




一、前言:
大家好,本篇我们来聊聊HaloDB的分区表。
广告时间:
HaloDB业内首次创造性的提出插件式内核架构设计,通过配置的方式,适配不同的应用场景,打造全场景覆盖的能力,满足企业大部分数据存储处理需求。从而消除数据孤岛,降低系统复杂度,保护企业既有投资,降低企业成本。同时支持x86、arm等异构平台之间的混合部署。
如果有对我们的产品感兴趣的朋友可以通过主页的联系方式与我取得联系,获取license来安装体验,目前已经开通HaloDB吐槽群,欢迎来喷。
二、什么是分区表:
对于很多DBA朋友来说,分区表其实并不陌生,是一种将一个大表在物理上分割成几个部分的技术,每个小块通常对应一个子表或分区。这种分割可以通过多种方式进行,包括范围分区、列表分区和哈希分区等。
那这里有一个问题,就是为什么要去做这个分区表,分区表能给我带来什么收益。
分区表的好处包括:
- 提高查询性能。当查询条件能够精确匹配到特定分区时,数据库可以仅扫描该分区,而不是整个大表,这大大减少了数据扫描的量,特别是当处理的数据量非常大时。
- 便于数据管理。例如,我们可以通过删除不再需要的分区来简化老旧数据的清理工作,减少磁盘空间的碎片,降低系统的复杂度。
- 优化存储和备份。可以将不经常访问的数据移动到成本较低的存储介质上,或者通过只备份变化的分区来减少备份的频率和大小。
- 简化数据库维护。通过增加或删除分区来处理批量装载和删除操作,而不是对整个表进行操作,这样可以避免全表扫描的开销。
凡是都有两面,相比分区表好的一面来说,分区表带来的问题就是对数据库管理者和应用开发者提出更高的技术要求,不合理的表结构设计会对应用带来更大的负面影响
三、分区表的类型:
通常情况下,HaloDB中的分区表最常用的分别是范围分区,列表分区和哈希分区。
1. 范围分区
范围分区的分区键可以是数值或时间,并根据其值的范围进行分区。
示例1:
步骤 1:创建分区表
CREATE TABLE sales ( sale_id INT, sale_date DATE NOT NULL, amount NUMERIC(10, 2), product_id INT, PRIMARY KEY (sale_id, sale_date) ) PARTITION BY RANGE (sale_date);
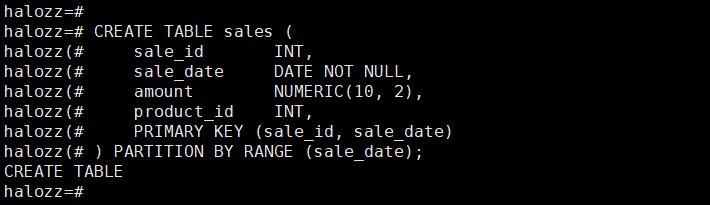
步骤 2:创建第一个分区,例如包含2023年第一季度的数据
CREATE TABLE sales_q1_2023 PARTITION OF sales FOR VALUES FROM ('2023-01-01') TO ('2023-04-01');

步骤 3:创建第二个分区,例如包含2023年第二季度的数据
CREATE TABLE sales_q2_2023 PARTITION OF sales FOR VALUES FROM ('2023-04-01') TO ('2023-07-01');

步骤 4:创建第三个分区,例如包含2023年第三季度的数据
CREATE TABLE sales_q3_2023 PARTITION OF sales FOR VALUES FROM ('2023-07-01') TO ('2023-10-01');

步骤 5:创建第四个分区,例如包含2023年第四季度的数据
CREATE TABLE sales_q4_2023 PARTITION OF sales FOR VALUES FROM ('2023-10-01') TO ('2023-12-01');

步骤 6:插入测试数据
INSERT INTO sales (sale_id, sale_date, amount, product_id) VALUES
(1, '2023-01-15', 100.50, 101),
(2, '2023-02-20', 150.75, 102),
(3, '2023-03-31', 200.00, 103),
(4, '2023-04-15', 120.25, 101),
(5, '2023-05-20', 180.00, 102),
(6, '2023-06-30', 250.00, 103),
(7, '2023-07-15', 140.00, 101),
(8, '2023-08-20', 220.50, 102),
(9, '2023-09-30', 300.00, 103);
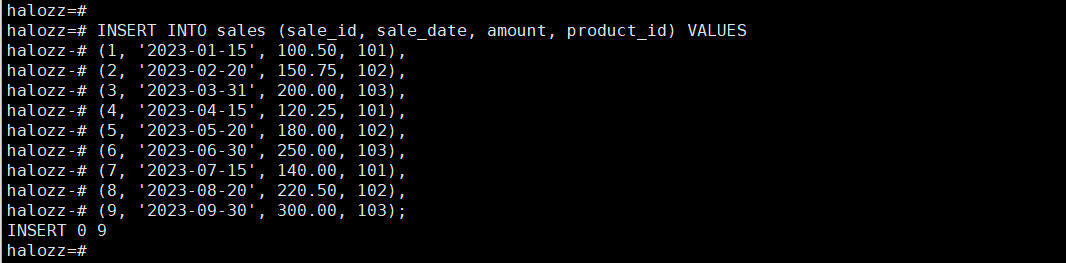
步骤 7:分别查询2023年第一、第二、第三、第四季度的销售数据
halozz=# select * from sales_q1_2023;
sale_id | sale_date | amount | product_id
---------+------------+--------+------------
1 | 2023-01-15 | 100.50 | 101
2 | 2023-02-20 | 150.75 | 102
3 | 2023-03-31 | 200.00 | 103
(3 rows)
halozz=# select * from sales_q2_2023;
sale_id | sale_date | amount | product_id
---------+------------+--------+------------
4 | 2023-04-15 | 120.25 | 101
5 | 2023-05-20 | 180.00 | 102
6 | 2023-06-30 | 250.00 | 103
(3 rows)
halozz=# select * from sales_q3_2023;
sale_id | sale_date | amount | product_id
---------+------------+--------+------------
7 | 2023-07-15 | 140.00 | 101
8 | 2023-08-20 | 220.50 | 102
9 | 2023-09-30 | 300.00 | 103
(3 rows)
halozz=# select * from sales_q4_2023;
sale_id | sale_date | amount | product_id
---------+-----------+--------+------------
(0 rows)
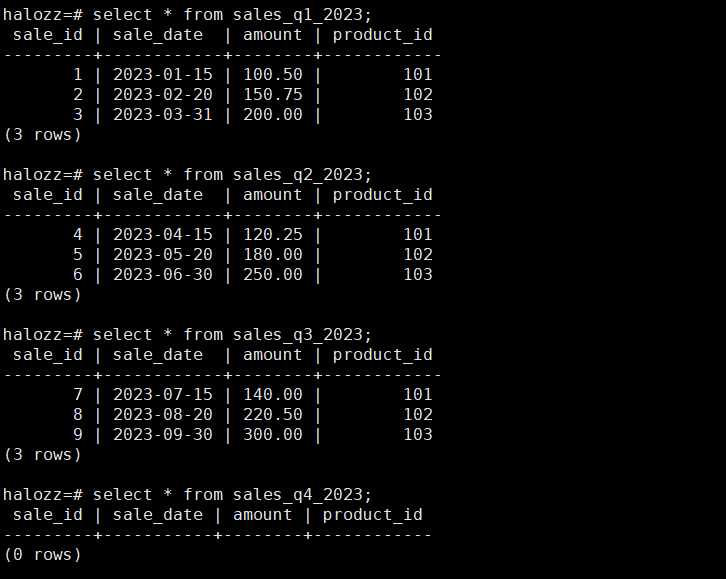
上面的数据并没有插入第四季度的数据,所以第四季度返回空值。
那分区表带来的怎样的收益,我们接下来一起来看下:
为了验证分区的实际效果,可以使用EXPLAIN语句来查看查询的执行计划:
halozz=# EXPLAIN SELECT * FROM sales WHERE sale_date >= '2023-01-01' AND sale_date < '2023-04-01';
QUERY PLAN
------------------------------------------------------------------------------------
Seq Scan on sales_q1_2023 sales (cost=0.00..31.75 rows=7 width=28)
Filter: ((sale_date >= '2023-01-01'::date) AND (sale_date < '2023-04-01'::date))
(2 rows)

由上图可见,当我们使用范围分区时,仅仅扫描了sales_q1_2023分区,这样做的好处显而易见。
示例2:
步骤 1: 创建主表
halozz=# CREATE TABLE range_partitioned_table (
halozz(# id INT NOT NULL,
halozz(# data TEXT,
halozz(# CONSTRAINT pk_range_partitioned_table PRIMARY KEY (id)
halozz(# ) PARTITION BY RANGE (id);
CREATE TABLE

步骤 2: 创建依据具体数值的分区表,本测试用例以1000为分界
halozz=#
halozz=# CREATE TABLE range_partitioned_table_p1 PARTITION OF range_partitioned_table
halozz-# FOR VALUES FROM (MINVALUE) TO (1000);
CREATE TABLE
halozz=#
halozz=# CREATE TABLE range_partitioned_table_p2 PARTITION OF range_partitioned_table
halozz-# FOR VALUES FROM (1000) TO (MAXVALUE);
CREATE TABLE
halozz=#


步骤 3: 向表中插入数据
halozz=# INSERT INTO range_partitioned_table (id, data) VALUES (500, 'Test data 1');
INSERT 0 1
halozz=# INSERT INTO range_partitioned_table (id, data) VALUES (1500, 'Test data 2');
INSERT 0 1

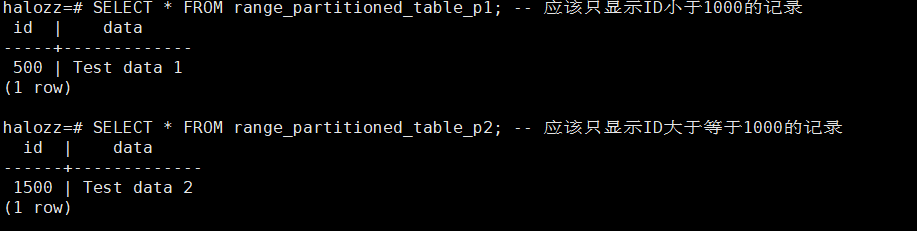
步骤 4:验证数据
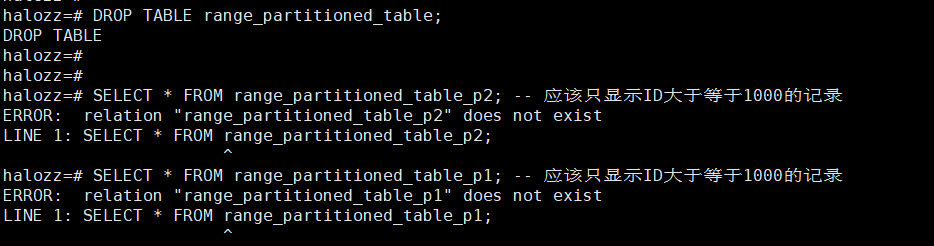
halozz=# SELECT * FROM range_partitioned_table_p1; -- 应该只显示ID小于1000的记录
id | data
-----+-------------
500 | Test data 1
(1 row)
halozz=# SELECT * FROM range_partitioned_table_p2; -- 应该只显示ID大于等于1000的记录
id | data
------+-------------
1500 | Test data 2
(1 row)
步骤 5: 删除分区表
DROP TABLE range_partitioned_table;
2. 列表分区
在HaloDB中,同样支持使用列表分区的测试用例来创建分区表,列表分区是一种将表按照列中的离散值进行分割的技术。这种分区方式适用于那些列的值是有限且离散的集合的情况。示例如下:
示例3:
步骤 1: 创建主表
首先,我们创建一个主表,它定义了分区键和分区策略。在这个例子中,我们将创建一个按文本字段列表分区的表。
CREATE TABLE list_partitioned_table ( country_code CHAR(2) NOT NULL, data TEXT, CONSTRAINT pk_list_partitioned_table PRIMARY KEY (country_code) ) PARTITION BY LIST (country_code);

步骤 2: 创建分区
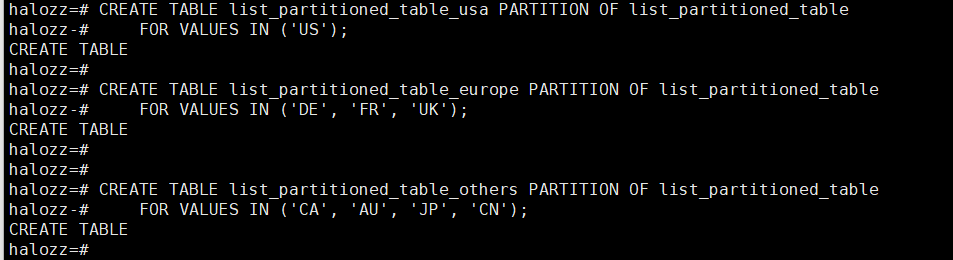
接下来,根据分区策略创建分区。在这个例子中,我们创建几个分区,每个分区对应一个或几个国家代码。
CREATE TABLE list_partitioned_table_usa PARTITION OF list_partitioned_table FOR VALUES IN ('US'); CREATE TABLE list_partitioned_table_europe PARTITION OF list_partitioned_table FOR VALUES IN ('DE', 'FR', 'UK'); CREATE TABLE list_partitioned_table_others PARTITION OF list_partitioned_table FOR VALUES IN ('CA', 'AU', 'JP', 'CN');
步骤 3: 插入测试数据
现在,我们可以向分区表中插入一些测试数据,以确保数据被正确地放入相应的分区中。
INSERT INTO list_partitioned_table (country_code, data) VALUES ('US', 'Test data USA'); INSERT INTO list_partitioned_table (country_code, data) VALUES ('DE', 'Test data Germany'); INSERT INTO list_partitioned_table (country_code, data) VALUES ('JP', 'Test data Japan');

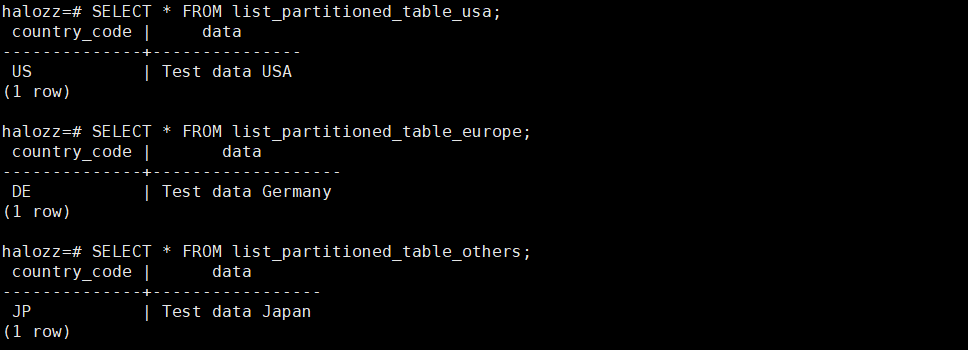
步骤 4: 验证数据
查询分区表以确保数据被正确地插入到相应的分区中。
SELECT * FROM list_partitioned_table_usa; -- 应该只显示国家代码为'US'的记录 SELECT * FROM list_partitioned_table_europe; -- 应该只显示国家代码为'DE', 'FR', 'UK'的记录 SELECT * FROM list_partitioned_table_others; -- 应该只显示其他国家代码的记录
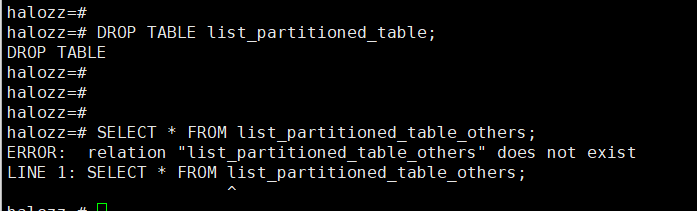
步骤 5: 清理环境
在测试完成后,你可能想删除整个分区表及其所有分区以清理测试环境。同样,你可以使用DROP TABLE语句删除主表,所有分区也会被自动删除。
DROP TABLE list_partitioned_table;
3. 哈希分区
在HaloDB中,哈希分区是一种将表按照某个列的值进行哈希运算,并将结果映射到不同分区的技术。哈希分区通过使用哈希函数将列的值转换为哈希值,然后根据这些哈希值将数据分布到不同的分区中。哈希分区的优点在于它可以平均分布数据,避免某个分区存储过多数据,从而提高查询效率。此外,哈希分区对于插入和查询操作都提供了较好的性能,因为哈希函数可以快速地计算出数据应该存储在哪个分区中,从而减少了查找和定位数据的时间。
示例4
首先,创建一个主表作为分区模板,并定义用于分区的列。这个主表通常不会存储实际数据,但它定义了分区表的结构和约束。
步骤1:创建主表
CREATE TABLE user_data (
user_id INT PRIMARY KEY,
username VARCHAR(50),
age INT,
created_at TIMESTAMP DEFAULT now()
) PARTITION BY HASH (user_id);

在这个例子中,user_data表将根据user_id列的值进行哈希分区。PARTITION BY HASH (user_id)语句指定了分区策略。
步骤2:创建分区表。
创建第一个分区表
CREATE TABLE user_data_p1 PARTITION OF user_data FOR VALUES WITH (MODULUS 4, REMAINDER 0);
创建第二个分区表
CREATE TABLE user_data_p2 PARTITION OF user_data FOR VALUES WITH (MODULUS 4, REMAINDER 1);
创建第三个分区表
CREATE TABLE user_data_p3 PARTITION OF user_data FOR VALUES WITH (MODULUS 4, REMAINDER 2);
创建第四个分区表
CREATE TABLE user_data_p4 PARTITION OF user_data FOR VALUES WITH (MODULUS 4, REMAINDER 3);

在这个例子中,创建了四个分区表,每个表使用MODULUS 4来指定哈希函数的模数,并使用REMAINDER来指定余数,以便将数据均匀分布到四个分区中。
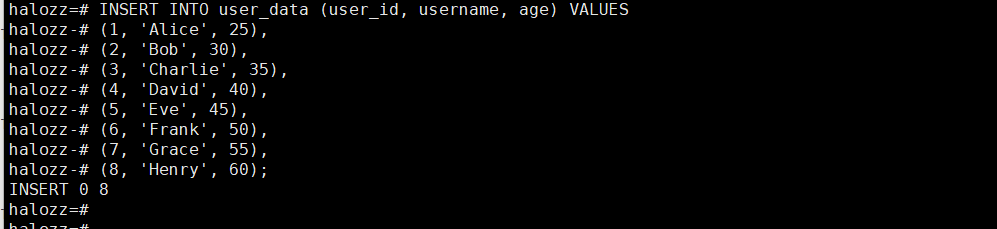
步骤3:插入数据
INSERT INTO user_data (user_id, username, age) VALUES
(1, 'Alice', 25),
(2, 'Bob', 30),
(3, 'Charlie', 35),
(4, 'David', 40),
(5, 'Eve', 45),
(6, 'Frank', 50),
(7, 'Grace', 55),
(8, 'Henry', 60);
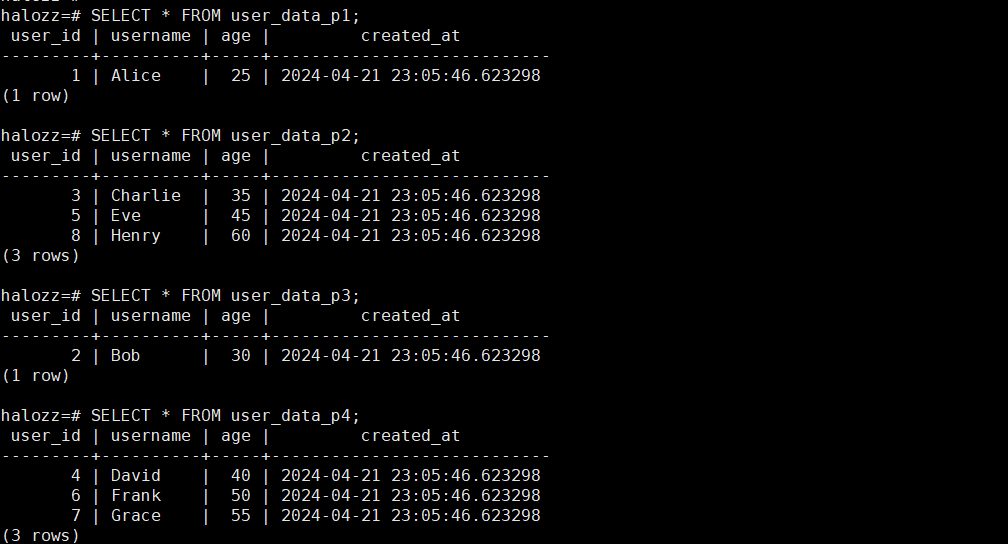
步骤4:查询每个分区表中的数据,以验证数据是否根据user_id的哈希值被正确分配。
查询第一个分区表
SELECT * FROM user_data_p1;
查询第二个分区表
SELECT * FROM user_data_p2;
查询第三个分区表
SELECT * FROM user_data_p3;
查询第四个分区表
SELECT * FROM user_data_p4;
最后
本篇介绍了在HaloDB中分区表的使用方法,各位朋友们如有感兴趣的知识,也欢迎私聊我沟通。
