




导读
我们知道ibd2sql可以解析ibd文件从而恢复mysql的数据, 但没得ibd文件的时候又该怎么办呢? (哎呀, 不小心drop了表, 又没得备份!)
这时候就需要先从文件系统恢复数据文件了. mysql通常运行在linux服务器上, 通常是使用的xfs文件系统, 市面上也有不少该类工具, 有收费的, 也有免费的(比如testdisk,支持多种OS/FS). 但在下愚钝,用不太来…

那就自己来解析xfs文件系统吧. linux的文档是非常完善的, 基本上不需要看源码(虽然也才5MB左右).
XFS 文件系统
linux上一切皆文件, 包括xfs文件系统, 也是特殊结构的文件. xfs文件系统由若干个AG(Allocation Groups)组成.(文件可以跨AG). 结构如下:
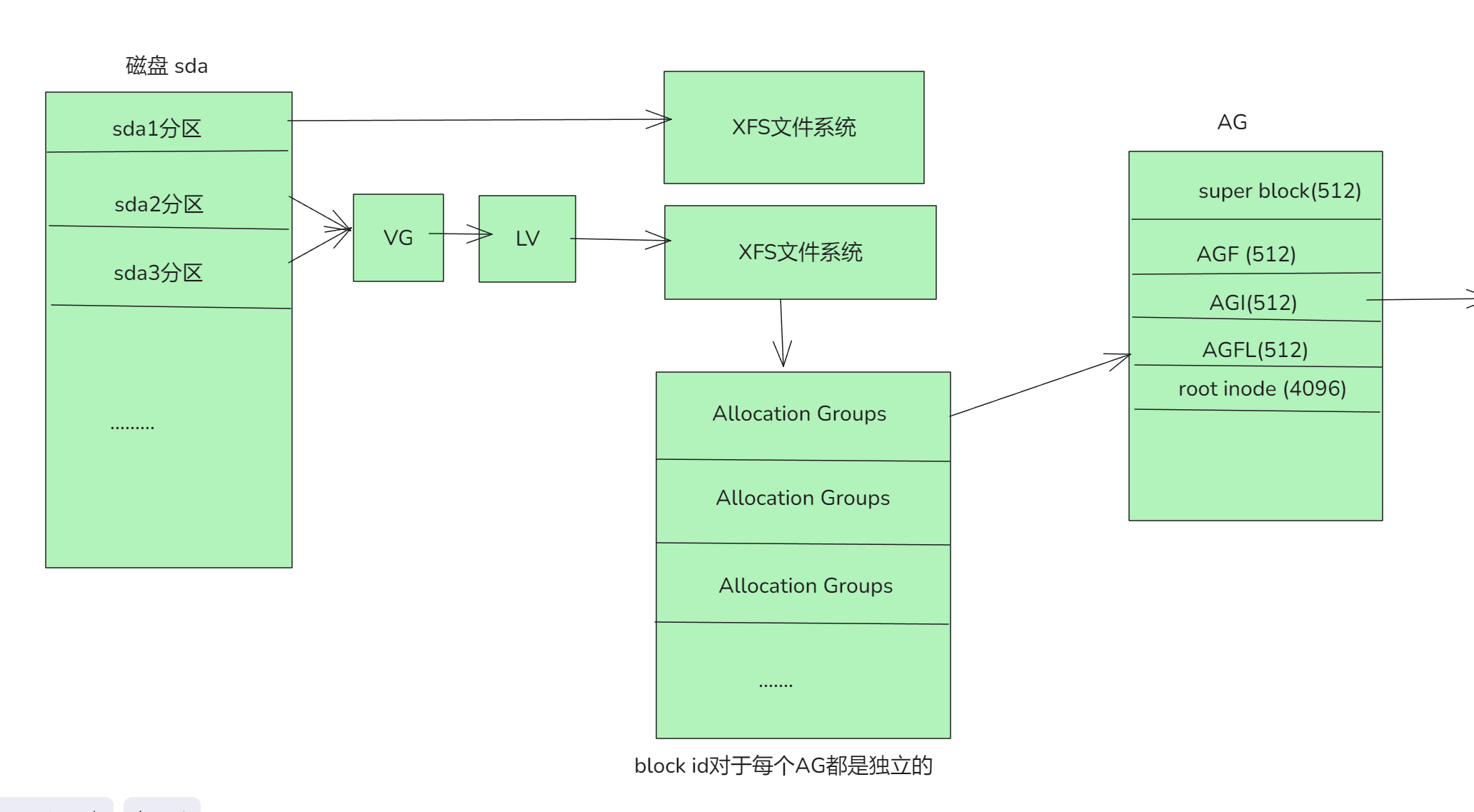
第一个AG中的SB(super block)信息是primary, 其它ag的sb都是备份的. 其中AGI(AG inode btr+ info)记录inode root信息(类似ibd里面的inode page),
结构如下
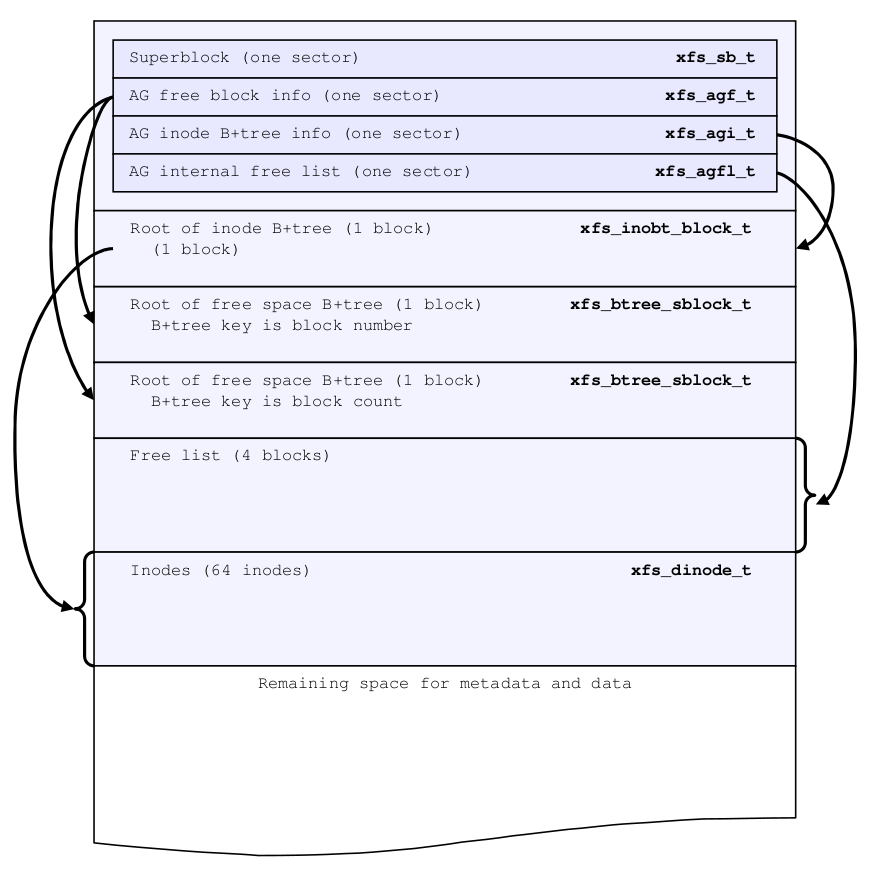
注: 除了日志, xfs均采用大端字节序
SB
超级块, 记录基础信息的, 比如有多少个AG,每个多大,block多大(通常4K),扇区多大(通常512),xfs版本,是否使用bigtime,用了多少个inode之类的信息. 官网有非常详细的描述, 我这里就不介绍了
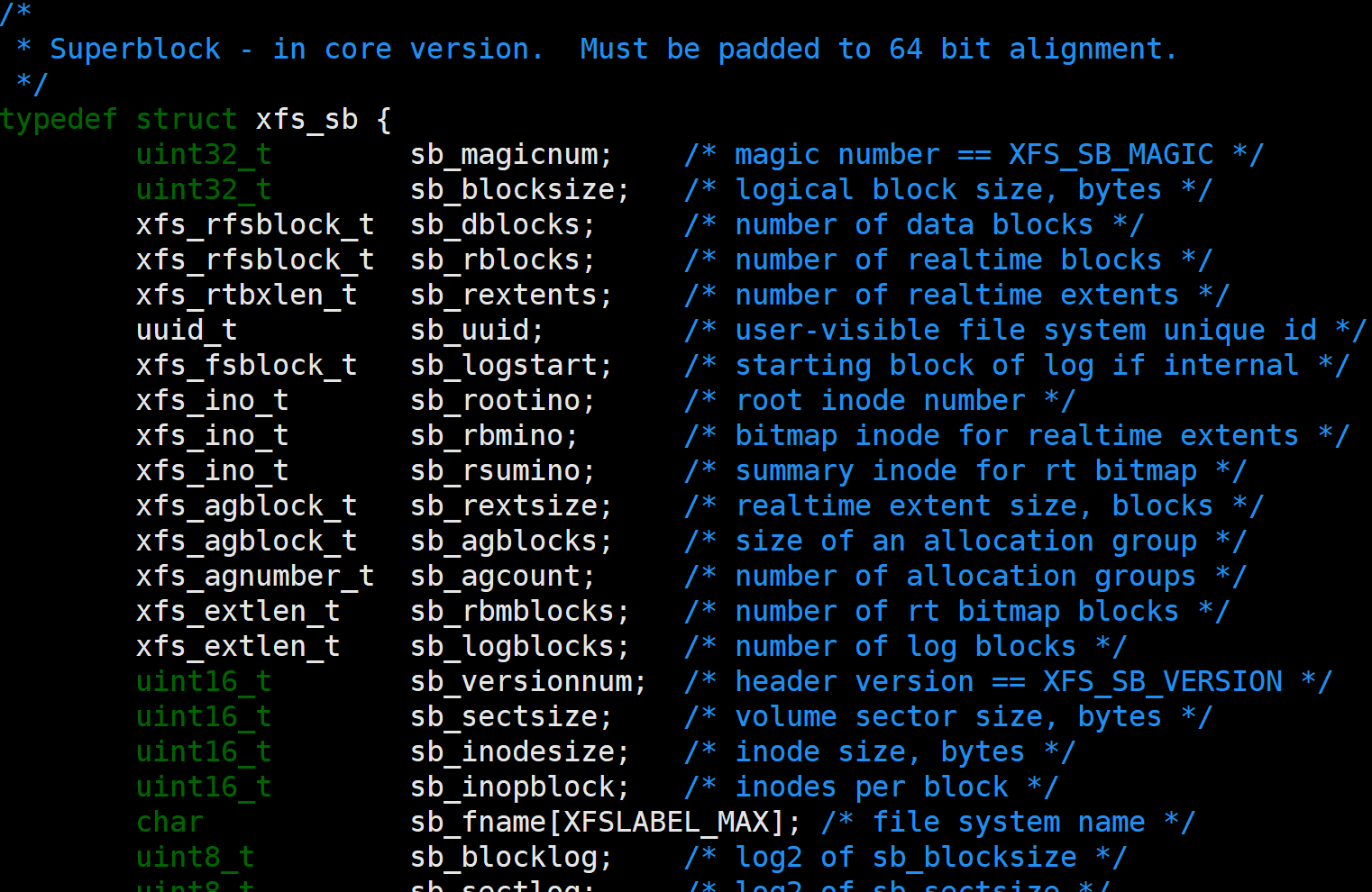
注: block_id是基于AG的, 即每个AG都有一样的block_id
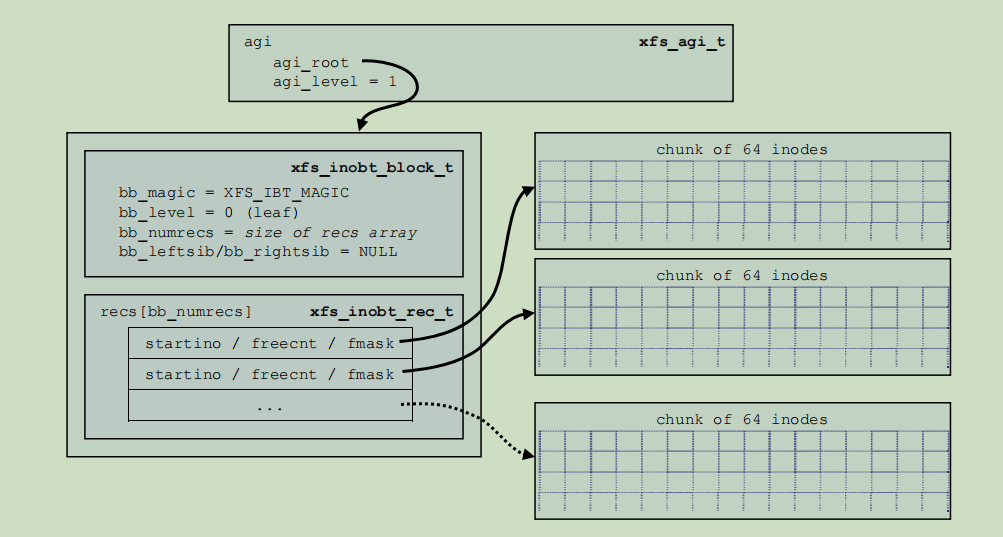
AGI
AGI就是一颗B树, AGI中主要记录树的深度和root地址之类的信息. 其它的基本上都是SB信息 具体如下:
| 对象 | 大小 | 描述 |
|---|---|---|
| magic | 4 | 固定为:XAGI |
| versionnum | 4 | 1 |
| seqno | 4 | ag号 |
| length | 4 | AG多大 |
| count | 4 | … |
| root | 4 | btr的root节点的block位置 |
| … | … | … |
INODE
通过AGI我们就找到了这颗btr的root节点, 然后遍历该节点就能访问各文件/目录了. 在此之前,我们先来看看inode号. 我们知道xfs文件系统由全局唯一的Inode号来区分文件. 使用ls -i即可查看文件/目录的indoe号
ll /data/mysql_3306/mysqldata/db2 -ia

这个inode号, 就是记录inode对应位置的. 所以inode号得包含 AGNO,BLOCK_OF_AG之类的信息. 我们可以使用xfs_db (xfs debug)来查看inode号对应的inode信息. (要求先卸载文件系统)
systemctl stop mysqld_3306 umount /dev/vdb xfs_db /dev/vdb
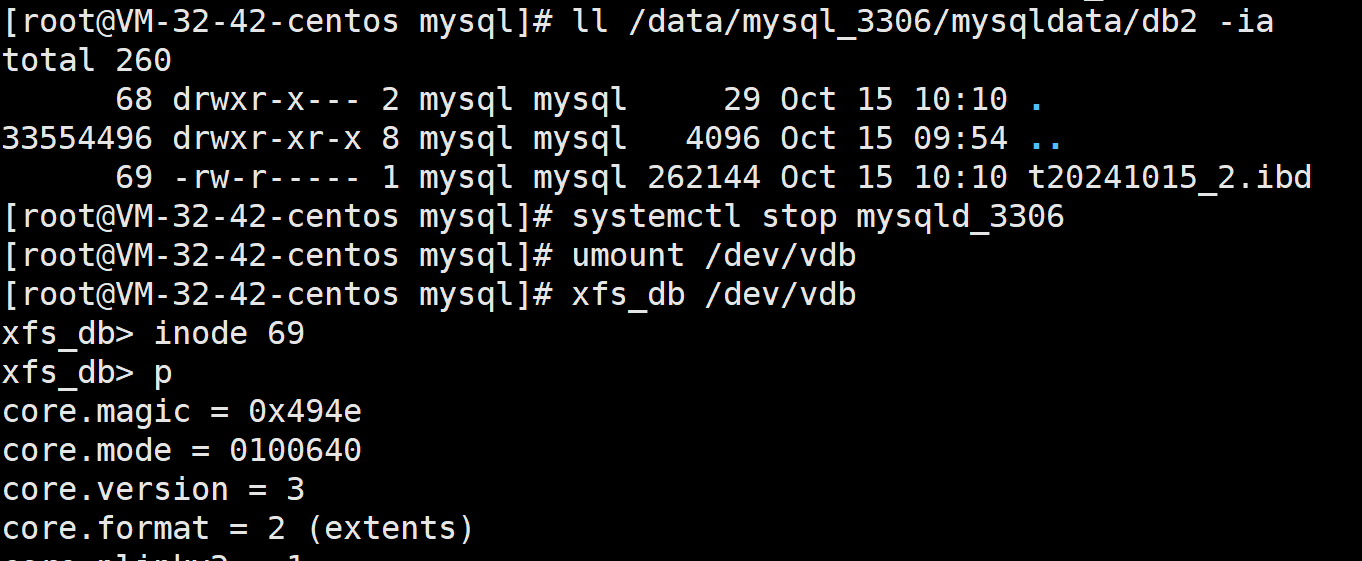
里面记录了文件的大小,修改时间戳, 权限/类型,存储方式等信息. 具体是啥呢? 待会再看.
inode btr
inode占用512字节. 1个block就可以放8个inode. 我们把每8个block作为一个chunk来管理(node节点,就是mysql的非叶子节点). 也就是一个node可以记录64个inode信息. (固定的长度读起来方便很多)
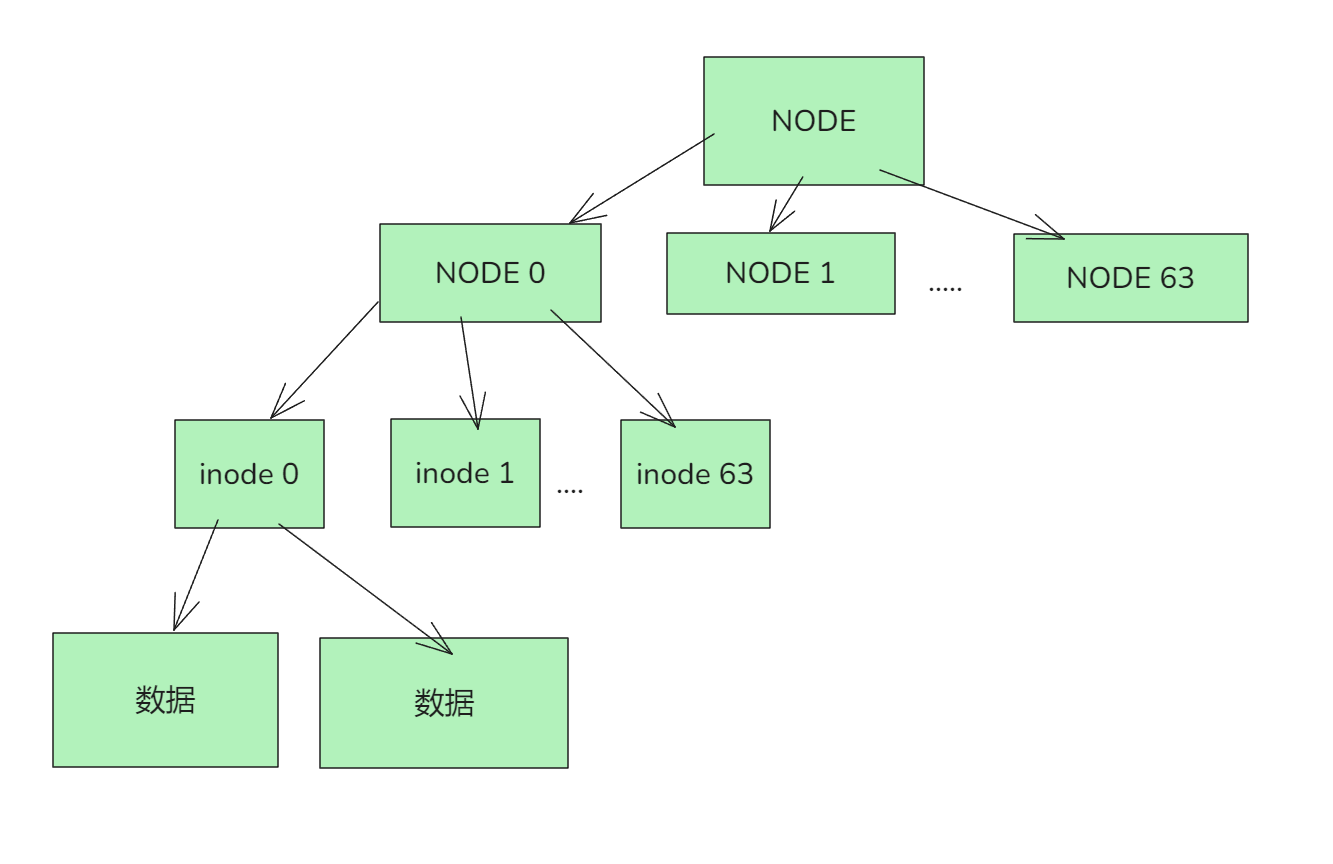
node
先看看node的结构吧, 也有magic(IAB3)之类的信息, 我们主要看rec的结构, 这里才是记录inode的位置的.
| 对象 | 大小 | 描述 |
|---|---|---|
| startino | 4 | inode号起始值, 就是block_id (所以inode号还应该包含位于block中的哪个inode) |
| freecount | 4 | 还有多少inode未分配 |
| mask | 8 | bitmap记录哪些Inode号使用了的,哪些未使用, 未使用的标为1,使用了的标为0. 由于是64个inode(8个block)为一个chunk来管理的, 所以使用64bit(8字节)的bitmap |
注: freecount这样算下来最多就64, 那么使用1字节就够了的其实.
到这里inode号的全貌就出来了. 即: AGNO + BLOCK_IN_AG + OFFSET_IN_BLOCK

inode
现在来看看存数据的inode的结构. 我们使用xfs_db可以得到如下信息:
xfs_db> inode 69
xfs_db> p
core.magic = 0x494e
core.mode = 0100640
core.version = 3
core.format = 2 (extents)
core.nlinkv2 = 1
core.onlink = 0
core.projid_lo = 0
core.projid_hi = 0
core.uid = 1000
core.gid = 1000
core.flushiter = 0
core.atime.sec = Tue Oct 15 10:10:51 2024
core.atime.nsec = 305603329
core.mtime.sec = Tue Oct 15 10:10:51 2024
core.mtime.nsec = 895596684
core.ctime.sec = Tue Oct 15 10:10:51 2024
core.ctime.nsec = 895596684
core.size = 262144
core.nblocks = 64
core.extsize = 0
core.nextents = 3
core.naextents = 0
core.forkoff = 0
core.aformat = 2 (extents)
core.dmevmask = 0
core.dmstate = 0
core.newrtbm = 0
core.prealloc = 1
core.realtime = 0
core.immutable = 0
core.append = 0
core.sync = 0
core.noatime = 0
core.nodump = 0
core.rtinherit = 0
core.projinherit = 0
core.nosymlinks = 0
core.extsz = 0
core.extszinherit = 0
core.nodefrag = 0
core.filestream = 0
core.gen = 896286772
next_unlinked = null
v3.crc = 0x63441afb (correct)
v3.change_count = 73
v3.lsn = 0x10000214b
v3.flags2 = 0
v3.crtime.sec = Tue Oct 15 10:10:51 2024
v3.crtime.nsec = 305603329
v3.inumber = 69
v3.uuid = 2d74d1a0-f4c7-4652-a1a5-3ba4ee9ebea6
u3.bmx[0-2] = [startoff,startblock,blockcount,extentflag] 0:[0,44,4,0] 1:[4,20,24,0] 2:[28,48,36,0]
magic 是固定的值: IN
mode 是文件类型和权限, 这里的文件类型是指该文件是文件还是目录还是块设备之类的. 不是jpg,png这种’自定义文件类型’. 后3*8自己是权限. 文件类型可参考如下:
# 0400000 目录
# 0100000 文件
# 0200000 字符设备
# 0600000 块设备
# 0120000 链接
# 0010000 fifo
format 是该inode的存储方式, 比如1是就放在这inode里面(512字节,前面存基础信息, 后面存数据,比如文件名字). 具体如下:
# 0 dev
# 1 local (就放在这个inode后面, 对于目录文件极少的情况)
# 2 extent 使用最多的情况, 就是一个个连续的块来存
# 3 btree 对于没法使用连续的块,或者大文件的时候,可能就得使用这种btr
# 4 uuid
prealloc等之类的信息这里就不看了…
最后在看一个:
inumber 就是di_ino, 即inode号
我们这里就只讨论 format=extent的情况, 该情况下, 每个块使用16字节来记录块的起始位置,数量等信息.

startoff(logical file block offset) 逻辑位置, 因为是多个连续的块存储的数据, 就需要知道谁在前谁在后, 中间是否有差数据之类的.
startblock(absolute block number) 从哪个块开始, blockid
blockcount(#of blocks) 有多少个块.
比如上图中的数据对应出来就是如下, 第二个连续块和第1个连续块显然位置是反过来的, 这时候,startoff作用就来了.
44 - 48 20 - 44 48 - 84
剩下的就是把这几个块的数据读出来即可.
rm恢复原理
既然我们已经能直接解析xfs来读文件了, 那么对于rm的数据应该就能恢复了, 通常情况下rm之类的删除操作不会重写磁盘(成本太高), 仅修改元数据信息, 比如delete_flag之类的就能实现空间重复利用. 虽然我们没有在inode种找到类似的字段, 但我们删除文件之后发现di_mode,extent之类的信息都不再显示了(xfs_db).

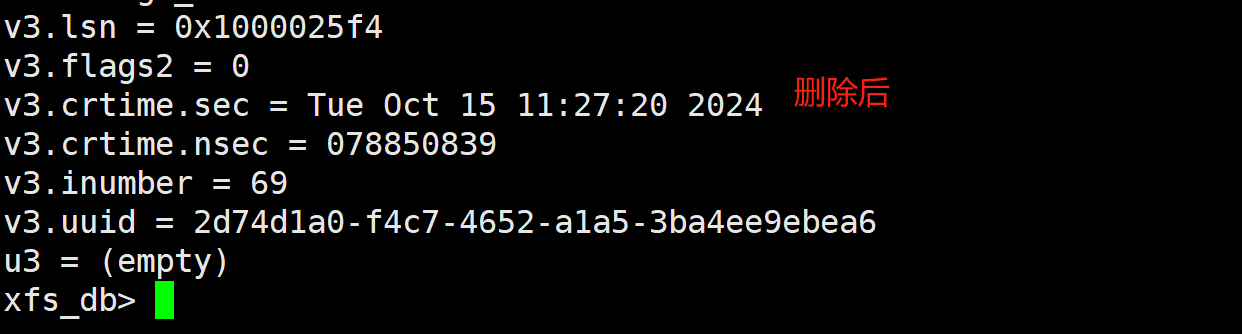
纳里, 已经没得extent之类的信息了么

也可能是xfs_db检查到di_mode之类的信息没了之后, 就不继续解析了, 那我们来解析该inode瞧瞧, 脚本见文末:
python3 xfs_recovery.py /dev/vdb
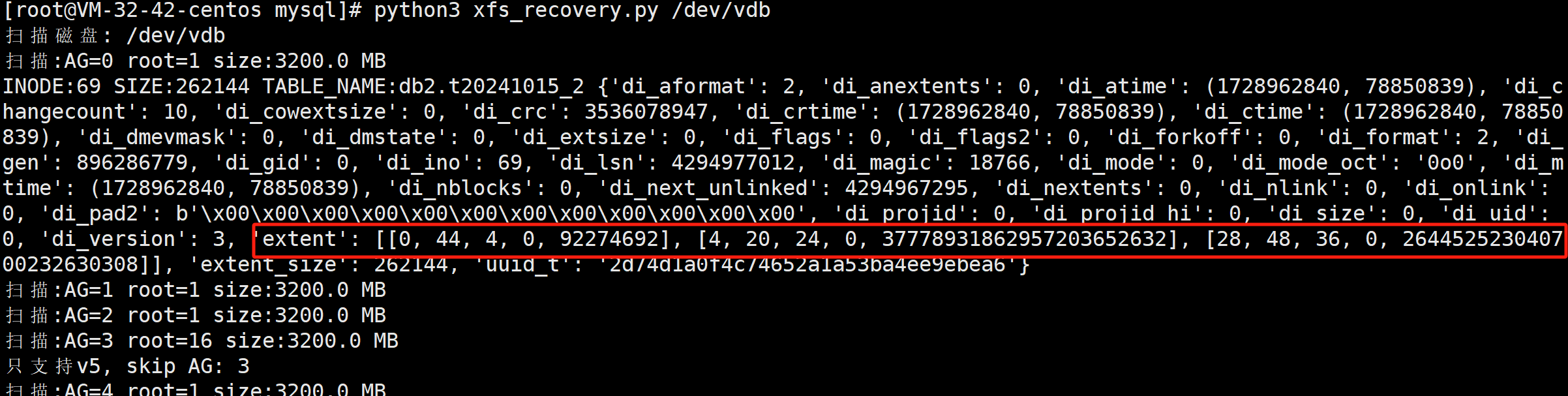
信息确实在, 虽然di_mode之类的信息以已经了, 但extent之类的信息还存在我们就能恢复.
恢复测试
为了方便演示, 我这里就单独给了一块磁盘
准备测试数据:
create table db2.testdrop_20241015(id int primary key auto_increment, name varchar(200));
insert into db2.testdrop_20241015(name) values('ddcw');
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
insert into db2.testdrop_20241015(name) select name from db2.testdrop_20241015;
模拟删除
checksum table db2.testdrop_20241015;
drop table db2.testdrop_20241015;
扫描被删除的表
partprobe /dev/vdb python3 xfs_recovery.py /dev/vdb
如果被删除的表很多的话, 可以使用grep来匹配
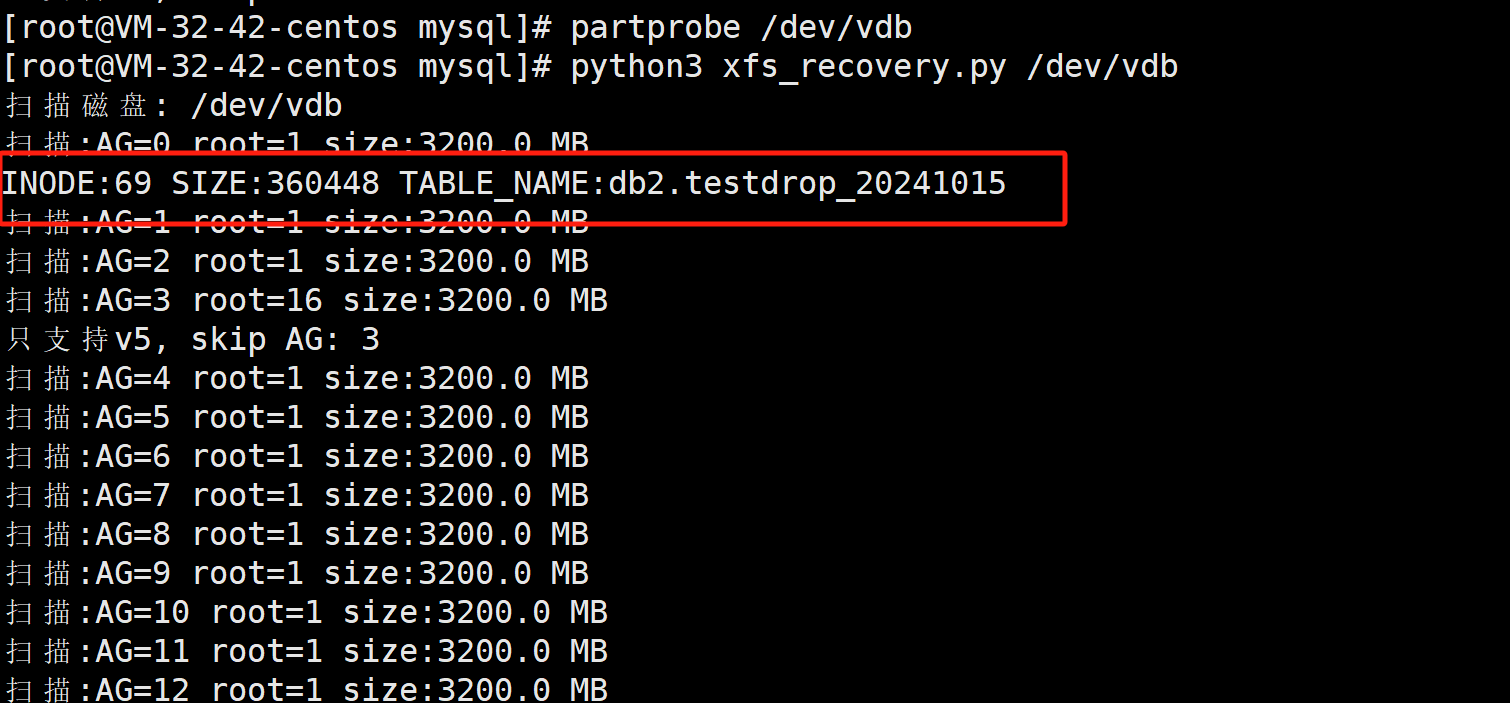
恢复被删除的表
python3 xfs_recovery.py /dev/vdb 69 /tmp/testdrop_20241015.ibd
第一个参数: 磁盘设备 (只有这个参数的时候,就是列出被删除的mysql数据文件)
第二个参数: 要恢复的文件的inode (就是上面扫描出来的文件)
第三个参数: 恢复的文件存放的文件名字.

使用ibd2sql获取该表的表结构
(虽然我们已经知道了表结构, 但实际环境,可能不知道, 所以还是得有解析表结构的这一步)
python3 main.py /tmp/testdrop_20241015.ibd

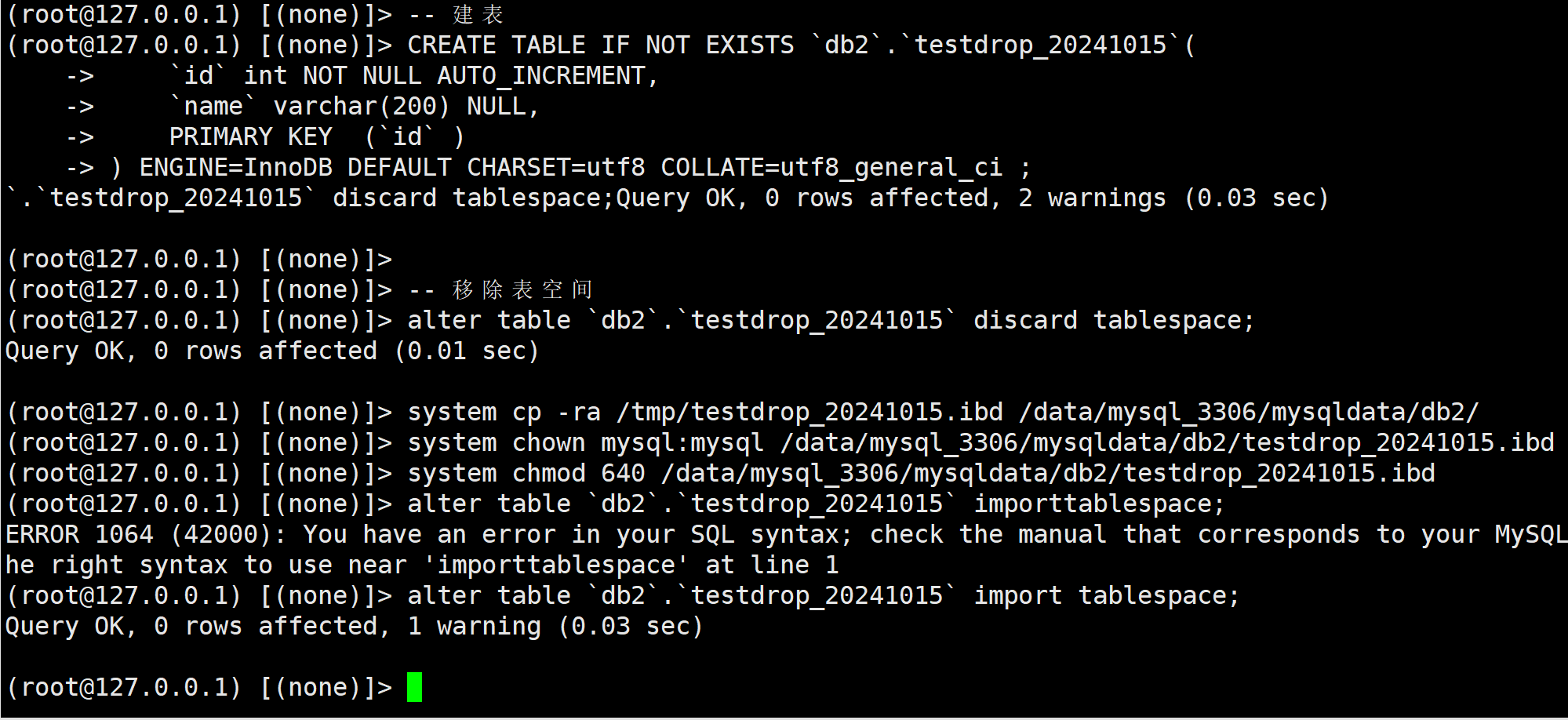
导入数据库
为了方便演示, 我就地恢复的, 实际情况建议恢复到其它环境哈. 磁盘能不动就不动.
-- 建表
CREATE TABLE IF NOT EXISTS `db2`.`testdrop_20241015`(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(200) NULL,
PRIMARY KEY (`id` )
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci ;
-- 移除表空间
alter table `db2`.`testdrop_20241015` discard tablespace;
-- 拷贝我们恢复的表空间过来
system cp -ra /tmp/testdrop_20241015.ibd /data/mysql_3306/mysqldata/db2/
system chown mysql:mysql /data/mysql_3306/mysqldata/db2/testdrop_20241015.ibd
system chmod 640 /data/mysql_3306/mysqldata/db2/testdrop_20241015.ibd
-- 导入表空间
alter table `db2`.`testdrop_20241015` import tablespace;
验证
我们事先校验了crc32值的, 这里就再校验一次了, 实际生产中,得由相关人员去校验(比如校验最新数据是否符合)
checksum table `db2`.`testdrop_20241015`;
select count(*) from `db2`.`testdrop_20241015`;
select * from `db2`.`testdrop_20241015` limit 1;
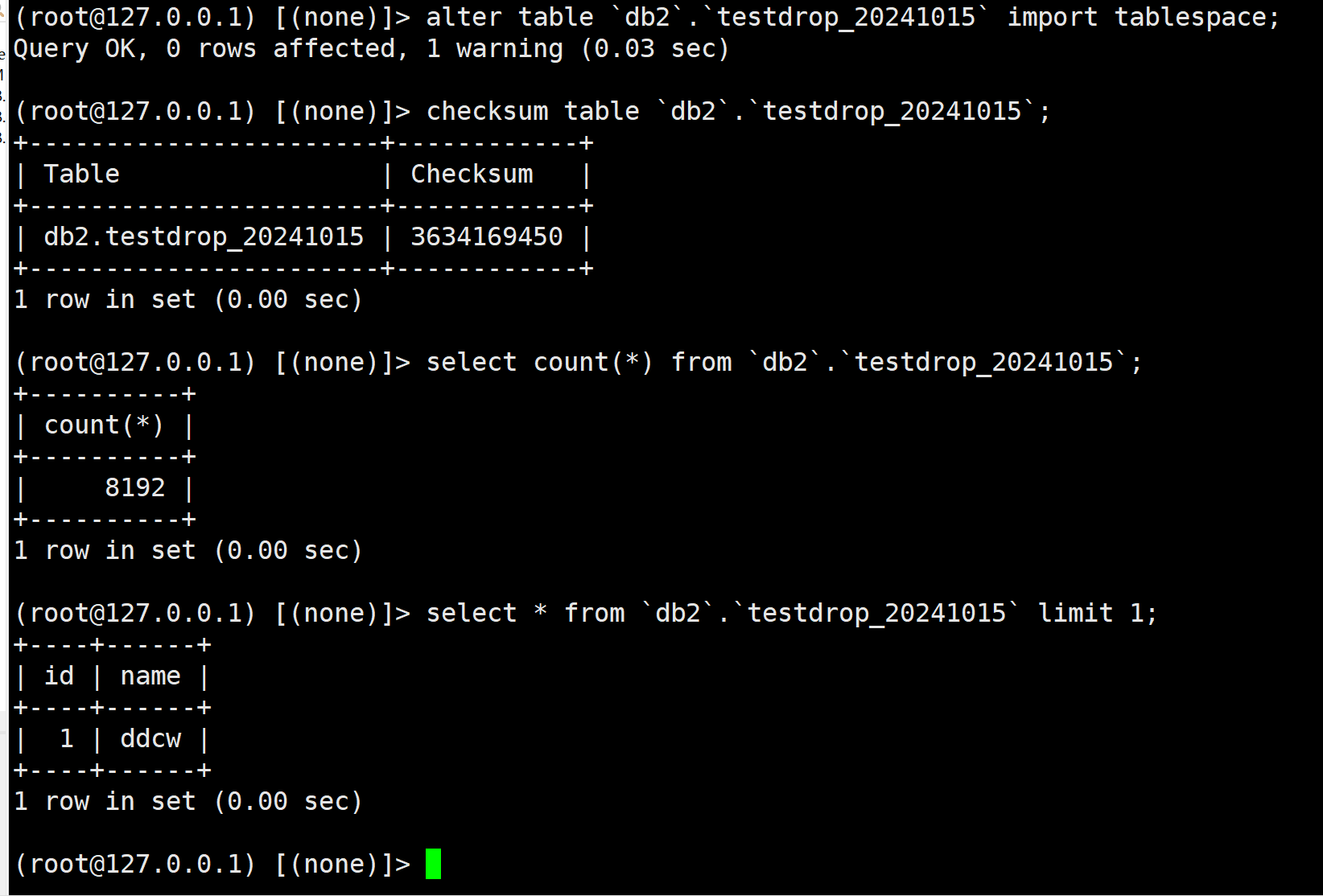
看来我们成功恢复了drop的表

总结
- 虽然我们已经验证了可以从文件系统恢复drop的表, 但还是要做好备份.
- 我们目前只支持简单的情况,比如只支持v5, extent之类的.
- 后面有空了再完善吧, 毕竟这个功能是给ibd2sql加的.
- 官方文档写得非常滴细.
- 数据误删之后就不要再写入数据了. (inode可能会被重复使用的)
参考:
https://cdn.kernel.org/pub/linux/utils/fs/xfs/docs/xfs_filesystem_structure.pdf
https://github.com/torvalds/linux/blob/master/fs/xfs
https://github.com/ddcw/ibd2sql
附源码
python3编写的, 没做详细的验证
#!/usr/bin/env python3
# write by ddcw @https://github.com/ddcw
# xfs文件系统数据误删恢复工具. 目前只恢复ibd文件 (加密和压缩的也先不管了)
# 用法: python xfs_recovery.py /dev/mapper/centos-ddcw-root /tmp
# 参考: https://cdn.kernel.org/pub/linux/utils/fs/xfs/docs/xfs_filesystem_structure.pdf
# xfs文件系统结构
_xfs_struct = """
xfs由一堆ag(allocate group)组成.
ag由如下组成
1. A super block describing overall filesystem info
2. Free space management
3. Inode allocation and tracking
4. Reverse block-mapping index (optional)
5. Data block reference count index (optional)
sb(super block) 位于每个ag的第一个块的第一个扇区. (第一个ag里面的sb是主要的, 其它的ag里面的都是备份的)
ag中第一个块 第二个扇区: AGF (AG free block)
第三个扇区: AGI (AG inode block, not Artificial General Intelligence)
第四个扇区: AGFL (AG internal free list)
AGI记录了btr+的root node.
root node记录了各文件/目录的inode信息.
xfs_db /dev/sdb
xfs_db> sb
xfs_db> p
xfs_db> agi 0
xfs_db> print root
xfs_db> addr root
xfs_db> p
......
uuid = 62099217-cc33-4a90-ad83-bb923ff56bd8
owner = 0
crc = 0x75da423c (correct)
recs[1] = [startino,freecount,free] 1:[64,59,0xffffffffffffffc8]
这表示, inode从64开始, 还剩59个, 也就是64-69被使用了. 每个inode占512字节. 一个block能放8(inopblock)个inode
所以inode=69的位置是 69//8*4096 + 69%8*512 # 通常是按照块读.
xfs_db> inode 69
xfs_db> p
......
v3.uuid = 62099217-cc33-4a90-ad83-bb923ff56bd8
u3.bmx[0] = [startoff,startblock,blockcount,extentflag] 0:[0,17,1,0]
表示这个文件始于17块, 共1个块. 无额外信息
f = open('/dev/sdb','rb')
f.seek(17*4096,0)
data = f.read(1*4096) # 这就是该文件的信息了. 文件名是记录在目录文件中的. xfs_db> inode 64 p
"""
import struct,datetime
import sys,os
import subprocess
import zlib
import json
class localcmd(object):
def __init__(self,*args,**kwargs):
self.timeout = kwargs['timeout'] if 'timeout' in kwargs else 1200
def command(self,cmd)->tuple:
with subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) as f:
try:
return f.wait(self.timeout),str(f.stdout.read().rstrip(),encoding="utf-8"),str(f.stderr.read().rstrip(),encoding="utf-8")
except Exception as e:
f.kill()
return -1,e,str(f.stderr.read().rstrip(),encoding="utf-8")
# 方便读数据的...
class data_buffer(object):
def __init__(self,bdata):
self.bdata = bdata
self.offset = 0
def read(self,n):
data = self.bdata[self.offset:self.offset+n]
self.offset += n
return data
def read_int(self,n):
if n == 1:
return self.read_int1()
elif n == 2:
return self.read_int2()
elif n == 4:
return self.read_int4()
elif n == 8:
return self.read_int8()
def read_int1(self): # 均为大端字节序
return struct.unpack('>B',self.read(1))[0]
def read_int2(self):
return struct.unpack('>H',self.read(2))[0]
def read_int4(self):
return struct.unpack('>L',self.read(4))[0]
def read_int8(self):
return struct.unpack('>Q',self.read(8))[0]
# https://github.com/torvalds/linux/blob/master/fs/xfs/libxfs/xfs_format.h
# xfs_drfsbno_t = 8
# xfs_drtbno_t = 8
# xfs_ino_t = 8 # inode number
# xfs_agblock_t = 4
XFS_SB_FEAT_INCOMPAT_BIGTIME = (1 << 3)
class SB(object):
def __init__(self,bdata):
self.data = data_buffer(bdata)
self.magic = self.data.read(4)
if self.magic != b'XFSB':
return "this is not XFS SB"
self.blocksize = self.data.read_int(4) # 每个block的大小, 通常为4096
self.dblocks = self.data.read_int(8) # 总的block数量.
self.rblocks = self.data.read_int(8)
self.rextents = self.data.read_int(8)
self.uuid = self.data.read(16).hex()
self.logstart = self.data.read_int(8)
self.rootino = self.data.read_int(8)
self.rbmino = self.data.read_int(8)
self.rsumino = self.data.read_int(8)
self.rextsize = self.data.read_int(4)
self.agblocks = self.data.read_int(4)
self.agcount = self.data.read_int(4)
self.rbmblocks = self.data.read_int(4)
self.logblocks = self.data.read_int(4)
self.versionnum = self.data.read_int(2) # bitmap, XFS_SB_VERSION_xxxx
self.sectsize = self.data.read_int(2)
self.inodesize = self.data.read_int(2) # inode大小, 512
self.inopblock = self.data.read_int(2) # 每个块多少个inode 8
self.fname = self.data.read(12)
self.blocklog = self.data.read_int(1)
self.sectlog = self.data.read_int(1)
self.inodelog = self.data.read_int(1)
self.inopblog = self.data.read_int(1)
self.agblklog = self.data.read_int(1)
self.rextslog = self.data.read_int(1)
self.inprogress = self.data.read_int(1)
self.imax_pct = self.data.read_int(1)
self.icount = self.data.read_int(8)
self.ifree = self.data.read_int(8)
self.fdblocks = self.data.read_int(8)
self.frextents = self.data.read_int(8)
XFS_SB_VERSION_QUOTABIT = 0x0040
if XFS_SB_VERSION_QUOTABIT & self.versionnum:
self.uquotino = self.data.read_int(8)
self.gquotino = self.data.read_int(8)
else:
self.uquotino = None
self.gquotino = None
self.qflags = self.data.read_int(2)
self.flags = self.data.read_int(1)
self.shared_vn = self.data.read_int(1)
self.inoalignmt = self.data.read_int(4)
self.unit = self.data.read_int(4)
self.width = self.data.read_int(4)
self.dirblklog = self.data.read_int(1)
self.logsectlog = self.data.read_int(1)
self.logsectsize = self.data.read_int(2)
self.logsunit = self.data.read_int(4)
self.features2 = self.data.read_int(4)
self.bad_features2 = self.data.read_int(4)
# ..... 懒得写了, 但features_incompat中有XFS_SB_FEAT_INCOMPAT_BIGTIME....
self.data.offset = 216
self.features_incompat = self.data.read_int(4)
def __str__(self,):
pass
class AGI(object):
def __init__(self,bdata):
self.data = data_buffer(bdata)
self.magic = self.data.read(4)
self.versionnum = self.data.read_int(4)
self.seqno = self.data.read_int(4)
self.length = self.data.read_int(4)
self.count = self.data.read_int(4)
self.root = self.data.read_int(4) # 其实就要个这玩意...
self.level = self.data.read_int(4)
self.freecount = self.data.read_int(4)
self.newino = self.data.read_int(4)
self.dirino = self.data.read_int(4)
self.unlinked = self.data.read_int(4)
# version 判断, 这里就略了..
self.uuid = self.data.read(16).hex()
self.crc = self.data.read_int(4)
self.pad32 = self.data.read_int(4)
self.lsn = self.data.read_int(8)
def get_instance_attr(aa):
return {attr: getattr(aa, attr) for attr in dir(aa) if not callable(getattr(aa, attr)) and not attr.startswith("__") and attr != 'data'}
class parse_inode(object):
def __init__(self,data):
if data[:2] != b'IN':
return
self.di_magic,self.di_mode,self.di_version,self.di_format,self.di_onlink,self.di_uid,self.di_gid,self.di_nlink,self.di_projid,self.di_projid_hi = struct.unpack('>HHBBHLLLHH',data[:24])
# di_mode (0o)
# 0400000 目录
# 0100000 文件
# 0200000 字符设备
# 0600000 块设备
# 0120000 链接
# 0010000 fifo
# if (self.di_mode & 0o0100000) == 0 and self.di_mode!=0:
# print(f'AG:{ag} INODE:{inode+i} 非文件, 跳过.',oct(di_mode))
# return
self.di_atime = struct.unpack('>LL',data[32:40])
self.di_mtime = struct.unpack('>LL',data[40:48])
self.di_ctime = struct.unpack('>LL',data[48:56])
self.di_size,self.di_nblocks,self.di_extsize,self.di_nextents,self.di_anextents = struct.unpack('>QQLLH',data[56:82])
self.di_forkoff,self.di_aformat,self.di_dmevmask,self.di_dmstate,self.di_flags,self.di_gen = struct.unpack('>BBLHHL',data[82:96])
self.di_next_unlinked,self.di_crc,self.di_changecount,self.di_lsn,self.di_flags2,self.di_cowextsize = struct.unpack('>LLQQQL',data[96:132])
self.di_pad2 = data[132:144]
self.di_crtime = struct.unpack('>LL',data[144:152])
self.di_ino = struct.unpack('>Q',data[152:160])[0]
self.uuid_t = data[160:176].hex()
self.di_mode_oct = oct(self.di_mode)
self.extent = []
self.extent_size = 0
offset = 176
# 解析extent
_ = """/*
* Bmap btree record and extent descriptor.
* l0:63 is an extent flag (value 1 indicates non-normal).
* l0:9-62 are startoff.
* l0:0-8 and l1:21-63 are startblock.
* l1:0-20 are blockcount.
*/
#define BMBT_EXNTFLAG_BITLEN 1
#define BMBT_STARTOFF_BITLEN 54
#define BMBT_STARTBLOCK_BITLEN 52
#define BMBT_BLOCKCOUNT_BITLEN 21
flag: 127
logical file block offset : 73-126
absolute block number: 21-72
# of blocks : 0-20
"""
#for x in range(self.di_nextents): # 被删除之后,di_nextents就是0了.
for x in range(21):
ebtr_1,ebtr_2 = struct.unpack('>QQ',data[offset:offset+16])
offset += 16
ebtr = (ebtr_1<<64) + ebtr_2
extentflag = ebtr>>127
#startoff = (ebtr>>(127-54))&(2**55-1) # 逻辑位置, 和读文件内容顺序有关的
startoff = (ebtr>>73)&(2**54-1) # 逻辑位置, 和读文件内容顺序有关的
startblock = (ebtr>>21)&(2**52-1)
blockcount = ebtr&(2**21-1)
if blockcount > 0:
self.extent_size += blockcount*4096
self.extent.append([startoff,startblock,blockcount,extentflag,ebtr])
self.extent.sort() # 排个序
class xfs(object):
def __init__(self,filename):
self.filename = filename # device name
self.f = open(filename,'rb')
print('扫描磁盘:',filename)
def __close(self,):
self.f.close()
def read(self,n=0):
self.f.seek(4096*n,0)
return self.f.read(4096)
def init(self,):
#解析SB
self.sb = SB(self.read())
def de_inode(self,inode): # 解析inode,得到其对应的ag信息
"""
/*
* Inode number format:
* low inopblog bits - offset in block (一个block, 8个inode, 所以4bit就够了)
* next agblklog bits - block number in ag
* next agno_log bits - ag number
* high agno_log-agblklog-inopblog bits - 0
*/
| 4 bit | 22 bit | 4 bit |
INODE = | AGNO | BLOCK NO | offset in block |
| agno_log | agblklog | inopblog |
"""
inopblog = self.sb.inopblog
agblklog = self.sb.agblklog # 位于ag的哪个块. 记录了的. 或者 (self.sb.agblocks-1).bit_length()
agno_log = (self.sb.agcount).bit_length() # ag需要的bit数量
offset_in_block = inode&(2**(inopblog)-1) # inode在block中的位置
block_no = ((inode>>inopblog)&(2**(agblklog)-1)) # 在ag中的block_id
ag_no = ((inode>>(inopblog+agblklog))&(2**agno_log-1)) # 在哪个ag中
offset = ((ag_no*self.sb.agblocks)+block_no) * self.sb.blocksize + offset_in_block*self.sb.inodesize
return (ag_no,block_no,offset_in_block,offset)
def en_inode(self,inode,ag,block,oblock):
# 把inode打包, 其实没必要, 因为inode里面记录的inode号的.....
pass
def inode_block(self,ag,inode_block):
data = self.read(inode_block)
magic = data[:4]
if magic != b'IAB3':
print('只支持v5, skip AG:',ag)
return
bb_level,bb_numrecs,bb_leftsib,bb_rightsib = struct.unpack('>HHLL',data[4:16])
bb_blkno,bb_lsn = struct.unpack('>QQ',data[16:32])
bb_uuid = data[32:48].hex()
bb_owner = struct.unpack('>L',data[48:52])[0]
bb_crc = struct.unpack('<L',data[52:56])[0] #非要来个小端.
if bb_level > 0: # node
for rec in range(bb_numrecs):
_inode_block = struct.unpack('>I', data[56:56+4])[0]
self.inode_block(ag,_inode_block)
else: # leaf
for rec in range(bb_numrecs):
startino,freecount,free = struct.unpack('>LLQ',data[56:72])
# startino inode起始号
# freecount 还剩多少, 不一定是连续的. inode能被重复使用的
# free mask, 标记哪些inode被使用了. free&(1<<(inode-startino)) > 0 表示该inode被使用了
# 每次都是按照1个trunk来分配inode的. 所以inode是放在8个连续块的
for i in range(64): # 和free掩码与为0, 即表示该inode存在, 否则表示该inode为空
if free&(1<<i) == 1:
continue
inode = startino + i
iblock_id = inode // self.sb.inopblock
iblock_offset = inode % self.sb.inopblock
self.leaf_block(ag,iblock_id,iblock_offset)
def leaf_block(self,ag,block_id,iblock_offset):
offset = self.sb.agblocks*ag + block_id
data = self.read(offset)
for i in range(8):
if i != iblock_offset:
continue
offset = 512*i
if data[offset:offset+2] != b'IN': #不是Inode
break
inode = parse_inode(data[offset:offset+512])
#if inode.di_mode == 0: # 未使用的, 也可能是被删除了(我们要的就是被删除的)
# continue
instance_attributes = get_instance_attr(inode)
if inode.di_mode > 0:
continue
#if (inode.di_mode & 0o0100000) == 0 and inode.di_mode!=0:
# print(f'AG:{ag} INODE:{inode.di_ino} 非文件, 跳过. {oct(inode.di_mode)}',instance_attributes)
# continue
# 被删除的文件di_mode,di_size之类的都是0, 但extent信息还保留的, 我们就去看extent了
#if inode.di_size > 0 and inode.di_size%16384==0 and inode.di_format == 2:
#if inode.di_size == 0 and inode.extent_size>0:
# print('被删文件:',inode.di_ino,instance_attributes)
if inode.extent_size%16384==0 and inode.extent_size>0 and inode.di_format == 2:
ibd_head = b''
_END_FOR_IBD = False
for et in inode.extent:
start_block = et[1]
start_count = et[2]
for _block_id in range(et[1],et[1]+et[2],1):
ibd_head += self.read(_block_id)
if len(ibd_head) == 65536:
_END_FOR_IBD = True
break
if _END_FOR_IBD:
break
sdi = ibd_head[-16384:]
if sdi[24:26] != b'E\xbd': # SDI PAGE
continue
tablename = get_tablename_from_ibd(sdi)
if tablename != '':
#print(f"INODE:{inode.di_ino} SIZE:{inode.extent_size} TABLE_NAME:{tablename} {instance_attributes}")
print(f"INODE:{inode.di_ino} SIZE:{inode.extent_size} TABLE_NAME:{tablename}")
# 文件就btree(大文件和碎片?)和extent
if inode.di_format == 4: # uuid
pass
elif inode.di_format == 3: # btree
pass
elif inode.di_format == 2: # extent
pass
elif inode.di_format == 1: # local, 文件夹, 我们跳过了
pass
elif inode.di_format == 0: # dev
pass
def list(self,):
"""列出所有被标记为删除的文件"""
for ag in range(self.sb.agcount): # 遍历所有ag
agi_data = self.read(ag*self.sb.agblocks)
inode = AGI(agi_data[1024:1024+512])
print(f"扫描:AG={ag} root={inode.root} size:{self.sb.agblocks*4096/1024/1024} MB")
self.inode_block(ag,inode.root)
#break
def list_inode(self,inodeno,filename):
"""根据Inode恢复数据"""
ag,block_no,offset_in_block,offset_1 = self.de_inode(inodeno)
print(ag,block_no,offset_in_block,offset_1)
offset = self.sb.agblocks*ag + block_no
data = self.read(offset)
for i in range(8):
if i != offset_in_block:
continue
#print(i)
offset = 512*i
inode = parse_inode(data[offset:offset+512])
if (inode.di_mode & 0o0100000) == 0 and inode.di_mode != 0:
print(f'INODE: {inode.di_ino} 不是文件啊 (di_mode:{inode.di_mode_oct})')
continue
instance_attributes = get_instance_attr(inode)
#print(instance_attributes)
with open(filename,'wb') as f:
for x in inode.extent:
start_offset = x[1]
start_count = x[2]
#print(start_offset,start_count)
if start_count == 0:
continue
#print(start_offset,start_count)
for y in range(start_count):
_tdata = self.read(start_offset+y)
#print(len(self.read(start_offset+y)))
f.write(_tdata)
def get_tablename_from_ibd(bdata):
"""解析sdi page返回表名字 schema.table 这里就不考虑general tablespace之类的情况了"""
if len(bdata) != 16384:
return ''
offset = struct.unpack('>h',bdata[97:99])[0] + 99
dunzip_len,dzip_len = struct.unpack('>LL',bdata[offset+33-8:offset+33])
unzbdata = zlib.decompress(bdata[offset+33:offset+33+dzip_len])
dic_info = json.loads(unzbdata.decode())
#return(dic_info['dd_object']['schema_ref'])
return f"{dic_info['dd_object']['schema_ref']}.{dic_info['dd_object']['name']}"
argv = sys.argv
if len(argv) == 1 or len(argv) > 4 or len(argv) == 3:
print('USAGE: python3 ',argv[0],' devicename [inode] [filename]')
sys.exit(1)
else:
devicename = argv[1]
if not os.path.exists(devicename):
print(devicename,' 不存在!')
sys.exit(1)
#cmd = localcmd()
#device_name = cmd.command("df -hT " + os.path.dirname(recover_filename) + " | tail -1 | awk '{print $1}'")
if len(argv) == 2: # 扫描磁盘
aa = xfs(devicename)
aa.init()
aa.list()
elif len(argv) == 4:
inodeno = int(argv[2])
filename = argv[3]
if os.path.exists(filename):
print(filename,' 文件存在, 请换个名字')
sys.exit(2)
aa = xfs(devicename)
aa.init()
aa.list_inode(inodeno,filename)
