




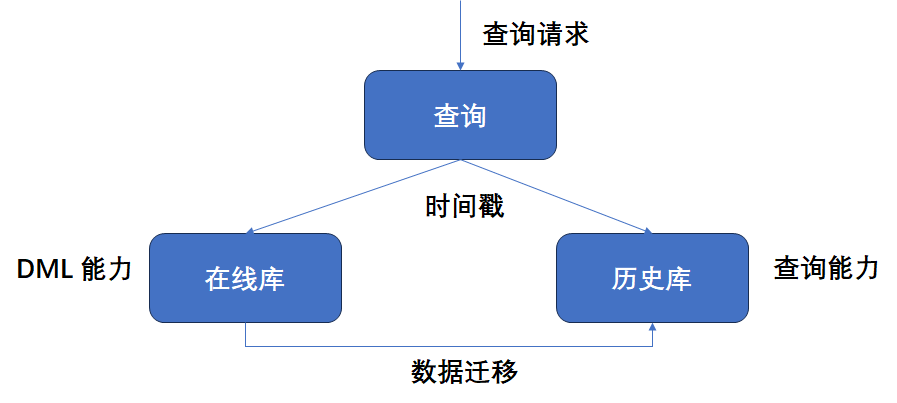
在金融行业 IT 架构中,我们经常听到数据库的三种应用场景:在线库、历史库和大数据仓库。它们通常针对数据生命周期的不同阶段,如在线阶段、近线阶段、归档阶段。这三者的概念及它们之间的关系如下:
在线库。在线库是为用户服务的,不仅包含用户可直接访问的部分,还包含相应的后台任务,如流动性管理、存款季度结算、计算和提取、记账日切换等场景。
历史库。历史库是在线服务的数据库,相对在线库来说,历史库能提供廉价的磁盘存储服务,在降低存储成本的同时,还能提供少量的在线查询服务。从历史的视角看,历史库是抵达终态的数据的 “终点”,而在线库是数据加工、计算的临时场所。
数据仓库。数据仓库提供了计算离线大数据的功能,典型特点是计算量大,而且有一定时效性。比如需要计算小时级交易量的环比和同比。小时级数据都在在线库存储,历史库没有这份数据。计算时需访问的数据量比较大,而且算同比时会用到去年此时的数据。考虑在线库的用户访问隔离策略,需要将在线数据同步到另外一种存储位置进行计算。在计算方式上,Google 在三篇论文中提及的 MapReduce 算法对应到开源社区中成了 Hadoop、HDFS 等。
在线库、历史库和数据仓库根据自身的业务特点在数据库的选型上当然是有所不同的。在线库的主要特点是面向用户的高并发交易及一定的批量处理业务,对数据库的选择上侧重高性能、高可用、一致性,以 Oracle、Informix 等集中式数据库为主或者是擅长 OLTP 为主的分布式数据库如TiDB、OceanBase、GoldenDB、TDSQL、GaussDB等。数据仓库的主要特点是计算离线大数据的能力,通常选择模式不固定、健壮性较高的 Hadoop 系列或者是擅长 OLAP 为主的 MPP 架构如 GBase 8a、StarRocks、Doris 系列等。历史库则是介于在线库和数据仓库之间,它既要有在线库的在线服务能力,又要有数据仓库的大数据存储查询能力。具体来说,历史库的选型通常要考虑包含但不限于以下因素。
可扩展性。在可扩展性方面,分布式数据库比单机库更有优势。以 MySQL、PostgreSQL 为例的集中式数据库数据存储限制在单台物理机上,如果使用这类数据库作为历史库,则需要上层分库分表的包装,增加了多种管理成本,如历史库分表管理成本、在线库到历史库的迁移成本、历史库分库后应用启动连接数增加导致整体启动变慢。支撑历史库比较理想的是原生分布式数据库,原生分布式数据库在数据库内部完成分布式任务,包括分布式计算、分布式存储、分布式事务等,这可以很好的规避分表管理成本和到历史库的迁移成本。
无锁 DDL。首先应该淘汰掉 DDL 变更锁表的数据库,历史库是需要提供长期在线服务能力的,DDL 变更是线上运行过程中不可避免一个动作,如果 DDL 变更过程中会锁住表的读写,导致业务和变更 “二选一”,不仅影响业务可用性,也增加了运维复杂度。
压缩。历史库的主要功能是存储数据,压缩是降低存储成本的有效手段。从业务发展趋势来看,行业中提到的 “银行业 4.0”,一方面要深化存、贷、汇等传统业务,另一方面要不断拓展创新业务。无论是传统金融服务场景化延伸到全供应链,还是银行作为服务的推荐中介收取服务费用,都将产生海量数据,而压缩可以大幅降低存储成本。
二级索引。历史库的特点之一是可以查询,二级索引为业务查询提供了灵活性,历史库的索引可以与在线库完全不同,这取决于业务逻辑。比如,在线库有 10 个索引,历史库可以仅有 1 个,索引的减少节约了存储空间。
后台检验。及时发现磁盘的损坏是历史库必须具备的功能,这是 OLTP 数据库较少支持的功能。OLTP 数据库中的数据经常被读取,在读取时会将块中数据重新计算校验和并与块中记录的校验和做一个比较,历史库中大部分数据是 “冷数据”。作为数据长期存储设备,磁盘坏块、消磁若没有及时发现,则会存在数据丢失的风险。
加密。从行业趋势看,隐私保护、数据安全已经提到新的高度,透明加密已成为基础 “标配”。
