




数据库知识尤其是技术原理性的知识需要反复的去学习才能加深印象,所谓“温故而知新”大概说的就是这个意思。前段时间在阅读PostgreSQL内幕中关于Hash Join的说明时概念理解还比较清楚,现在已经变的很模糊,于是再回过头来整理一下。
首先,数据库中表关联主要有三种方式:nested loop join、hash join、merge join。Nested loop join在OLTP交易场景占比是最多的,常用于关联字段为主键或索引字段的情况,通过主键或索引以及loop的方式,A表可以快速查找到匹配的B表中数据。Merge join又称为Sort Merge,即如果被关联的两个数据集正好是有序的,这种方式则是最高效的。Hash Join则是把一个表(通常为小表)映射为哈希表放在内存中,进行匹配关联。此为简单理解,下面我们重点了解一下官方关于哈希连接的说明。
一.Hash Join的基本思想
Hash Join的基本思想为:根据小表(S表)建立一个可以存在于hash area内存中的hash table,然后用大表(B表)来探测前面的hash table。
如果hash area内存不够大,hash
table就无法完全存放在内存中。针对此情况,数据库的做法是在连接键上利用一个hash函数将S表和B表分割成多个不相连的分区,这个阶段叫做分区阶段;然后各自相应的分区再做哈希连接,这个阶段叫做连接阶段。
可以看出,Hash Join根据hash
table是否能在hash内存中放的下而分为两种情况,One-Pass
Hash Join(一次性完成的哈希连接)和Two-Pass Hash Join(两阶段完成的哈希连接)。
二.Hash Table是什么?
看起来Hash join的关键在于hash table,那么了解hash table是有必要的。先了解什么是哈希,哈希是接受可变长度的输入并产生固定长度的输出值的过程,称为哈希码或哈希。哈希(散列)函数负责将可变长度的输入转换为哈希。哈希在计算机科学中有多种应用,如存储和验证密码、创建消息签名以及提供数据管理结构等。
 |
那么hash table又是什么?hash table是将特定键与相应值关联起来的数据结构。这些表通常使用关联数组来实现以存储数据,此外它们使用哈希函数来计算应用将数据存储在数组的哪一个位置。因此,我们可以将哈希表理解为键值查找,即只要给定一个数据相关联的键,可以通过对hash table的快速查找来恢复相应的值。例如,我们可以用哈希表将姓名和个人信息关联起来,姓名通过哈希函数计算后得到的即为键,个人信息存储在哈希表中的值。
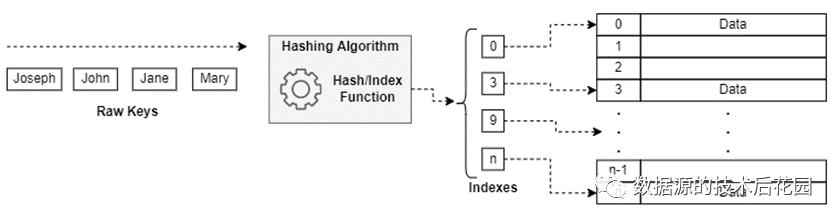 |
由于哈希函数将可变长度的键映射到固定长度的索引,因此它们实际上是把无限集映射到有限集,这种方式最终会导致哈希冲突(将多个值映射到相同的索引上)。关于哈希冲突的问题,也有相关的技术来解决,比如单独链表、线性探测等,本篇不作赘述。
三.关于One-Pass
Hash Join(一次性完成的哈希连接)
基于上述描述,One-Pass Hash Join就是将小表的数据使用哈希函数一次性映射到hash
table中(hash area足够存放hash table)。Hash table中存储的是哈希键和值对,可以通过键快速访问值。哈希键或多或少均匀地分布在有限数量的桶之间,桶的数量始终是2的幂次方。在PostgreSQL中,hash
area的大小受work_mem*hash_mem_multiplier值的限制。
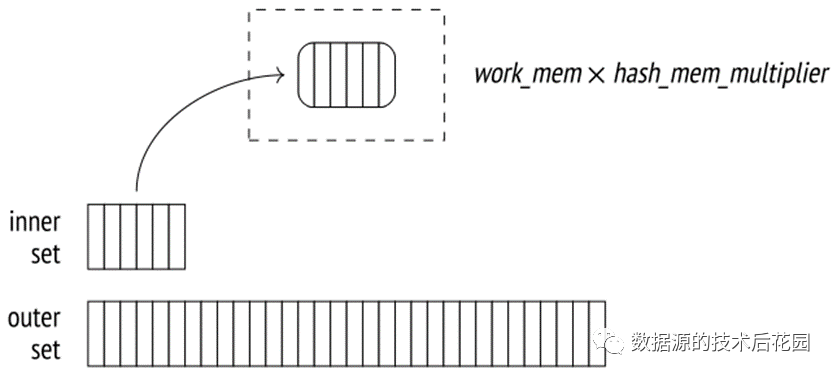 |
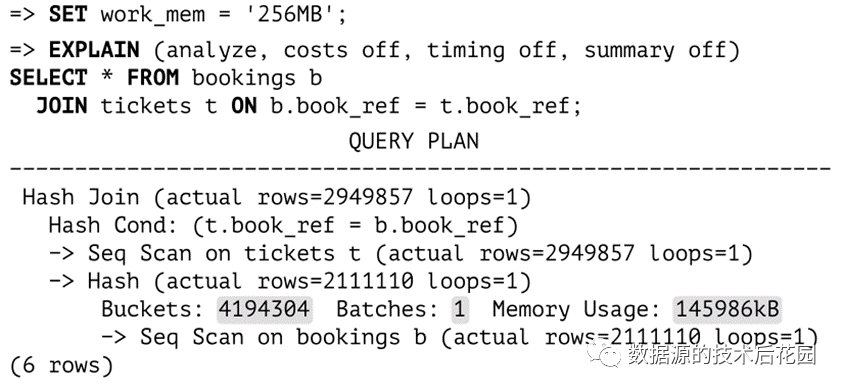
PostgreSQL中有关哈希连接的执行计划如下图所示,Hash Join节点是用ticket_flights表和hash table进行关联匹配的过程,Hash节点就是将tickets表映射到hash
table,Buckets代表分了多少个内存桶(这里是),Batches表示在一个批次中执行。关于桶的数量:所选择的桶数应该保证当哈希表完全填满数据时每个桶平均只保存一行,更高的密度会增加哈希冲突率使搜索效率降低,而不太紧凑的哈希表会占用太多内存。
 |
四.关于Two-Pass
Hash Join(两阶段完成的哈希连接)
如果优化器预估显示hash table将超过分配的内存,则将S表的行集分成若干批,分别进行处理,批的数量跟桶的数量类似也是2的幂次方。不同批处理中的行不能具有相同的哈希码。
在第一阶段中,执行器扫描内部行集并构建hash table。如果扫描的行属于第一批,则将其添加到hash table并保存在内存中,否则它将被写入临时文件(每个批处理都有一个单独的文件)。临时文件的总量由temp_file_limit参数限制。
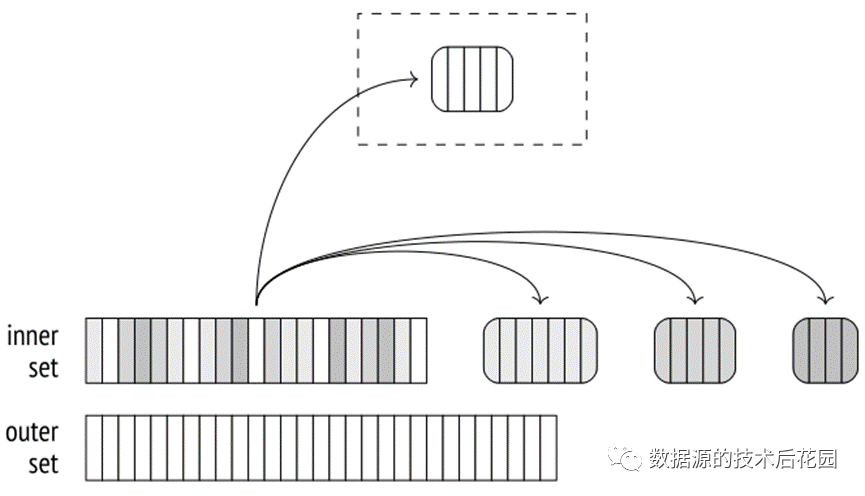 |
在第二阶段中,扫描外部集合。如果该行属于第一批,它将与内部行集第一批行的hash table进行匹配。如果该行属于不同的批处理,则将其存储在临时文件中。因此,N批可以使用2(N-1)个文件。一旦第二阶段完成,为哈希表分配的内存将被释放。此时已经完成了其中一个批次的连接结果。
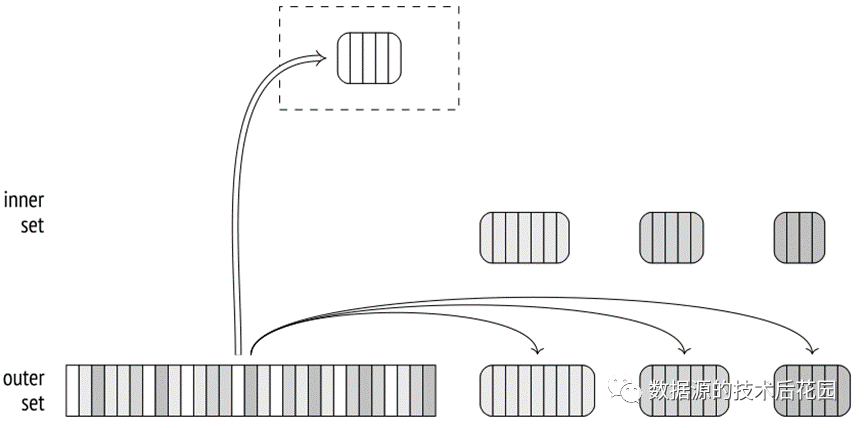 |
对于保存在磁盘上的每批数据,都要重复这两个阶段:内部数据集的行从临时文件转移到哈希表;然后从另一个临时文件中读取与同一批处理相关的外部集的行,并与此哈希表进行匹配。一旦处理,临时文件将被删除。
与One-Pass Hash Join不同,Two-Pass Hash Join的执行计划输出中包含多个批处理,如下图所示,其中Batches:64代表第一阶段中拆分为64个批次进行处理。
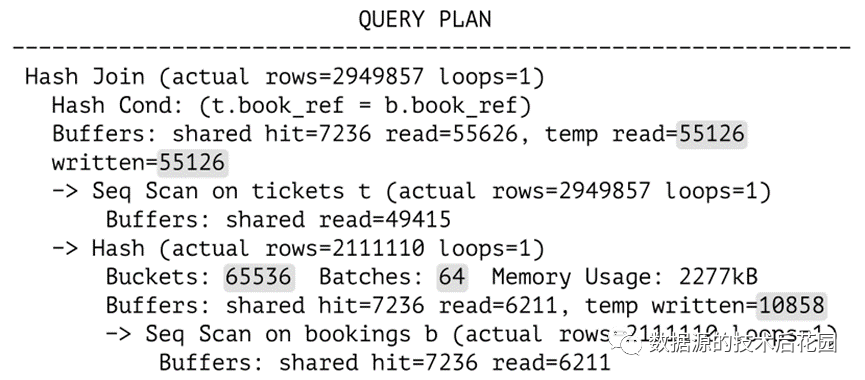 |
本篇简单谈谈基本的Hash Join原理以及什么是One-Pass哈希连接、Two-Pass哈希连接,实际上,不管是One-Pass还是Two-Pass,他们内部在某些操作上面还可以进行并行操作,本篇暂不讨论相关内容。
