




作者:文一,应急管理大学在读本科生,中国 PostgreSQL 分会实训基地秘书长,《数据库红皮书》(线上读物)译者,曾经在中国科学院,北京航空航天大学等分享过 PostgreSQL 内核学习有关的经验与材料。MOP 社区会员,IvorySQL 社区成员。
所有成熟的思考,都来自于细微的探索,我们将继续展开一系列分析,帮助更多的人走进数据库内核的世界,建设一个繁荣的,重视技术与原理的中国数据库生态。
pg_resetwal 负责清理 PostgreSQL wal 日志文件,同时可以在需要的时候重建 pg_control 文件,而要想理解它所工作的原理,我们就必须对下面的知识,建立基本的了解:
简单理解 PostgreSQL wal 日志机制起到的作用
理解日志机制的作用,除了为数据库的管理人员提供重要的参考信息以外,最重要的集中于下面的两点:
故障恢复
在数据库出现故障的时候,将保存有数据读写操作的日志,结合已经存储于磁盘上面的数据,即可以实现快速故障恢复。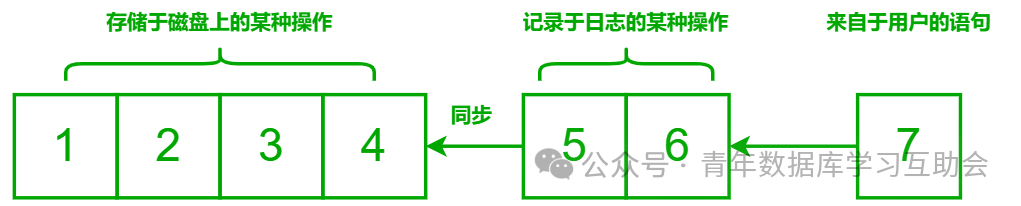
(一种对于日志机制流程的简化描述,用户的指令在交付执行时,会自动构造出对应的日志来,放置于缓冲区之中,并最终写入磁盘,因此,故障恢复时,只需要把那些尚未写入磁盘的内容,写入进去,即可以快速地恢复服务)集群部署
通过把记载有数据读写操作的日志传输给其它的节点,就可以实现集群部署,进而集合 Raft 等算法,实现高可用,分散读写压力等。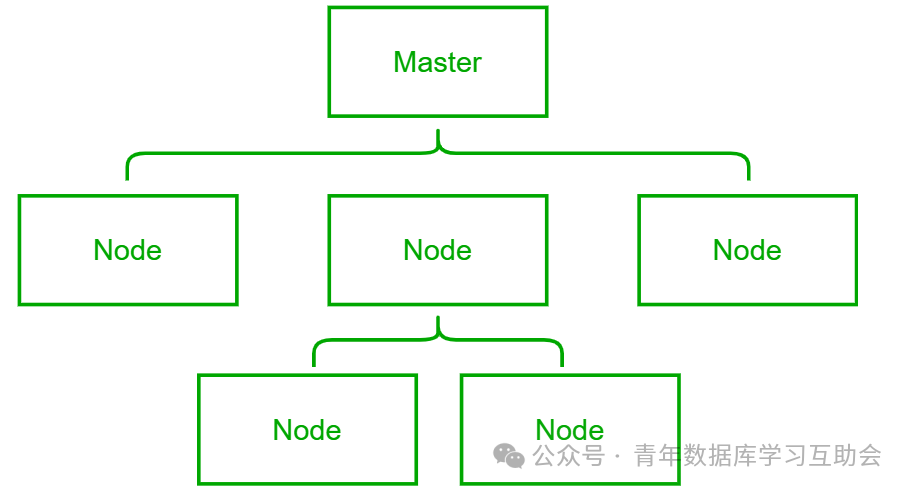
而日志的本质,就是按照某种方式组织起来的数据文件,尽管其组织的要素往往仅有四个(在我阅读完成一定的数据库代码后,得出来的一个总结):操作所对应的时间
操作所对应的指令
操作所对应的数据
操作完成的状态
但是因为实际工程实践中,因为各种数据库的设计思路,应用场景不甚相同,因此最终呈现出来的表现形式,在库内所承担的责任,乃至于对外所用术语等,往往会不一样,如在 MySQL 中,记录着数据操作的日志,被称为 “binlog”,在 PikiwiDB 中,则有“slowlog” 等。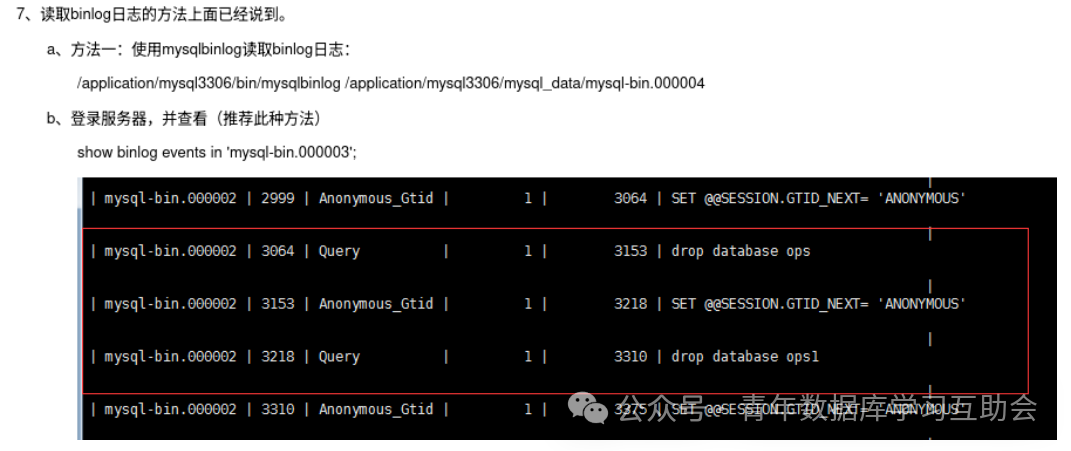
(图片截取于某篇介绍 MySQL binlog 的文章)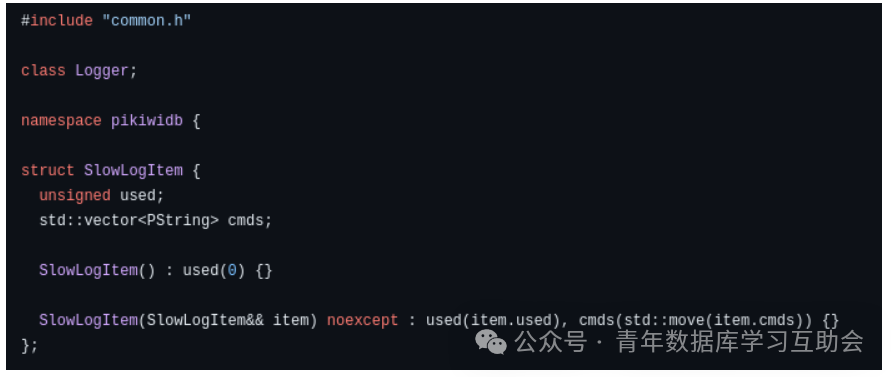
(图片截取于 PikiwiDB 的一部分源代码,可以看出,因为 PikiwiDB 是一款 Key-Value 数据库,所以其日志结构的设计,就简单一些)
在有了一个大体的了解之后,我们可以再对 PostgreSQL 中的 wal 归档,做一个了解,他们同样是我们理解 pg_resetwal 的重要支撑:
wal 归档
领域交叉融合的一个重要表现形式,就是我们可以用发生于另外一个领域的专业术语,解读发生于我们这个领域的某一项工作,在这里,我们摘取华为云在对象存储(OBS)中,对于归档存储的解析:
归档存储(OBS Archive)是OBS存储类别的一种,适用于很少访问(平均一年访问一次)数据的业务场景
而在 PostgreSQL 之中,wal 的归档,即代表日志文件中所记录的数据管理操作,以及所对应的数据,已经正式落地磁盘,因此即使对应的 wal 日志遭到了破坏,乃至于删除,也不再会影响到存储于磁盘上的数据。
对检查点(Checkpoint)做一个了解,则可以帮助我们更好地奠定理解 pg_resetwal 的基础:
检查点(Checkpoint)
在工程的实践当中,一种行之有效的办法,就是把工程当中的工作,分解为一个又一个的时间节点加以推进,如在 PostgreSQL 中,在内核补丁审核程序 Commitfest(可以把它理解为 Github 中的 Pr)中,即会规划一个审核的周期,进而同数个大版本的内核测试与发布,结合到一起来统筹推进;而在 PikiwiDB 中,社区的组织方式便是在每一周召开一次关于内核研发的周会,并将任务发布于社区的 weekly 周报之中,挂图作战进行推进。
(PostgreSQL CommitFest 程序截图)
(PikiwiDB 的 weekly 截图)
而在 PostgreSQL 中,检查点(Checkpoint)的内涵,引述文档中的内容,则如下所阐述(注意在 PostgreSQL 之中,即使是单独的查询语句,也是视作为一个事务而处理的):
检查点是一组分布于事务序列当中的点,在(每一个特点的)检查点之前,PostgreSQL 保证堆表数据与索引数据文件,及其所有的信息,已经被写入磁盘。
Checkpoints are points in the sequence of transactions at which it is guaranteed that the heap and index data files have been updated with all information written before that checkpoint.
而在 PostgreSQL 中,描述检查点的代码,罗列如下所示:
typedef struct CheckPoint
{
/* 下一个我们可以用来创建检查点的 wal 日志区域, redo start */
XLogRecPtr redo;
/* 当前的时间线 ID */
TimeLineID ThisTimeLineID;
/* 先前的时间线 ID
如果当前的记录开启了新的时间线,则记录之;
否则同当前时间线 ID 保持一致
*/
TimeLineID PrevTimeLineID;
/* 是否开启全页写入?*/
bool fullPageWrites;
/* 当前日志的级别?*/
int wal_level;
/* 下一个可用的事务 ID (Full 版本的 id 还会记录发生了多少次的事务号迭代) */
FullTransactionId nextXid;
/* 下一个可用的 OID */
Oid nextOid;
/* 下一个可用的事务 ID */
MultiXactId nextMulti;
/* 用于标识多个事务 ID,这点我们会在后续的文章中做详细论述 */
MultiXactOffset nextMultiOffset;
/* 数据库集簇级别的最老版本的尚未被清理过的事务 ID (需要联系冻结机制) */
TransactionId oldestXid;
/* 最老版本的尚未清理过的事务 ID 所在的数据库的 OID */
Oid oldestXidDB;
/* 集簇级别的尚未清理过的事务 ID,不过这个 ID 不带有“第几轮迭代的信息” */
MultiXactId oldestMulti;
/* 最老版本的事务 ID 所处的数据库 OID,事务 ID 同样是不带 “第几轮迭代” 的 */
Oid oldestMultiDB;
/* 检查点所对应的时间 */
pg_time_t time;
/* */
TransactionId oldestCommitTsXid; /* oldest Xid with valid commit
* timestamp */
TransactionId newestCommitTsXid; /* newest Xid with valid commit
* timestamp */
/*
* Oldest XID still running. This is only needed to initialize hot standby
* mode from an online checkpoint, so we only bother calculating this for
* online checkpoints and only when wal_level is replica. Otherwise it's
* set to InvalidTransactionId.
*/
TransactionId oldestActiveXid;
} CheckPoint;
