




Exascale架构概述
当第一代 Exadata V1 首次亮相时,那些熟悉 Oracle RAC 和集群软件(GI)的小伙伴可能会发现,它在存储管理上与传统的 ASM 十分相似。我们依旧是从物理存储盘创建 Celldisk,并对其进行分区,生成供 ASM 使用的 Griddisk,随后在 Griddisk 上创建 ASM 的 Diskgroup。当然,Exadata 的 Diskgroup 与其他存储系统的最大区别在于,它支持 Exadata 独有的多种加速技术,包括智能扫描(Smart Scan)、智能闪存日志(Smart Flash Log)、智能闪存写回(Smart Flash Log Writeback)、xrmem 缓存、xrmem 日志(配备 pmem 硬件的存储)、以及基于 RDS 的高速 IO 访问协议,这些技术都绕过了操作系统的块设备 IO 层。
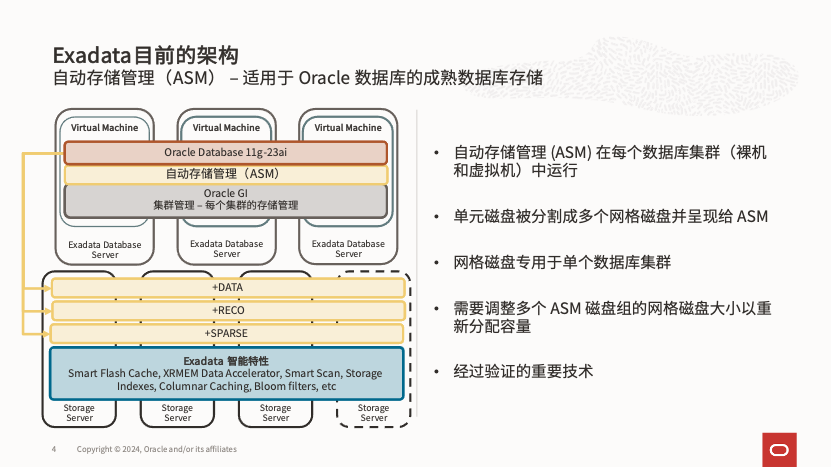
然而,随着云技术的不断普及,以及越来越多不同部门、不同类型、不同重要度的数据库被整合到 Exadata 部署中,即便是在客户自有机房环境下,新的 DevOps 开发运维模式也逐渐被广泛采用。在这种背景下,原有架构的灵活性不足的问题逐渐显现,具体体现在以下几个方面:
1) 需要强隔离的 RAC 集群在 Exadata 上采用 VM 部署时过程繁琐:每套 RAC 都需要创建统一大小的 Griddisk 和 Diskgroup。
2) 当 Exadata 硬件扩容了存储节点后,VM 集群的存储集群扩容过程变得相当复杂,特别是在多代硬件共存的情况下,复杂性进一步增加。
3) 原有 Exadata 创建 VM 集群时,系统盘依赖于计算节点的内置盘容量,限制了整体的灵活性。
4) 基于公有云服务的 Exadata DB Cloud Service 起步就需要独占硬件节点,虽然避免了不同租户之间的干扰,但最低配置为 2 个计算节点和 3 个存储节点,导致门槛较高。采用Exascale上的Exadata DB service服务,就可以在满足传统应用和生态工具访问数据库所在操作系统的需求同时,无需独占的硬件节点,降低起步成本。
5) 虽然 Exadata 过去提供了基于 Sparse DG 的快照功能,但该功能要求被快照的数据库始终处于只读状态,并且所有快照刷新都需要同步完成,难以满足实际 DevOps 流程的需求。
正是基于这些原有Exadata部署vm的限制,在ESS 24引入了全新的也是全球独特的Oracle数据库智能存储架构Exascale,其架构如下:
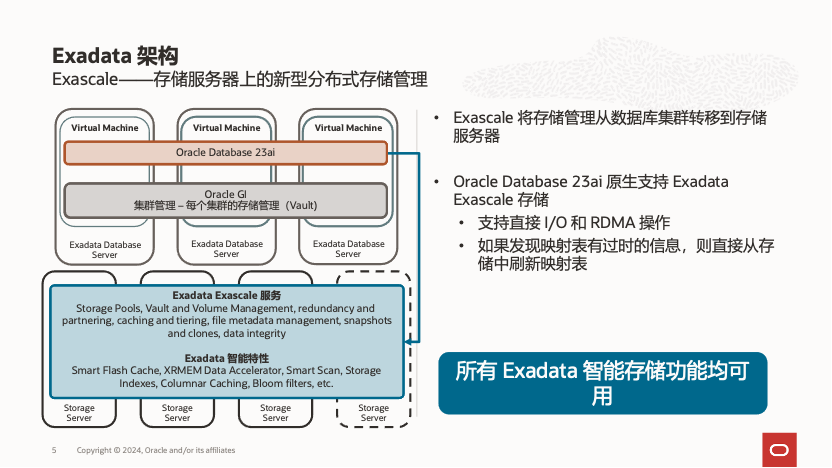
从这张图可以看出,相较于传统基于 ASM 和 Diskgroup 的存储管理,新架构将所有存储管理工作都转移到 Exadata 智能存储层,不再依赖 ASM 和 Diskgroup,而是通过一个专用于数据库的共享分布式文件系统直接提供给 RAC 使用,同时保留了所有 Exadata 智能软件针对数据库的加速特性。在 Exascale 架构中,存储层而非数据库节点直接管理庞大的存储资源池,为数据库提供服务。
如果大家熟悉 ASM 中的存储管理方式:当 ASM 使用 Griddisk 时,数据文件按照默认 4MB 大小的分配单元(AU)分布到不同的存储单元和物理硬盘,实现存储的条带化和镜像(SAME,Strip And Mirror Everything)。而在 Exascale 中,存储层直接采用 8MB 大小的区块(Extent)方式实现 SAME,无需 ASM 的参与,从而简化了存储管理。
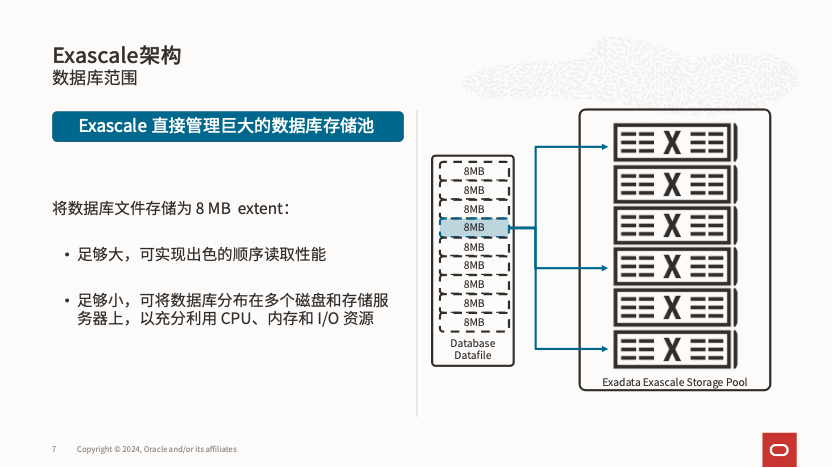
此外,在 Exascale 中,存储文件的冗余度可以根据文件模板进行选择:高冗余设置为 3 份,普通冗余为 2 份,不再需要在 Diskgroup 层进行配置(虽然 ASM 的 Flex Disk Group 也可以实现类似功能,但在实际应用中很少见)。这种方式提供了更高的灵活性。此外,Exascale 中的 Extent 到物理磁盘的映射采用一致性哈希算法,这样在扩展存储资源池时,映射表不会增大,从而减少了后台开销。
同样地,数据库也能获取该映射表,并根据映射关系直接将 IO 请求发送到存储节点的 Extent 上。通过这种松耦合的方式,映射表能够智能刷新,避免了分布式锁定问题,从而实现了超大规模存储的轻松扩展。该架构还提供了存储扩展灵活性,存储资源池与上层 RAC 独立,因此扩展存储变得非常简单,且支持同类型但不同物理大小的存储介质在一个资源池中灵活混用。扩展存储资源池后,如果需要增加上层 RAC 的使用空间,只需简单调整 Vault 大小即可。
在 Exascale 中,为数据库直接提供数据存储的对象是 Vault,可以将其视为 Exascale 提供的智能共享文件系统,命名以 “@” 开头。
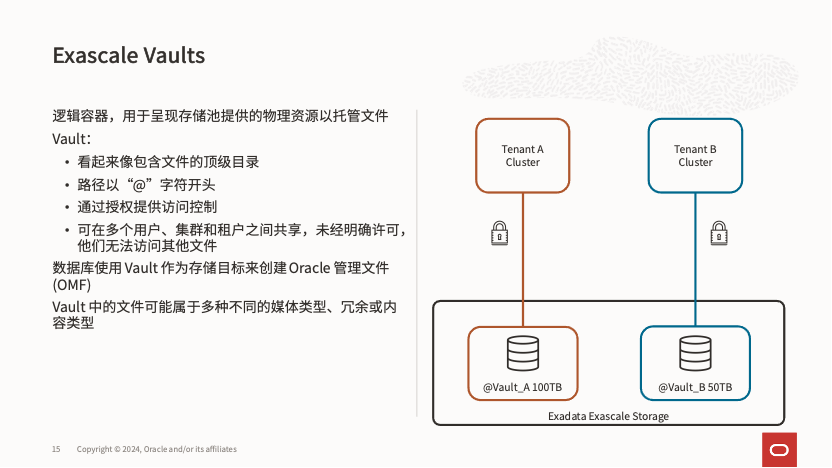
每个 Vault 不仅可以设置分配的大小,还能够调整性能参数,包括 IOPS、扫描带宽、Flashcache 大小、xrmem 缓存大小以及智能闪存日志(smart flashlog)大小,而且这些设置都可以在线动态调整,极大地提升了灵活性。想象一下,在原有架构中,为 VM 集群扩展 Diskgroup 是一个繁琐的过程,而 Exascale 架构完全简化了这个过程,实现了真正的存储与计算解耦。
除了为数据库提供存储,Exascale 还支持基于 RDMA 的块存储,满足普通块存储和文件系统的多种需求:
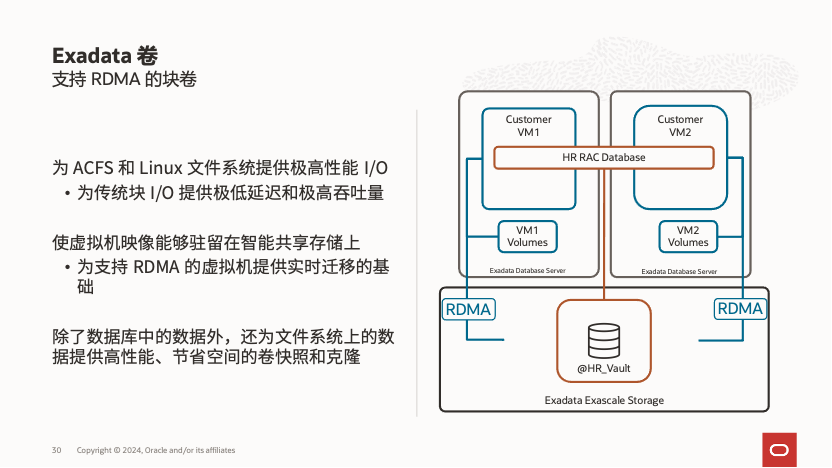
例如,VM 集群的操作系统盘可以使用 Exascale 块存储,从而便捷地实现虚拟机间的跨节点迁移,加速计划内维护过程(由于 RDMA + SR-IOV 技术,这一功能的实现极具挑战,但 Oracle 成功克服了技术难点,为客户提供了更便捷的体验)。此外,这也消除了对计算节点内置盘容量限制的顾虑。同样,使用这样的块存储可以直接创建 ACFS,为业务处理中需要高速共享文件系统的场景提供了一种简便且快速的解决方案。
Exascale数据库快照技术
在 Exascale 上,除了在架构上实现了计算与存储的彻底解耦外,另一项重大的功能创新是针对 DevOps 中 CI/CD 需求的灵活数据库快照技术,能够全面支持开发和测试。

在 Exascale 中,不再需要将被快照的数据库设为只读,通过一条或几条简单的命令就可以在同一 Vault 内创建生产库和容灾库的可读写快照克隆,为测试和开发提供便利。而且,各个克隆之间的刷新过程完全独立,彼此没有依赖关系。
借助 Exascale 的写重定向快照克隆技术,可以显著节省存储空间。仅需生产数据库存储容量的几分之一,甚至十几分之一,即可创建多个数据库克隆,大幅降低成本。为了更好地支持 CI/CD 流程,Exascale 还提供了基于 REST API 的接口,方便与 CI/CD 环境集成,实现更高效的自动化流程。
公有云上的Exascale服务
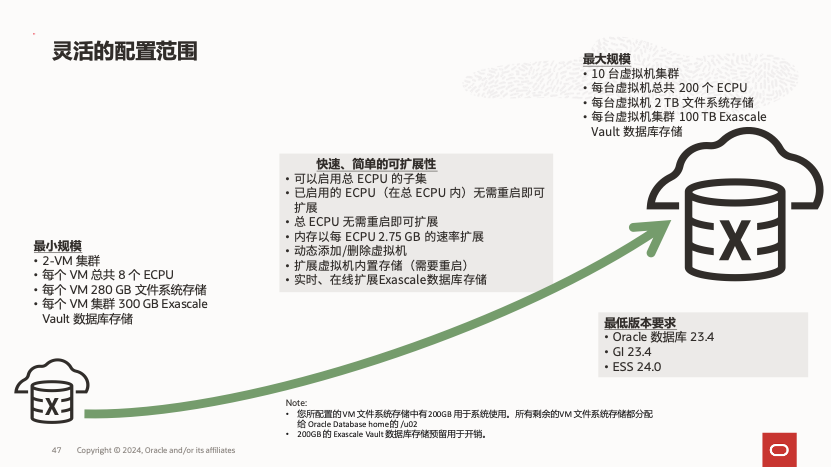
公有云上的 Exadata DB Service on Exascale 大大降低了在公有云中使用 Exadata 的门槛。用户不再需要独占计算和存储节点作为起步条件,最小配置仅需 2 个虚拟机组成的集群,每个虚拟机配备 8 个 ECPU、22 GB 内存和 300 GB 的 Exadata 数据库存储。计算能力可按 4 ECPU 的增量进行扩展,存储资源则以 GB 为单位灵活增加,为用户提供了更灵活的选择空间。

同时OCI公有云提供更多的云自动化功能,进一步降低了使用Exadata DB service的TCO和灵活性。
温馨提示:Exascale要求
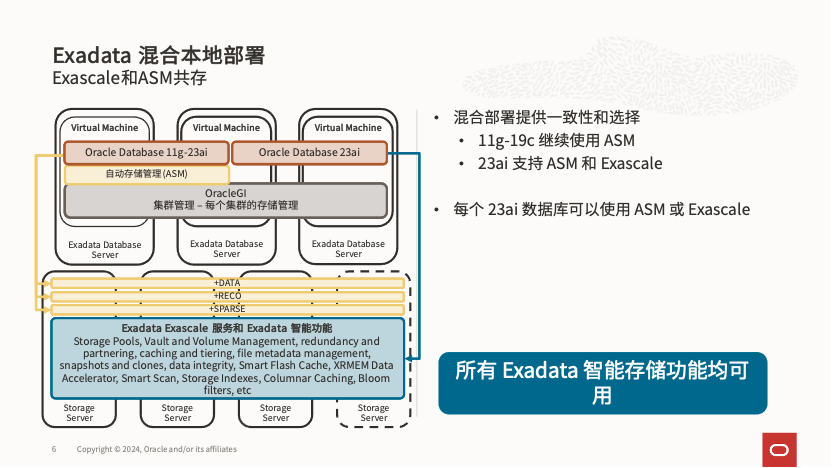
Exascale 架构的变革也要求 Oracle 数据库做出相应调整,因此 Exascale 仅支持 Oracle 数据库版本 23ai。对于本地部署的 Exadata,可以采用 Exascale 与传统 Exadata Griddisk/ASM 组合部署的方式,从而支持 19c 数据库版本。
总结
Exascale在保持Exadata针对Oracle数据库优化的性能之上,额外提供更好的灵活性,简化 Exadata 存储管理和分配,将存储管理从数据库集群转移到存储服务器;和数据库结合的灵活的快照克隆技术也在保持Exadata性能的同时为CI/CD需要的测试开发数据库提供了方便灵活的解决方案;同时在存储层面也提供了给非Oracle数据库使用的基于RDMA的高性能块设备,解决原有Exadata VM Cluster数量受限于计算节点本地盘的限制。
