




备注:本文仅供学习

2023/12/17
SUNDAY
Good company on the road is the shortest cut.
行路有良伴就是捷径。

01
为什么「需要下载抖音视频」
打开抖音,我们总能看到来自不同领域与方向上的不同的人,在通过短视频的方式,展现着他们各自的生活的精彩与对生活的理解和感悟。
这里面有很多人都是大家很熟悉的:
作为观众,有的视频做得很好,可能你想存下来,在自己的朋友圈里面分享;
作为作者,有一天你发现自己的账号上有了成百上千的视频后,你有的可能想要留存备份,于是你也需要下载下来;
但是,在今天,当你要下载多条视频的时候,你会发现抖音官方其实是没有提供方法与工具去让你完成这么一个操作的。
那么,作为普通用户,能做的选择只有三个:
自己一个个的,手动下载成百上千个视频,点到手指发麻
在百度上搜索各种小助手小工具,在自己电脑上打开后,发现有的工具根本不能用,有的工具虽然可以用,但是到了批量下载的时候,或者下载了10条20条视频后,作者给你发了付款码,开始收费了
在百度上搜各种免费下载抖音视频的教程,要么操作性不强,要么操作起来太过复杂
因此,为了解决这样一个问题,也方便自己下载自己的抖音视频,我写了这么一个工具,并将它分享(OpenSouce)出来。
每个人,不论使用的是 Apple MacOS的电脑,还是 Microsoft Windows的电脑,都可以在自己的电脑上,简单的安装好Python的运行环境,便可以直接执行改脚本,获取想要获取的视频。
注意,该脚本是出于学习的目的开发的,... 请不要用该脚本下载视频后,二次发布,侵犯原作者的原创视频,创作不易,尊重原创。
02
执行效果
执行过程:
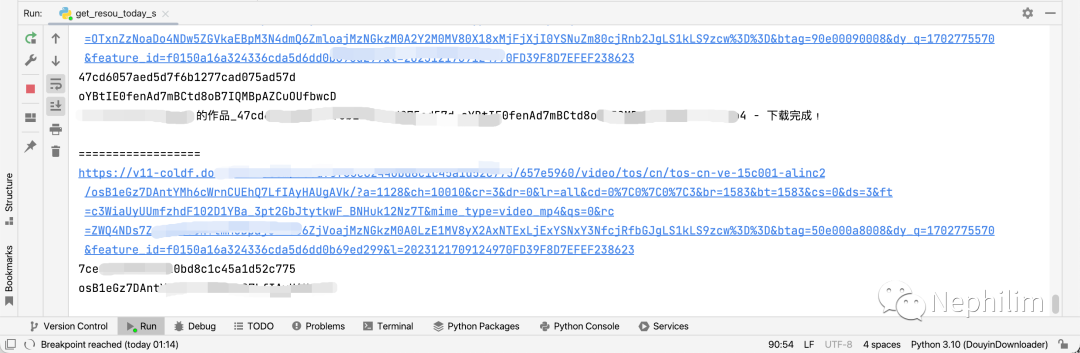
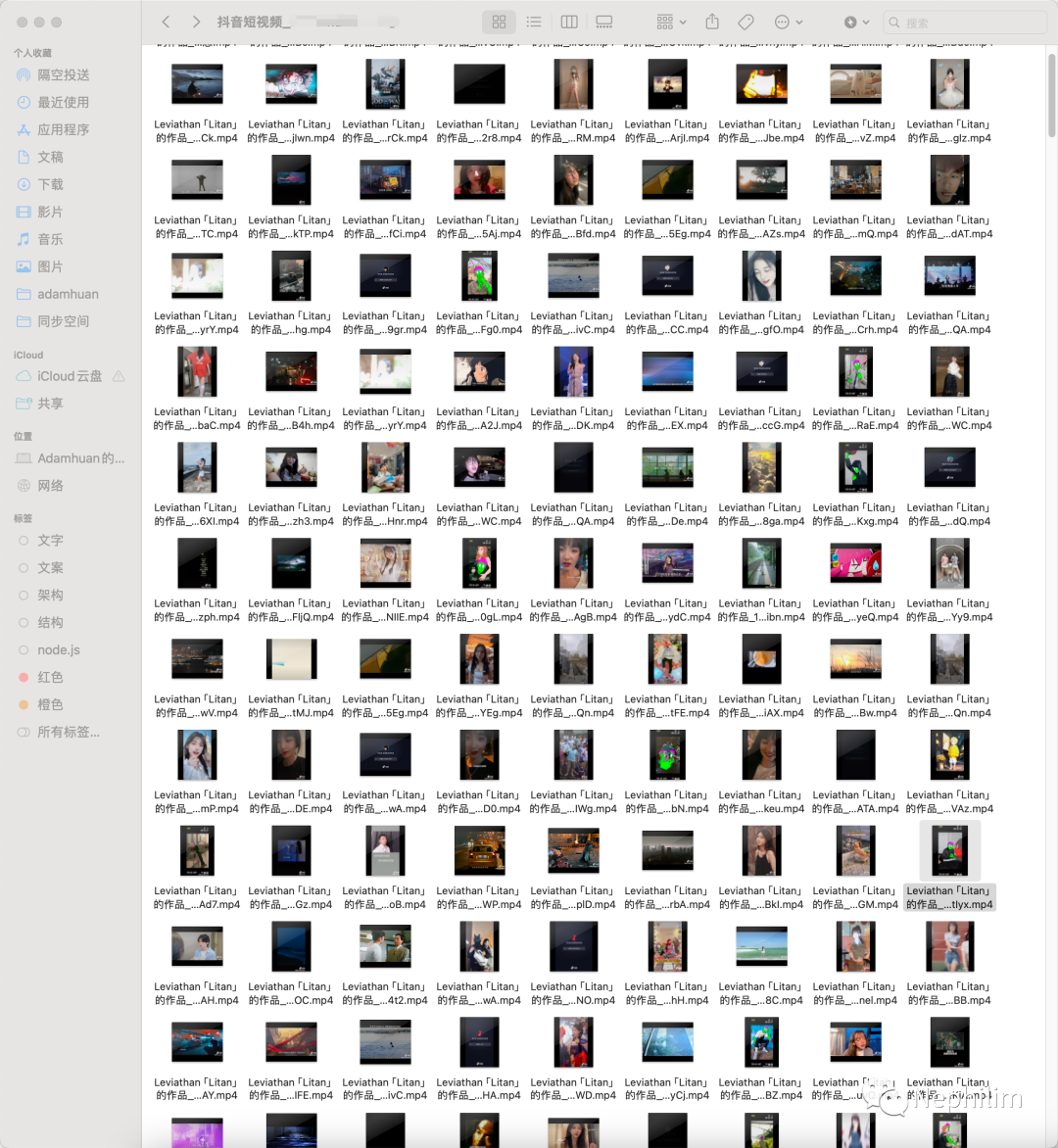
下载目录:
03
源码
该脚本的源码如下:
# -*- coding: utf-8 -*-# ))))))))) 模块包导入import osimport requestsimport randomimport timeimport urllib3# ))))))))) 函数定义def timestamp():'''生成时间戳:return:'''min_t = int(time.time())max_t = int(time.time() * 1000)return str(min_t), str(max_t)def fabu_time(t):'''将时间戳转换成时间格式:param t::return:'''timeArray = time.localtime(t)fabu_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)return fabu_timedef save(dict):'''传入字典保存数据:param dict::return:'''# 有些短视频中没有标题导致我们再保存数据时会覆盖,所以我们对没有标题的短视频进行命名num = str(random.randint(0, 100))print('==================')print(dict['video_url'])print(dict['video_url'].split('/')[3])print(dict['video_url'].split('/')[9])if dict['desc'] == '':# name = dict['user_name'] + '的作品{}'.format(num) + '.mp4'name = dict['user_name'] + '的作品_' + dict['video_url'].split('/')[3] + '-' + dict['video_url'].split('/')[9] + '.mp4'else:name = dict['user_name'] + '的作品_' + dict['desc'] + '.mp4'video_url = dict['video_url']res = requests.get(video_url)dirctory_name = 'douyin_download/抖音短视频_' + dict['user_name']file_name_full = dirctory_name + '/' + name# if os.path.exists(dirctory_name):# with open(dirctory_name + '/' + name, 'wb') as f:# f.write(res.content)# print('{}下载完成!'.format(name))# else:# os.mkdir(dirctory_name)# with open(dirctory_name + '/' + name, 'wb') as f:# f.write(res.content)# print('{}下载完成!'.format(name))if not os.path.exists(dirctory_name):os.mkdir(dirctory_name)if not os.path.exists(file_name_full):try:with open(file_name_full, 'wb') as f:f.write(res.content)print('{} - 下载完成!'.format(name))except OSError as os_err:# OSError: [Errno 63] File name too longif os_err.errno == 63:print('您遇到了【文件名过长】的错误 - 下面进行错误处理')name_2 = dict['user_name'] + '的作品_' + dict['video_url'].split('/')[3] + '-' + \dict['video_url'].split('/')[9] + '.mp4'file_name_full_2 = dirctory_name + '/' + name_2if not os.path.exists(file_name_full_2):with open(file_name_full_2, 'wb') as f:f.write(res.content)print('{} - 下载完成!'.format(name_2))else:print('{} - 已存在!'.format(name_2))else:print('{} - 已存在!'.format(name))# 结束print()def get_data(url):'''根据请求url获取数据:param url::return:data:list数据max_cursor:下次请求需要携带的参数'''while True:min_t, max_t = timestamp()headers = {'Connection': 'keep-alive','Cookie': 'd_ticket=4c5b44a063bf078fae71bffec25ddad8ca4ea; odin_tt=6450ec41def6afd0731d426731b508fcf43650505f50460244a368ac5847f0d1cbf6747a7ad4e89fa3b0f0e15754002e; sid_guard=a6001040b2e52133062ca1e743097c06%7C1588771917%7C5183999%7CSun%2C+05-Jul-2020+13%3A31%3A56+GMT; uid_tt=de424823d2132aab28fa581760578e06; uid_tt_ss=de424823d2132aab28fa581760578e06; sid_tt=a6001040b2e52133062ca1e743097c06; sessionid=a6001040b2e52133062ca1e743097c06; sessionid_ss=a6001040b2e52133062ca1e743097c06; install_id=4019449375779358; ttreq=1$4e594dc75197827452871cc4798ece9879de8c47','X-SS-REQ-TICKET': '1588773397905','X-Tt-Token': '00a6001040b2e52133062ca1e743097c06cdb862c09a8bd8d850534d8a1ddf1bcda1297dfe483093add3539ae384dd657413','sdk-version': '1','X-SS-DP': '1128','x-tt-trace-id': '00-ea46271a0d9c7aafc2c2647f8e990468-ea46271a0d9c7aaf-01','User-Agent': 'com.ss.android.ugc.aweme/100901 (Linux; U; Android 5.1.1; zh_CN; SM-N960F; Build/JLS36C; Cronet/TTNetVersion:8109b77c 2020-04-15 QuicVersion:0144d358 2020-03-24)','Accept-Encoding': 'gzip','X-Gorgon': '0404b8014001a0ff70a608a72b1c1754b85bab86f700fceac8f4','X-Khronos': min_t,'x-common-params-v2': 'os_api=22&device_platform=android&device_type=SM-N960F&iid=4019449375779358&version_code=100900&app_name=aweme&openudid=9a7fc881896f46bf&device_id=2752811979515463&os_version=5.1.1&aid=1128&channel=tengxun_new&ssmix=a&manifest_version_code=100901&dpi=240&cdid=1421f378-62fa-44ad-af4f-49d33aa7a58a&version_name=10.9.0&resolution=720*1280&language=zh&device_brand=samsung&app_type=normal&ac=wifi&update_version_code=10909900&uuid=355757648741243'}urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)response = requests.get(url, headers=headers, verify=False).json()try:max_cursor = response['max_cursor']if not response['aweme_list']:passelse:data = response['aweme_list']return data, max_cursorexcept:data = Nonemax_cursor = Nonereturn data, max_cursordef data_parse(data):'''用户短视频数据解析:param data::return:'''production_list = []for i in data:production_dict = {'user_name': i['author']['nickname'],'desc': i['desc'],'time': fabu_time(i['create_time']),'music_author': i['music']['author'],'music_name': i['music']['title'],'video_url': i['video']['play_addr_lowbr']['url_list'][0]}production_list.append(production_dict)return production_list# headers数据参数不正确请求不到数据def attention_me_uid(url):'''获取我关注的抖音用户的uid与下一页请求锁需要的参数:return:'''while True:min_t, max_t = timestamp()headers = {'Connection': "keep-alive",'Cookie': 'd_ticket=4c5b44a063bf078fae71bffec25ddad8ca4ea; odin_tt=6450ec41def6afd0731d426731b508fcf43650505f50460244a368ac5847f0d1cbf6747a7ad4e89fa3b0f0e15754002e; sid_guard=a6001040b2e52133062ca1e743097c06%7C1588771917%7C5183999%7CSun%2C+05-Jul-2020+13%3A31%3A56+GMT; uid_tt=de424823d2132aab28fa581760578e06; uid_tt_ss=de424823d2132aab28fa581760578e06; sid_tt=a6001040b2e52133062ca1e743097c06; sessionid=a6001040b2e52133062ca1e743097c06; sessionid_ss=a6001040b2e52133062ca1e743097c06; install_id=4019449375779358; ttreq=1$4e594dc75197827452871cc4798ece9879de8c47','X-SS-REQ-TICKET': '1588777054732','X-Tt-Token': '00a6001040b2e52133062ca1e743097c06cdb862c09a8bd8d850534d8a1ddf1bcda1297dfe483093add3539ae384dd657413','sdk-version': '1','X-SS-DP': '1128','x-tt-trace-id': '00-ea7df3860d9c7aafc2c2647233a00468-ea7df3860d9c7aaf-01','User-Agent': 'com.ss.android.ugc.aweme/100901 (Linux; U; Android 5.1.1; zh_CN; SM-N960F; Build/JLS36C; Cronet/TTNetVersion:8109b77c 2020-04-15 QuicVersion:0144d358 2020-03-24)','Accept-Encoding': 'gzip','X-Gorgon': '0404b8014001fc330e5d08a72b1c1754b85bab86f700fca29ee3','X-Khronos': min_t,'x-common-params-v2': 'os_api=22&device_platform=android&device_type=SM-N960F&iid=4019449375779358&version_code=100900&app_name=aweme&openudid=9a7fc881896f46bf&device_id=2752811979515463&os_version=5.1.1&aid=1128&channel=tengxun_new&ssmix=a&manifest_version_code=100901&dpi=240&cdid=1421f378-62fa-44ad-af4f-49d33aa7a58a&version_name=10.9.0&resolution=720*1280&language=zh&device_brand=samsung&app_type=normal&ac=wifi&update_version_code=10909900&uuid=355757648741243'}urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)response = requests.get(url, headers=headers, verify=False).json()print(response)try:max_time = response['max_time']if not response['followings']:passelse:data = response['followings']return data, max_timeexcept:data = Nonemax_cursor = Nonereturn data, max_cursor# 将获取到的关注的抖音用户数据进行解析def uid_parse(data):'''传入的是列表:param data::return:'''user_list = []for i in data:user_dict = {'sec_uid': i['sec_uid']}user_list.append(user_dict)return user_list# 第一次请求时携带的max_time,将max_time 传入后获取关注抖音用户列表def first_user():min_t, max_t = timestamp()url = 'https://api3-normal-c-lq.amemv.com/aweme/v1/user/following/list/?user_id=86304636253&sec_user_id=MS4wLjABAAAAliUfImgLRYe1ih0ZL0_GQ3dzUAOGZ1JEInos9icA04w&max_time=0&count=20&offset=0&source_type=2&address_book_access=2&gps_access=1&vcd_count=0&vcd_auth_first_time=0&ts={}&host_abi=armeabi-v7a&_rticket={}&mcc_mnc=46007&'.format(min_t, max_t)headers = {'Connection': 'keep-alive','Cookie': 'd_ticket=4c5b44a063bf078fae71bffec25ddad8ca4ea; odin_tt=6450ec41def6afd0731d426731b508fcf43650505f50460244a368ac5847f0d1cbf6747a7ad4e89fa3b0f0e15754002e; sid_guard=a6001040b2e52133062ca1e743097c06%7C1588771917%7C5183999%7CSun%2C+05-Jul-2020+13%3A31%3A56+GMT; uid_tt=de424823d2132aab28fa581760578e06; uid_tt_ss=de424823d2132aab28fa581760578e06; sid_tt=a6001040b2e52133062ca1e743097c06; sessionid=a6001040b2e52133062ca1e743097c06; sessionid_ss=a6001040b2e52133062ca1e743097c06; install_id=4019449375779358; ttreq=1$4e594dc75197827452871cc4798ece9879de8c47','X-SS-REQ-TICKET': '1588780059093','X-Tt-Token': '00a6001040b2e52133062ca1e743097c06cdb862c09a8bd8d850534d8a1ddf1bcda1297dfe483093add3539ae384dd657413','sdk-version': '1', 'X-SS-DP': '1128','x-tt-trace-id': '00-eaabcb4c0d9c7aafc2c26472519d0468-eaabcb4c0d9c7aaf-01','User-Agent': 'com.ss.android.ugc.aweme/100901 (Linux; U; Android 5.1.1; zh_CN; SM-N960F; Build/JLS36C; Cronet/TTNetVersion:8109b77c 2020-04-15 QuicVersion:0144d358 2020-03-24)','Accept-Encoding': 'gzip', 'X-Gorgon': '0404b8014001be0483eb08a72b1c1754b85bab86f700fc923f8b','X-Khronos': '1588780059','x-common-params-v2': 'os_api=22&device_platform=android&device_type=SM-N960F&iid=4019449375779358&version_code=100900&app_name=aweme&openudid=9a7fc881896f46bf&device_id=2752811979515463&os_version=5.1.1&aid=1128&channel=tengxun_new&ssmix=a&manifest_version_code=100901&dpi=240&cdid=1421f378-62fa-44ad-af4f-49d33aa7a58a&version_name=10.9.0&resolution=720*1280&language=zh&device_brand=samsung&app_type=normal&ac=wifi&update_version_code=10909900&uuid=355757648741243'}urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)response = requests.get(url, headers=headers, verify=False).json()print(response)# 一边循环获取关注的抖音用户的sec_uid一边对单个用户进行数据的爬取def run():max_time = 1588778511while True:min_t, max_t = timestamp()url = 'https://api3-normal-c-lq.amemv.com/aweme/v1/user/following/list/?user_id=86304636253&sec_user_id=MS4wLjABAAAAliUfImgLRYe1ih0ZL0_GQ3dzUAOGZ1JEInos9icA04w&max_time={}&count=20&offset=0&source_type=1&address_book_access=2&gps_access=1&vcd_count=0&vcd_auth_first_time=0&ts={}4&host_abi=armeabi-v7a&_rticket={}&mcc_mnc=46007&'.format(max_time, min_t, max_t)print(url)data, max_time = attention_me_uid(url)print(data)if data is not None and max_time is not None:user_list = uid_parse(data)for user in user_list:sec_uid = user['sec_uid']user_get(sec_uid)else:print('您关注的抖音用户已爬完!')break# 爬取目标用户的所有发布的抖音作品def user_get(sec_uid):'''传入目标抖音用户的sec_uid对单个抖音用户循环爬取所有短视频:param sec_uid::return:'''max_cursor = 0while True:min_t, max_t = timestamp()url = 'https://api3-normal-c-lq.amemv.com/aweme/v1/aweme/post/?source=0&publish_video_strategy_type=0&max_cursor={}&sec_user_id={}&count=20&ts={}&host_abi=armeabi-v7a&_rticket={}&mcc_mnc=46007&'.format(max_cursor, sec_uid, min_t, max_t)data, max_cursor = get_data(url)if data is not None and max_cursor is not None:production_list = data_parse(data)for production in production_list:save(production)else:print('您喜欢的抖音用户已爬完!')break# ))))))))) 执行阶段if __name__ == '__main__':# 抖音用户「UID」# 王德芙的个人主页sec_uid = 'MS4wLjABAAAAiXeL8UUfi0KfVrjbpc2LJKSGiPXEBomMz5i_DCbDsSYXhCJ6PZm9c7DUE1KCQ2cy'# 爬取用户视频user_get(sec_uid)
上面的「sec_uid」可以在电脑版的网页上登录抖音后查到;
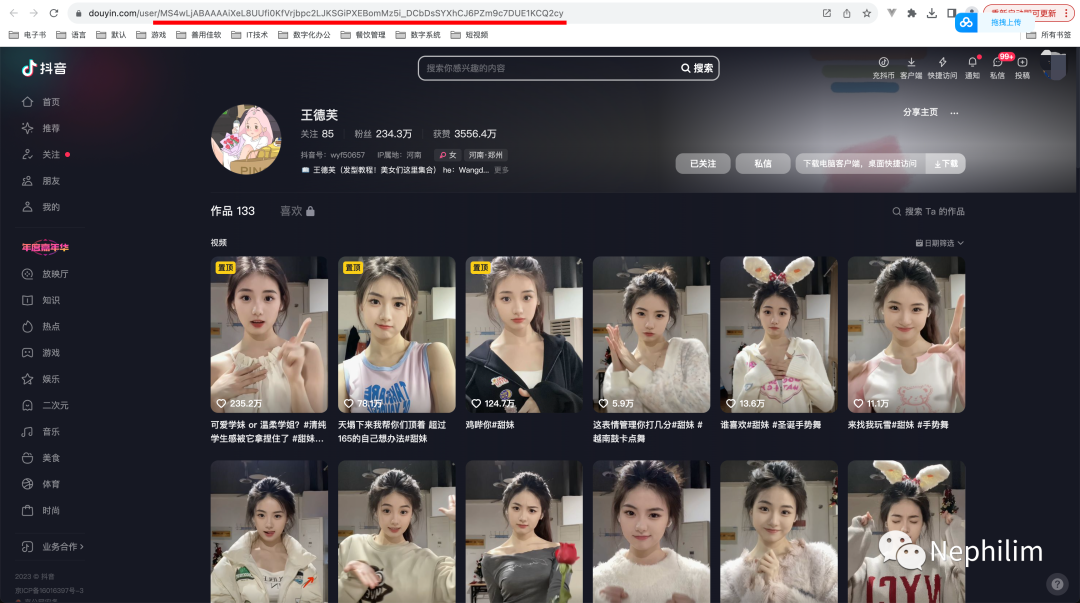
具体方法如下:这里以「王德芙」为例
先搜索感兴趣的用户:
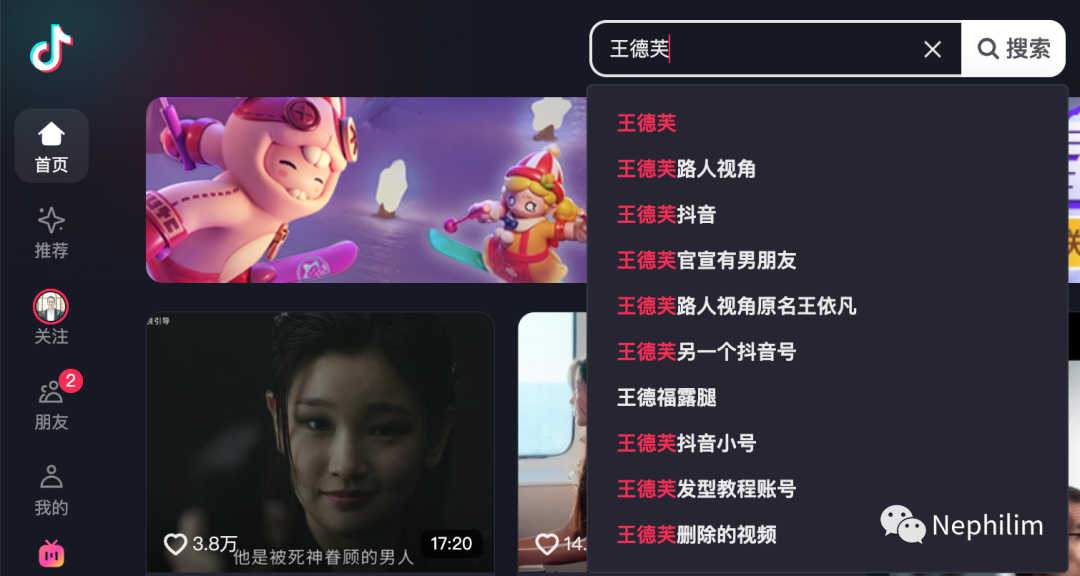
搜索结果:
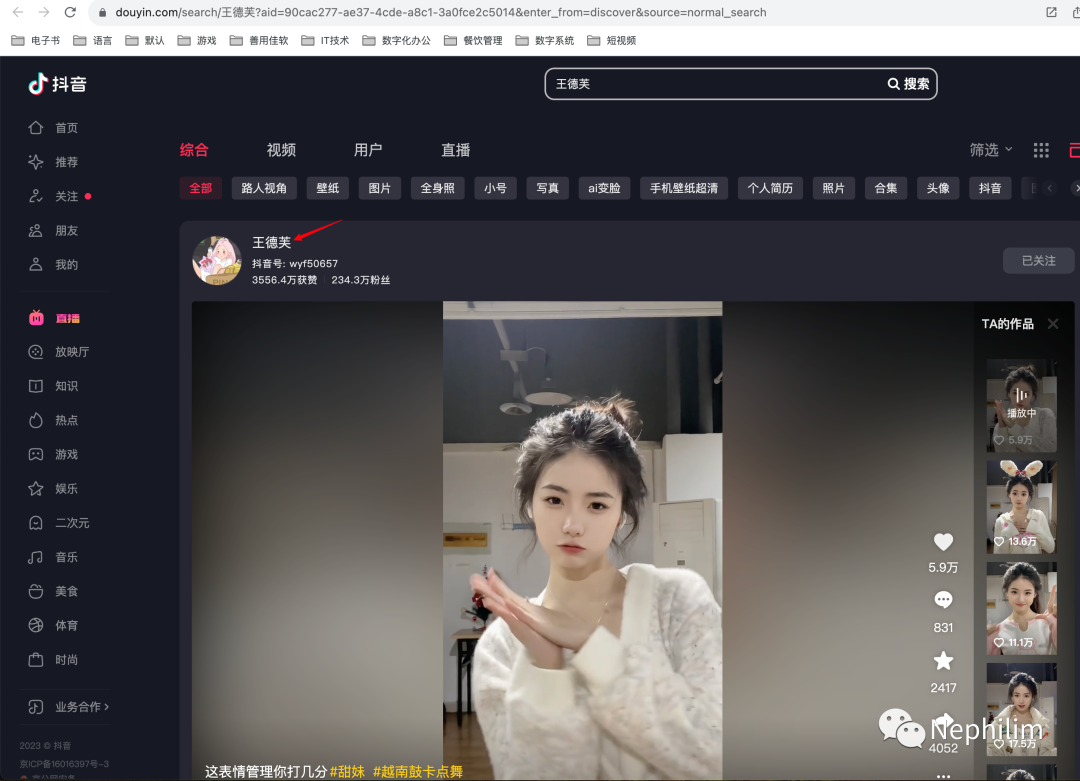
点击进去后,下图高亮标注的部分,就是「sec_uid」了:
该脚本的原理:
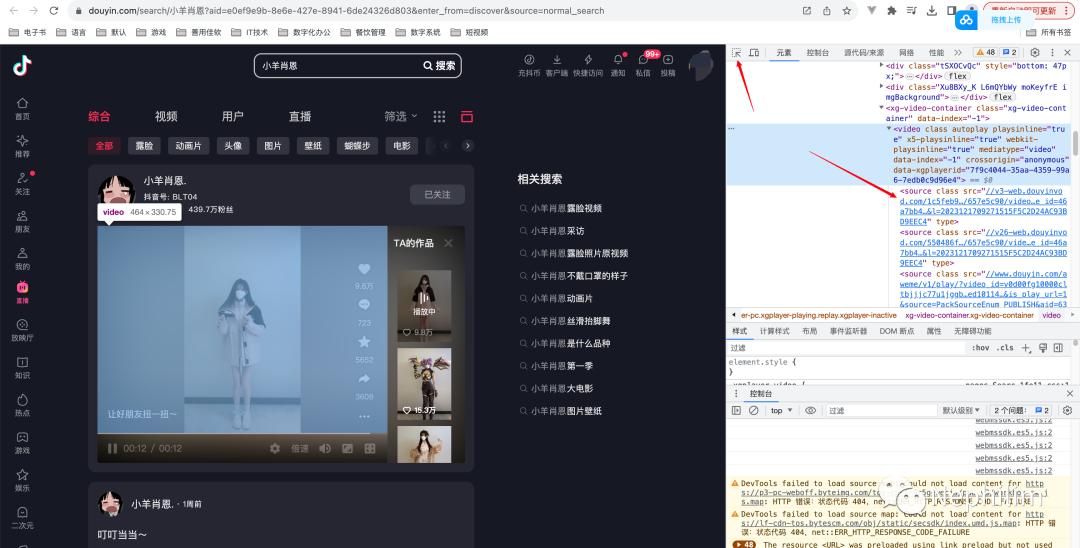
打开浏览器的开发者工具后(F12),可以在「要素」中定位到你要审查的元素,比方说这里我们审查的是网页视频;
然后,你就可以在「video」标签下,获得具体视频的「src」地址;
在上面截图中,我们获得到的地址是:
//v3-web.douyinvod.com/1c5feb9c7a8e48f3cf93510f0ba27cb8/657e5c90/video/tos/cn/tos-cn-ve-15/ocBRUahEIAgynovNCvfN6Dl2yzzC4AAnzBVeQB/?a=6383&ch=10010&cr=3&dr=0&lr=all&cd=0%7C0%7C0%7C3&cv=1&br=847&bt=847&cs=0&ds=4&ft=LjhJEL998xI7uEPmD0P5H4eaciDXtUrBi_QEeH1hR_PD1Inz&mime_type=video_mp4&qs=0&rc=MzY8ZmVpaGdpM2ZlZDg3M0BpM25lajQ6Zm1lbzMzNGkzM0AwYzBjYjNeNi8xX14xXjZgYSNtYGRncjRnZ3FgLS1kLWFzcw%3D%3D&btag=e00008000&dy_q=1702776436&feature_id=46a7bb47b4fd1280f3d3825bf2b29388&l=2023121709271515F5C2D24AC93BD9EEC4
在前面补全「http:」之后,就构成了一个完整的HTTP的访问地址,这样就可以丢到迅雷或者通过浏览器本身的功能进行下载操作了。
温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注我。
