




1. 聚合函数介绍
聚合(或聚集、分组)函数,是对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值。
聚合函数类型:
AVG():求平均值 SUM():求和 MAX():求最大值 MIN():求最小值 COUNT():统计记录总数
聚合函数不能嵌套调用,比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
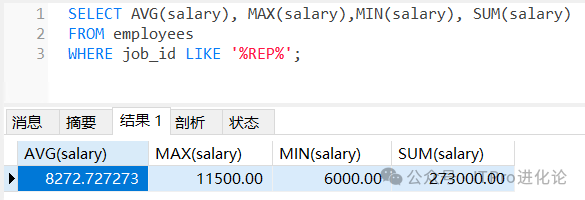
示例:查符合条件的工作的平均工资,最高工资,最低工资,工资总和
SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';
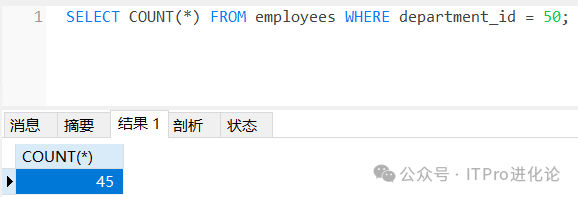
COUNT(*)返回表中记录总数,适用于任意数据类型。
-- 查询employees表中departmen_id为50的记录条数
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;
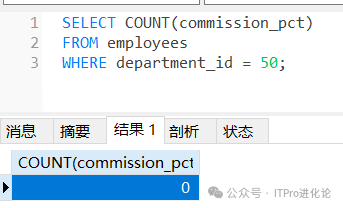
COUNT(expr) 返回expr不为空的记录总数。
SELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 50;
count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2. GROUP BY 语句
GROUP BY 语句根据一个或多个列对结果集进行分组,在分组的列上可以使用 COUNT, SUM, AVG等函数。
SELECT column1, aggregate_function(column2)
FROM table_name
WHERE condition
GROUP BY column1;
column1
:指定分组的列。aggregate_function(column2)
:对分组后的每个组执行的聚合函数。table_name
:要查询的表名。condition
:可选,用于筛选结果的条件。
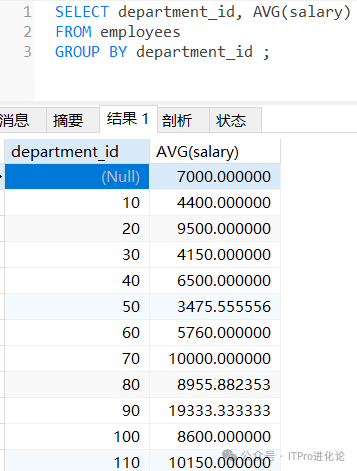
在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中。
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id ;
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中;
SELECT AVG(salary)
FROM employees
GROUP BY department_id;
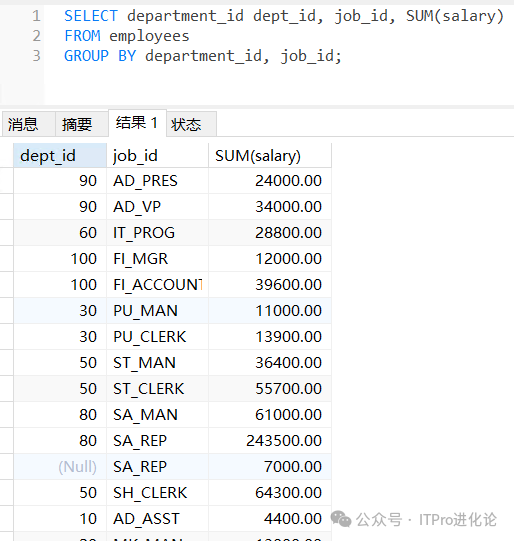
使用多个列分组
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id;
3. HAVING子句
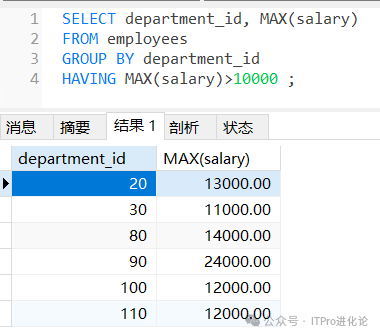
HAVING子句通常与GROUP BY子句一起使用,以根据指定的条件过滤分组,如果省略GROUP BY子句,则HAVING子句的行为与WHERE子句类似。
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
不能在 WHERE 子句中使用聚合函数。
WHERE和HAVING的对比:
WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。 如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。

4. SELECT的执行过程
4.1. 查询的结构
-- 方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
-- 方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
其中:
from:从哪些表中筛选 on:关联多表查询时,去除笛卡尔积 where:从表中筛选的条件 group by:分组依据 having:在统计结果中再次筛选 order by:排序 limit:分页
4.2. SELECT执行顺序
SELECT 查询时的两个顺序:
查询语句的关键字的顺序是不能颠倒
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同)
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
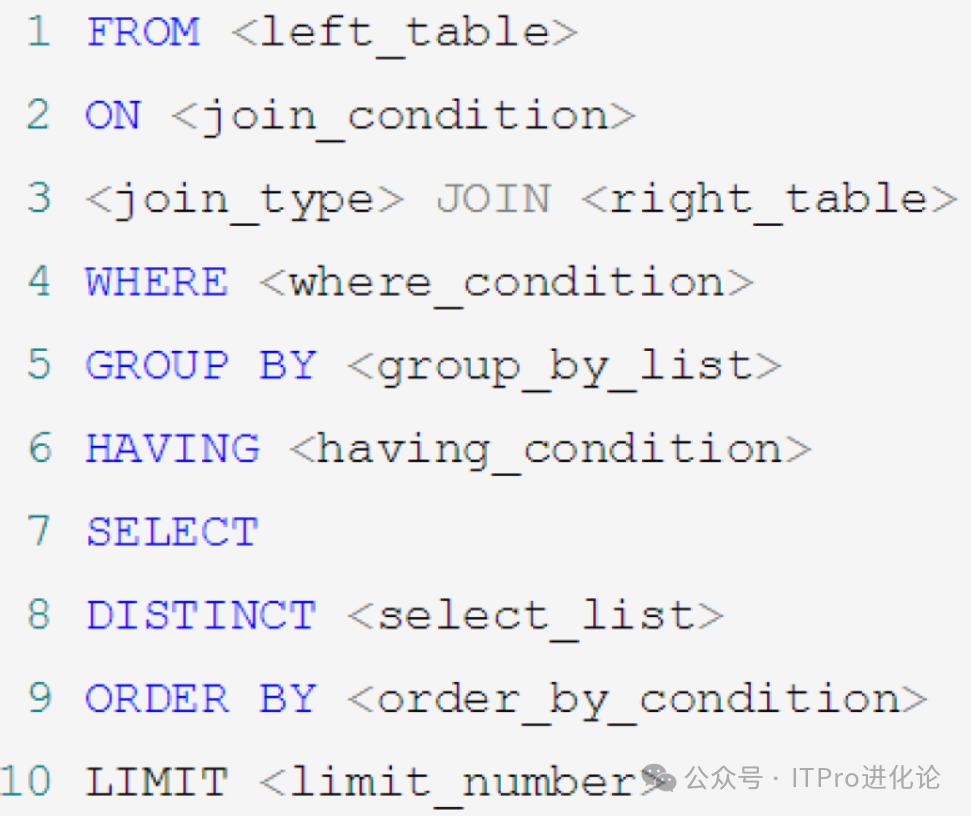
比如写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num -- 顺序 5
FROM player JOIN team ON player.team_id = team.team_id -- 顺序 1
WHERE height > 1.80 -- 顺序 2
GROUP BY player.team_id -- 顺序 3
HAVING num > 2 -- 顺序 4
ORDER BY num DESC -- 顺序 6
LIMIT 2 -- 顺序 7
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。
4.3. SQL 的执行原理
SELECT 是先执行 FROM 这一步的,在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
首先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1; 通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2; 添加外部行,如果使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。
当拿到了查询数据表的原始数据,也就是最终的虚拟表 vt1 ,就可以在此基础上再进行 WHERE 阶段,在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表 vt2 , 然后进入第三步和第四步,也就是 GROUP 和 HAVING 阶段,在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表 vt3 和 vt4 ;
当完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT 和 DISTINCT阶段;
首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表vt5-1 和 vt5-2;
当提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY 阶段,得到虚拟表 vt6 ;
最后在 vt6 的基础上,取出指定行的记录,也就是 LIMIT 阶段,得到最终的结果,对应的是虚拟表vt7 ;
当然在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略;
同时因为 SQL 是一门类似英语的结构化查询语言,所以在写 SELECT 语句的时候,还要注意相应的关键字顺序。
