




大模型概念
参数量大。在参数规模上可能达到十亿、百亿、千亿级别,远超传统模型百级、千万级别参数规模。 训练数据量大。传统人工智能模型通过一定量的标注数据进行训练,而大模型通过海量数据及设计良好、内容多样的高质量标注语料库进行训练。 计算能力要求高。大模型很难在单个 GPU 上进行训练,需要使用 DeepSpeed、Megatron-LM 等训练优化技术在集群中进行分布式训练。
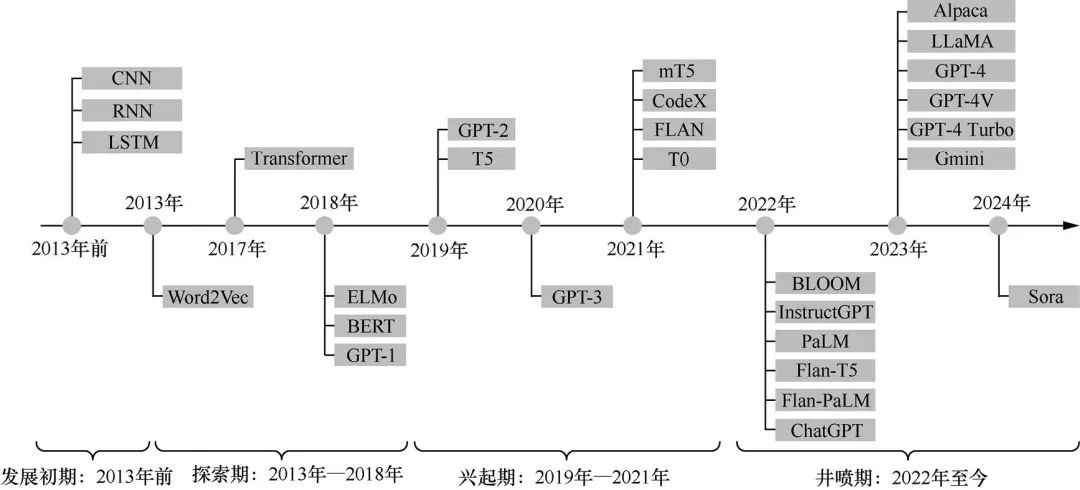
大模型发展历程
发展初期:2013年之前,主要依赖 RNN(循环神经网络) 和 LSTM(长短期记忆网络) 等序列模型解决具有序列特性数据的领域问题,其主要缺点是不可并行计算。 探索期:2013年 Google 公司提出的 Word2Vec 是一种高效训练词向量的模型并一直流行到 2018年。2017年 Google 公司提出的 Transformer 架构引入自注意力机制和位置编码,改进了 RNN 和 LSTM 无法并行的缺陷,2018年 Google 又推出 BERT(预训练语言表征模型) 等模型,彻底超越 Word2Vec。 兴起期:OpenAI 公司于2019年推出具有 15亿 个参数的 GPT-2,于2020年推出具有 1750亿 个参数的 GP-3。 井喷期:2022年至今,越来越多的开源模型如 LLaMA、ChatGLM 相继发布。GPT-4、GTP-4V、文心大模型4.0 等将大模型的发展方向由语言模型引向通用性更强的多模态模型。2024年 OpenAI 公司发布文生视频大模型 Sora,能够准确理解用户指令中表达的需求并以视频形式进行展示。
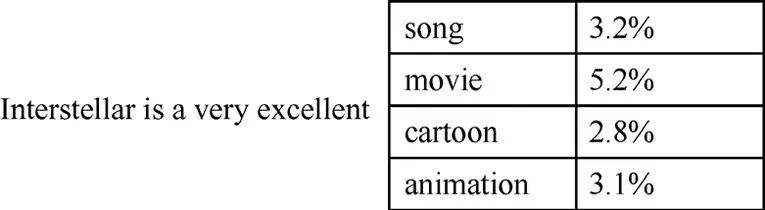
大模型生成原理
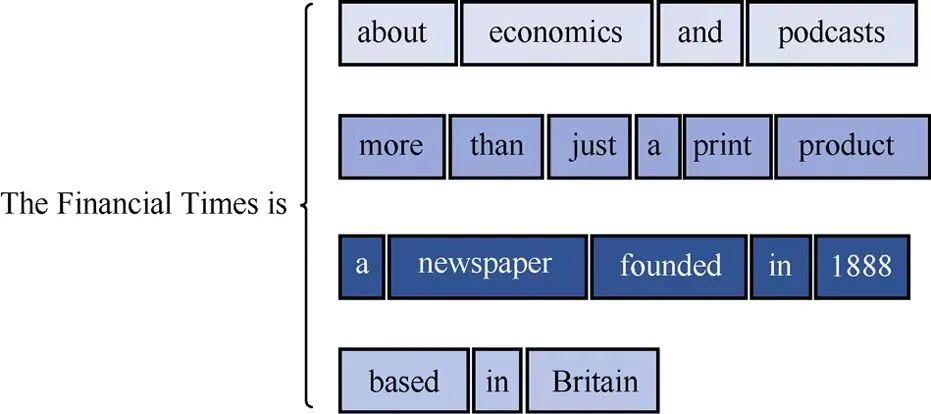
大模型关键技术
迁移学习
零样本学习
小样本学习
持续学习
多任务学习
RLHF(强化学习)
上下文学习
思维链
提示工程
RAG概念
RAG作用
在没有答案的情况下提供虚假信息。 当用户需要特定的当前响应时,提供过时或通用的信息。 从非权威来源创建响应。 由于术语混淆,不同的培训来源使用相同的术语来谈论不同的事情,因此会产生不准确的响应。
经济高效的实施。
当前信息。
增强用户信任度。
更多开发人员控制权。
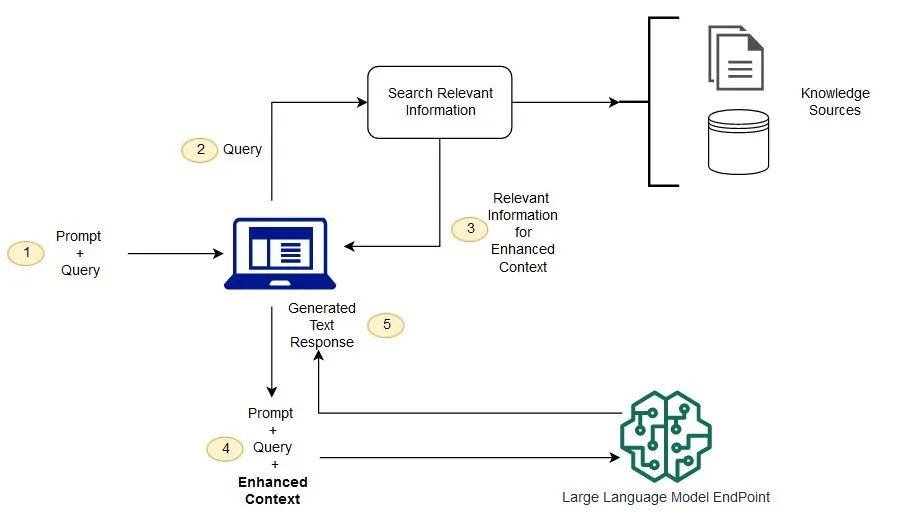
RAG工作原理
创建外部数据
检索相关信息
增强 LLM 提示
更新外部数据
参考
文章转载自数据源的技术后花园,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
