





时至今日,HTAP 混合负载已经逐渐被市场接受和认可,回想早些年与用户交流 HTAP 时,大家都还比较陌生,从市场的接受程度来说,也不尽如人意。前段时间偶然刷到圈中好友分享的《OceanBase 列存的现在与未来》,其中列举了多种列存架构,对 OceanBase “列存是所有”设计理念进行了充分介绍,也对 TiDB 这种“列存是副本”的方案进行了分析,引发了我的一些思考。
有一次我们 CTO 问大家,TiDB 的 HTAP 一定是包含列存吗?对于这个问题,客户是我们最好的老师,我接触过客户有只使用 TiKV 来支撑 HTAP 场景的,也有的客户 HTAP 场景中 TiKV 和 TiFlash 均有使用;也从客户这边学习到业务报表和全局报表这两种不同的负载场景,同时业务报表对查询一致性的要求也非常高。慢慢地,我发现 HTAP 架构不仅需要能够做到支撑两种不同的负载,同时灵活性、隔离性和低使用成本也是对业务和客户来说非常关键的能力。
本文仅代表个人拙见,欢迎指正、探讨。
业务上是否需要 HTAP 架构?
某些业务系统中,混合负载场景是客观存在的,并且之前已有多种方案来解决这样的场景:云上有典型的异构方案来解决、而在云下也有多种技术栈组合的异构方案,均可以在接近实时的基础上,解决两种不同负载、并实现物理隔离。
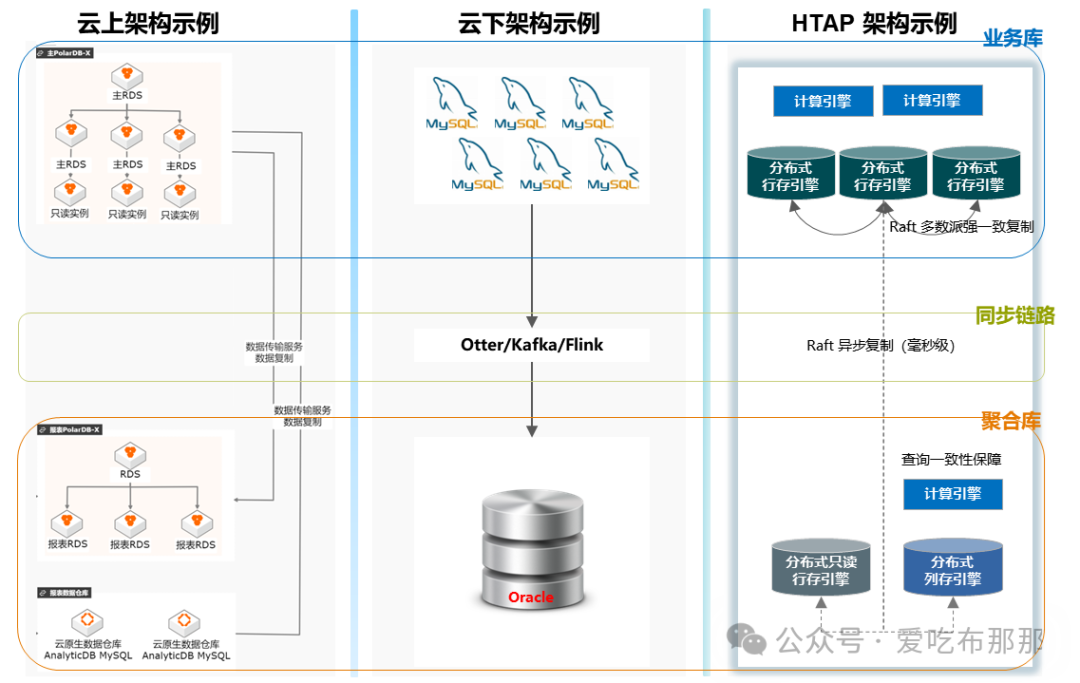
“HTAP 数据库”对比“异构 HTAP 解决方案”,需要继承哪些优点、解决哪些问题呢?
HTAP 数据库关键能力-灵活性
事实上,HTAP 是在 OLTP 的基础上增强一部分轻量级"OLAP"能力,而非"HATP":即在 OLAP 的基础上增强 OLTP 的能力。在一个 OLTP 业务系统中,绝大部分情况下依旧是使用行存+索引更加合适,业务建设初期可能无法准确预知哪些表会有"OLAP"类的使用场景,当某一天出现一个业务需求需要列存来支撑时,能将行存表快速转化为行列混合存储表将对业务来说非常有帮助。
“异构 HTAP 解决方案”在解决此类场景时是复杂的、不灵活的,而 HTAP 数据库解决起来比较简单且灵活:

从灵活性来说,TiDB 这种列存是副本的方案非常灵活,能够库、表级进行变更,变更过程中对行存也完全不影响;OceanBase 操作比较简单,无需考虑增加列存节点,仅需一个 DDL 操作便可完成表级变更,但该过程是一个离线 DDL,会锁表,需要注意。
HTAP 数据库关键能力-隔离性
当架构能够支撑两种负载同时运行时,如何确保在列存上运行"OLAP"负载时不影响 OLTP 负载,这显然是一个很必要的考虑,否则将"OLAP"负载直接使用异构的 OLAP 数据库将会是一个更令人安心的选择。
对于 OceanBase 来说,由于行存和列存共用一个 Observer,也共用一份数据的 Leader,所以 OceanBase 的设计理念为:"OLAP 负载可以灵活地从 OLTP 负载处获取资源,并在 OLTP 空载的情况下使用大部分系统资源",也就是缺省资源共享不进行隔离。同时,如果业务需要实现隔离负载或资源,也提供一些解决方案。
而 TiDB 使用的是列存是副本的方案,天然便实现了存储层面的物理隔离,同时 TiDB 计算层会将绝大部分的 SQL 使用 MPP 计划下推至 TiFlash 列存节点上执行,所以即使计算层未隔离,其负载也很低。
“异构 HTAP 解决方案”本身在隔离性上已经足够优秀,我认为 HTAP 数据库需要继承这一能力:

从隔离性来说,TiDB 这种列存是副本的方案隔离性非常高,并且要实现计算和存储的完全物理隔离也非常简单,另外即使在列存是副本+高隔离的基础上,TiDB 依旧默认提供查询一致性的保障。
OceanBase 则是提供了多种解决方案,可供用户自己选择。其中隔离性最好的应该是在只读副本上进行弱一致读取,即达到列存是副本的效果,操作上相对会复杂一些。
HTAP 数据库关键能力-低成本
业务上使用 HTAP 架构,成本也是一个很难忽视的因素。到现在,大家都在强调 HTAP 的价值之一,便是能够大幅简化“异构 HTAP 方案”架构、节省 ETL/DTS/Canal 等管道同步维护、DDL 维护、OLAP 数据库建设等成本。
我在看到 OceanBase 4.3 的架构中行与列在一个引擎中实现时,觉得这个思路非常有趣,共用一份增量数据,基线数据层可灵活创建纯行存、纯列存、行列混合存储(甚至索引结构也可以),这样的设计实在是太有趣了!能够有效降低客户的使用成本,也反映了 OceanBase 强大的研发能力。
而 TiDB 这种列存是副本的解决方案,列存是一份独立的数据,存储在一台独立的机器上,在最小解决成本上显然是高于 OceanBase 数据库。但是,在大多数场景下,这个最小解决成本仍旧是比较低的。

从行列混合存储表这种使用场景来说,我认为两者解决成本都比较低:
对于 TiDB 这种列存是副本的方案,在保障了关键的隔离性基础上,使用成本并不高;还能实现行与列之间资源的灵活配比(各自可按需扩容),灵活度也是极高
对于 OceanBase 这种行存与列存一体化的方案,在不考虑隔离或者隔离需求不高时,成本会相对低一些,虽然行列混合存储表会冗余双倍的基线数据,但我印象中 OceanBase 数据压缩是非常优秀的。在引入只读 Zone 实现隔离后,机器成本也会相应增加。但租户内扩容时,OLTP 所在 Zone 与 OLAP 所在只读 Zone 无法各自单独增加节点,只能 4 个 Zone 同时增加,存在一些扩容上的不便
写在最后
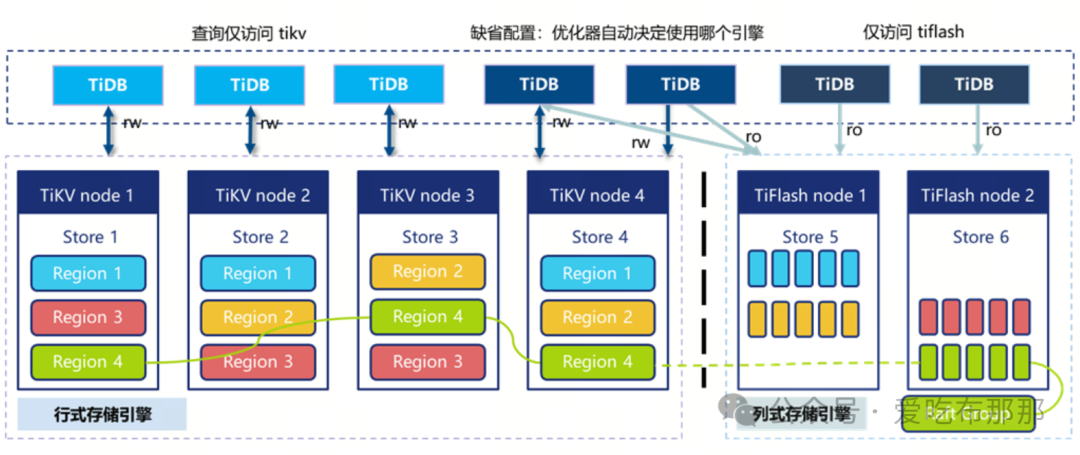
TiDB - 列存是副本架构
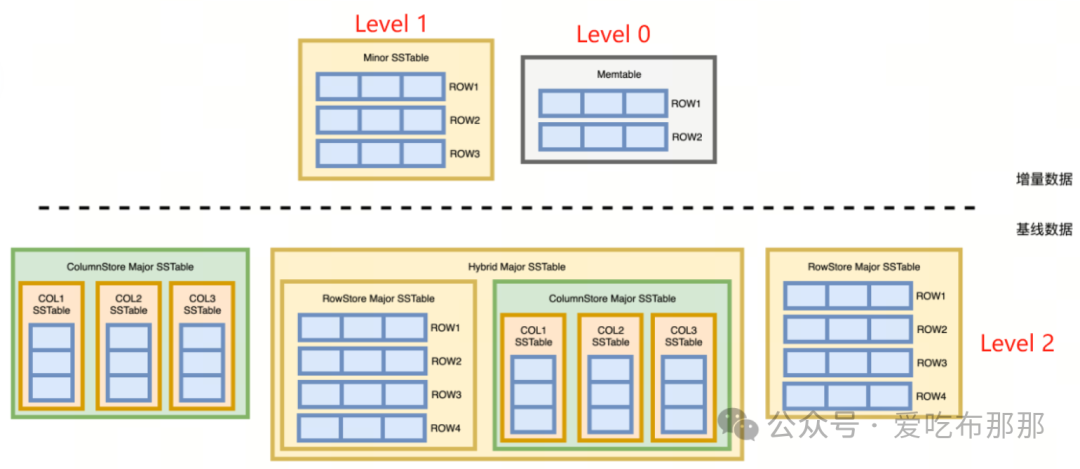
OceanBase - 列存是所有架构(单节点示例)
目前来看,各家 HTAP 数据库已经逐渐趋于成熟,各家 HTAP 架构侧重点也各不相同:
像 TiDB 这种列存是副本的方案,在灵活性、隔离性、使用成本上,都做得比较好,同时从整体的成熟度来说也比较高,已经经过客户众多场景的打磨和验证,其中不乏有 500TB+ 规模的 HTAP 场景
而 OceanBase 列存是所有的方案,则提供非常丰富的功能和使用场景,如纯列存表+行、列、行列混合索引、物化视图等,十分强大;另外在 4.2 没有列存引擎时 AP 性能就已非常强劲,4.3 加入列存引擎后,AP 性能更上一层楼
引入物化视图来增强复杂分析模型的能力,当前只能通过外部 ETL 工具来实现这一能力
数据亲和性绑定,降低列存计算过程中跨节点数据传输,提升超大数据规模分析场景的性能
优化器自动选择存储引擎:自 7.0 版本来,有极大提升,未来还可以更进一步、更智能
更多的用法支持:如纯列存表、列存索引,满足更多的使用场景
对于 OceanBase 来说:
表存储模型动态转换能力上,我认为实现 Online DDL 对用户很有帮助(普通表与分区表的转换最好也实现 Online DDL)
优化列存合并机制,列存数据当前与行存共用一个每日一次的合并机制,其实有一定的不足:当导入大批量数据到表或空表时,不进行合并的话,此时查询性能依旧是较低的,因为大量增量数据还在行存结构中;当表中更新量比较大时,一部分聚合查询性能也会逐渐下降,因为也产生了大量增量行存数据。4.0 版本以来,引入了租户级别合并、自适应合并等功能,已大幅降低了合并的影响。未来如果可以在 OCP 中提供分区/表级合并功能,或支持在只读 Zone 单独合并,将对用户更加友好
建议租户内的只读 Zone 中的 unit 数可以与全能型副本所在 Zone 的 unit 数不用完全对等,这将使得 OLTP 负载资源与 OLAP 负载资源各自扩容时更加灵活;另外当前只能为整个租户增加一个只读副本,如果可以只为个别库、表增加一个只读副本,灵活度将更高,成本上也会相对更低
欢迎探讨交流
