展示了当使用不同的并行线程数时, 在不同数据量的表中开启并行DDL后,在数据类型为INT的字段b上创建二级索引带来的DDL执行效率的提升比例。可以看到,当开启32线程时,最高可获得2000%的性能提升。不同的并行线程数对DDL的性能提升对比图
使用传统方法执行加列操作时,需要重建整个表数据,占用大量系统资源。PolarDB MySQL引擎支持秒级加字段(Instant add column)功能,在加列操作时只需变更表定义信息,无需修改已有数据,帮助您快速完成对任意大小表的加列操作。对表进行加列操作时,可以无视表的大小,在秒级完成加列操作。
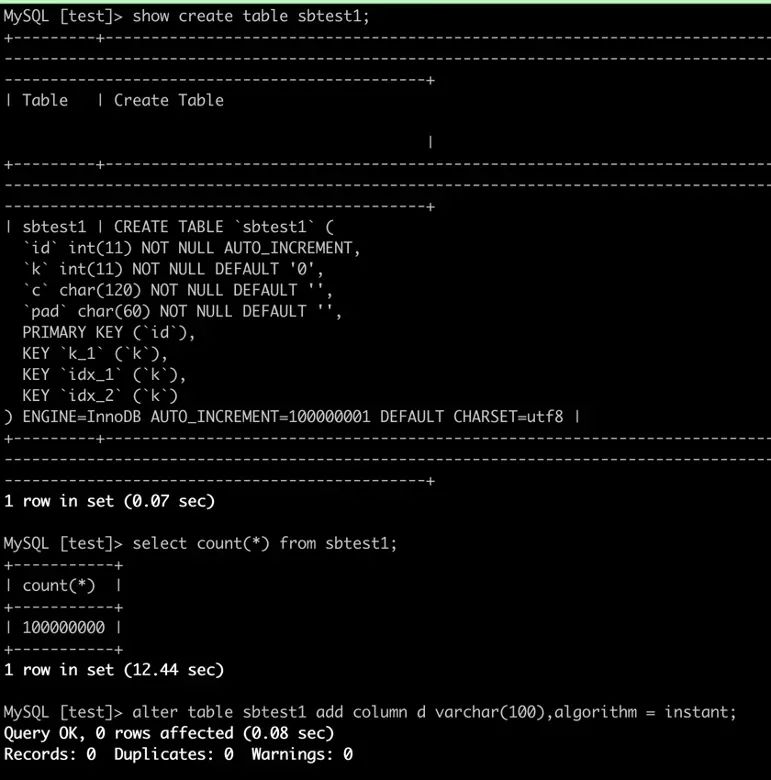
UTF-8编码集是一种常用的编码集。在社区MySQL中,当用户指定使用UTF-8时,会默认使用utf8mb3编码集。该编码集最大使用3个字节存储字符。如用户需要存储emoji等信息时,可能需要转换为utf8mb4字符集。通常字符集的转换需要进行表重建,耗时较长,对业务影响较大。PolarDB MySQL已支持 utf8mb3 到 utf8mb4 字符集之间的秒级修改。借助该功能,您可以方便的将 utf8mb3 字符集修改为 utf8mb4 字符集。ALTER TABLE tablename MODIFY COLUMN test_column varchar(60) CHARACTER SET utf8mb4, ALGORITHM = INPLACE;
使用上述语句时,若返回ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.错误,表示当前操作不能以inplace算法执行,建议您仔细核对使用限制。
不指定ALGORITHM或指定ALGORITHM=DEFAULT;此时,PolarDB会自行选择执行速度最快的算法来执行修改操作,语句示例如下:
ALTER TABLE tablename MODIFY COLUMN test_column varchar(60) CHARACTER SET utf8mb4, ALGORITHM = DEFAULT;
ALTER TABLE tablename MODIFY COLUMN test_column varchar(60) CHARACTER SET utf8mb4;
使用效果:将列的字符集从utf8mb3转为utf8mb4时,可以无视表的大小,在秒级完成操作。
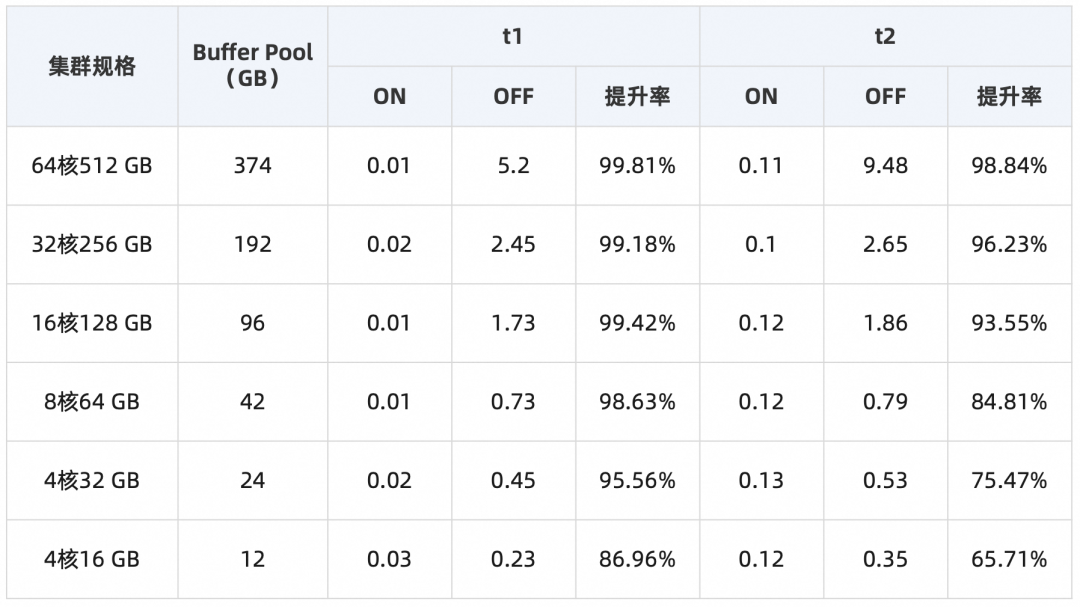
▶︎ 2.3.4 SAAS刚需:快速Truncate/Drop大表在社区MySQL 5.7中,当执行TRUNCATE TABLE和DROP TABLE时,需要扫描整个缓存池(Buffer Pool),将表空间对应的所有数据页从LRU list和FLUSH list中删除。当Buffer Pool比较大时,该操作耗时较长。PolarDB对DDL过程中的Buffer Pool管理机制进行了优化,能够有效提升Buffer Pool的扫描效率,提升TRUNCATE TABLE和DROP TABLE的执行效率。参数 loose_innodb_flush_pages_using_space_id 设置为 ON 即可启用此功能使用效果
使用效果:
在不同规格的集群中,分别记录开启和关闭Faster TRUNCATE/DROP TABLE功能后,对t1和t2进行TRUNCATE TABLE操作所需的执行时间(秒)。其中,t1表插入8196行数据,用于模拟小表TRUNACTE情况,t2表插入2097152行,用于模拟大表TRUNCATE情况。实验结果如下所示:从上表可以看出,开启Faster TRUNCATE/DROP TABLE功能后,能显著提升TRUNCATE TABLE操作的执行效率。用户在执行DDL操作的时候,若目标表存在未提交的长事务或大查询,DDL将持续等待获取MDL-X锁。在PolarDB中由于MDL-X锁具有最高优先级,DDL在等待MDL-X锁的过程中,将阻塞目标表上所有的新事务,这将导致业务连接的堆积和阻塞,可能会造成整个业务系统崩溃的严重后果。为了解决这个问题,PolarDB针对Online DDL提供了非阻塞DDL功能。开启该功能后,DDL语句在拿锁策略上将与工具(gh-ost / DMS无锁变更)保持一致,以此达到对业务无锁/无损的表现。此外,因为PolarDB的DDL流程是内核原生的流程,所以性能也会大幅优于外围工具。开启本功能,可以使DDL操作在保持内核的高性能的同时,具备类似于使用外围工具的无损特性,能够大大减少DDL操作对业务的影响。使用loose_polar_nonblock_ddl_mode参数开启Nonblock DDL功能。开启后,用户在业务高峰期执行DDL,即使DDL拿不到锁,也不会影响用户业务。
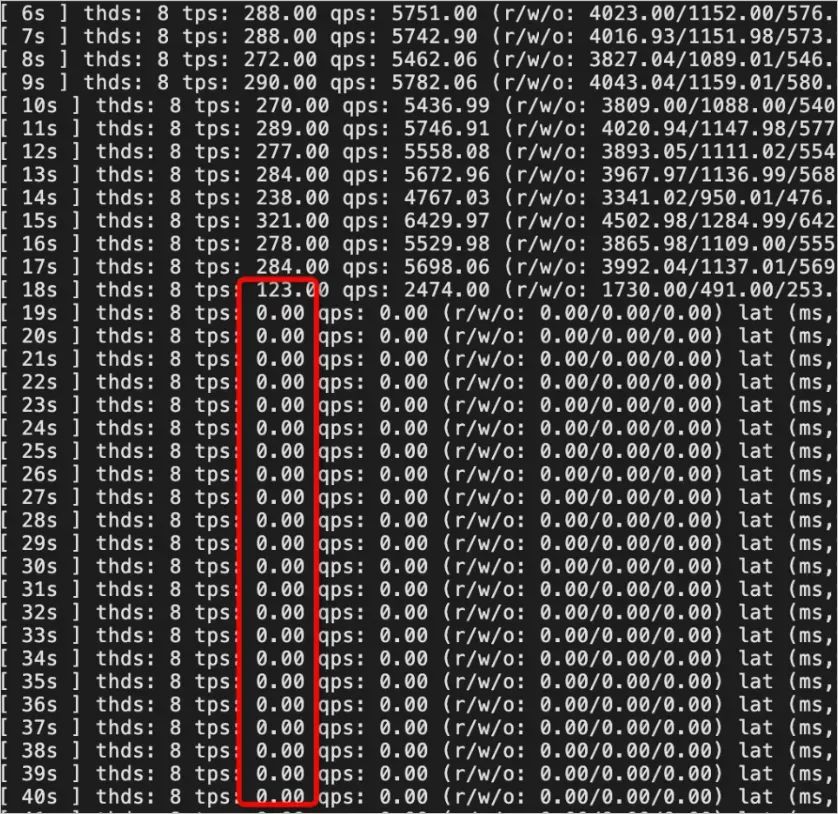
1. 关闭Nonblock DDL,TPS持续跌零。默认超时时间为31536000,严重影响用户业务。2. 开启Nonblock DDL,TPS周期性下降,但未跌零。对用户业务影响较小,能保证业务系统的稳定。
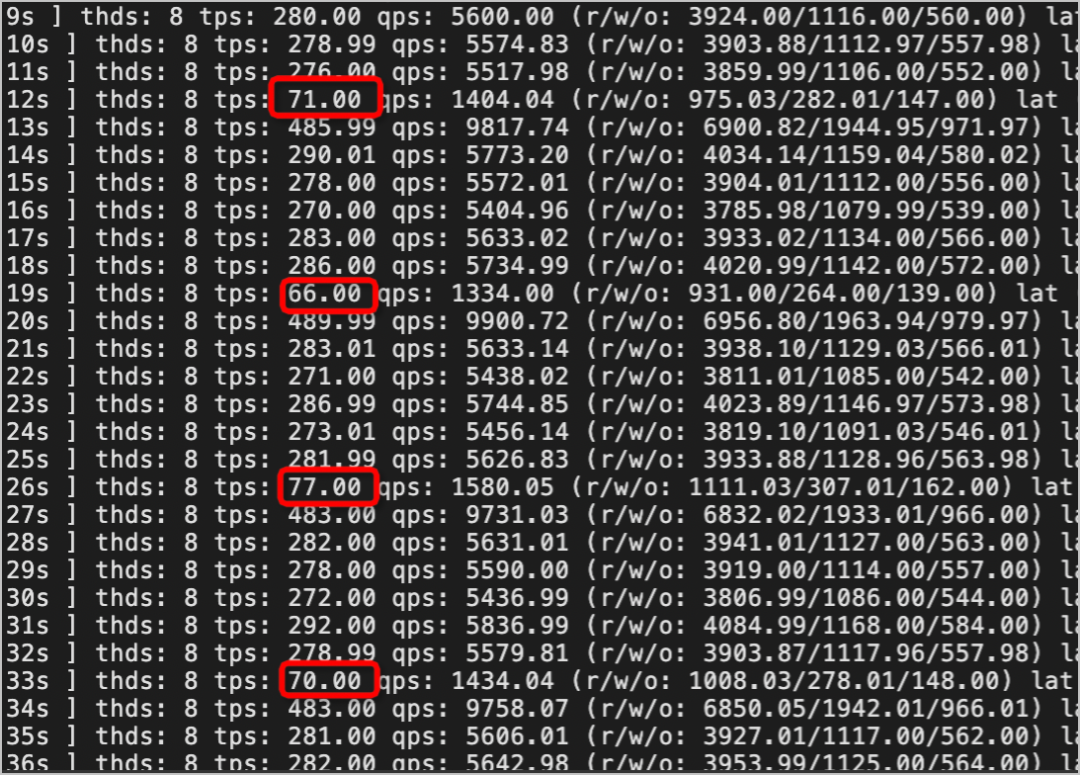
3. 使用gh-ost进行表结构无锁变更,TPS周期性跌零。对用户业务影响很大,这是cut-over阶段短暂锁表造成的。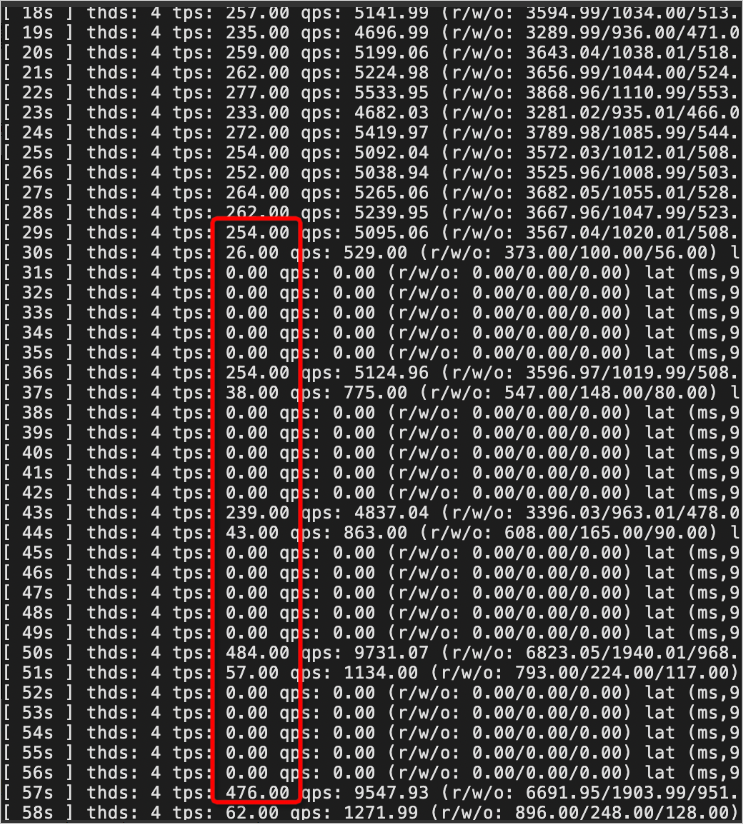
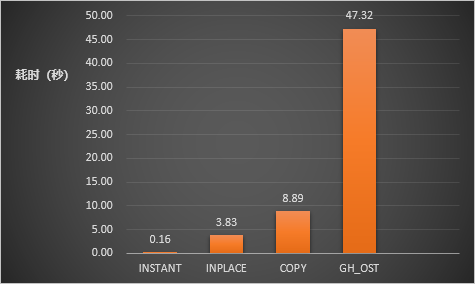
4. 性能对比:使用SysBench的oltp_read_write模拟业务负载,通过下图可以看出开启Nonblock DDL并使用传统的加列方式(INSTANT、INPLACE、COPY)比使用gh-ost工具耗时更少。
启用Nonblock DDL功能后
内核原生DDL耗时与GH-OST性能对比
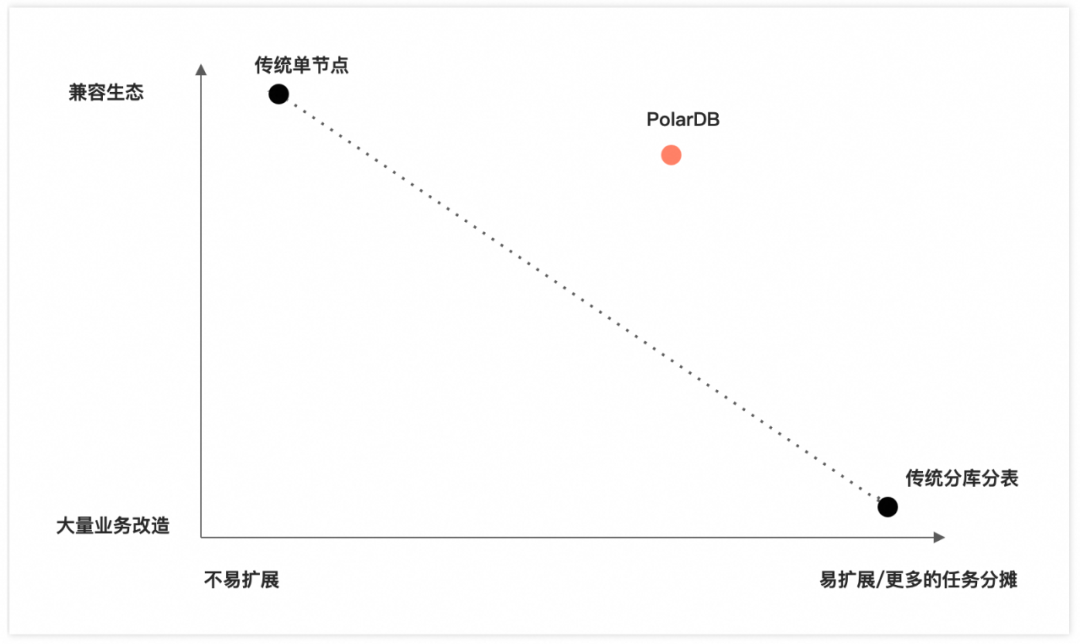
从当前云产品的发展趋势来看,几乎所有主要云产品提供商都推出了兼容性最强的解决方案,并将其作为云平台的核心产品。
对于云服务提供商而言,兼容性是最重要的需求之一。对于许多中小型客户而言,100%的兼容性是一个重要的参考指标。客户将产品迁移至云端时,往往会考虑现有开发人员的技术栈和存量代码。因此,任何不兼容的情况出现都会导致开发人员需要付出额外的学习成本,同时也会增加对现有业务进行改造的成本,从而给客户带来额外的支出。当然,随着业务的壮大,可能会出现大表影响业务发展的情况,性能不再满足需求且没有数据清理方案,那时再考虑相关问题也为时不晚。
/ END /