




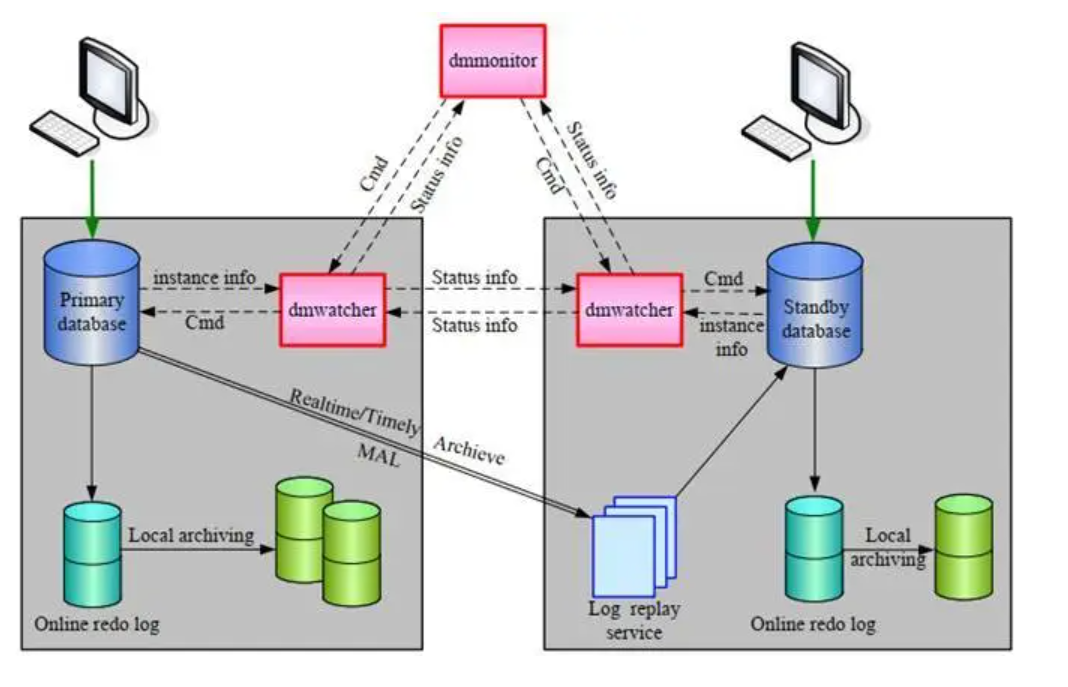
一、问题症状
客户的业务系统出现“系统处于MOUNT状态”错误,经核实达梦数据守护集群的Primary实例被OOM了,而且集群异常脑裂出现两个主库。为了避免再次被OOM,对虚拟机的内存进行扩容,同时也进行备库修复操作。


二、快速恢复业务
1、由于对业务系统的环境比较熟悉,因此看到报错关键字MOUNT,马上就想到达梦数据库可能异常了。
2、通过客户端尝试登录数据库,遇到同样的错误。此时心中也在疑惑,达梦数据守护集群会自动进行主备切换,怎么会异常呢。
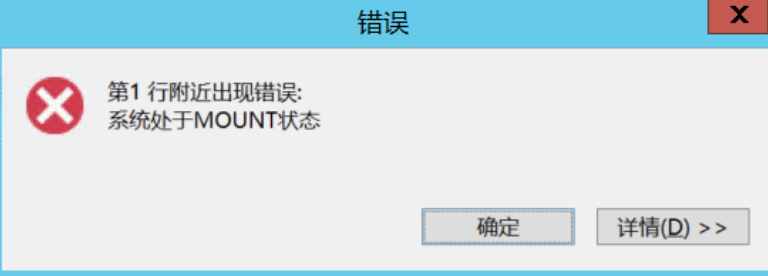
3、赶紧登录主库服务器,通过disql SYSDBA登录实例检查,看到该实例是PRIMARY角色且处于MOUNT状态。达梦数据库为了保证数据一致性,守护进程没有把实例OPEN。
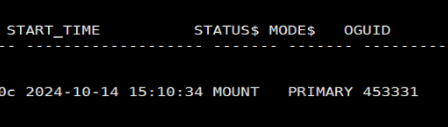
4、接着,登录备库和监视器服务器,确认备库已经自动切换为新的主库,而且处于OPEN状态。从监视器输出内容看到集群明显出现脑裂,集群出现两个PRIMARY主库。即RW1实例的WCTLSTAT字段值为SPLIT,输出内容如下。
[dmdba@localhost monitor]$ dmmonitor dmmonitor.ini[monitor] 2024-10-14 23:40:32: DMMONITOR[4.0] V8[monitor] 2024-10-14 23:40:33: DMMONITOR[4.0] IS READY.[monitor] 2024-10-14 23:40:33:#-----------------------------------------------------------------------------------------------#GET MONITOR CONNECT INFO FROM DMWATCHER(RW1), THE FIRST LINE IS SELF INFO.DW_CONN_TIME MON_CONFIRM MID MON_IP MON_VERSION2024-10-14 23:40:31 TRUE 1999360674 ::ffff:192.168.xx.208 DMMONITOR[4.0] V8#-----------------------------------------------------------------------------------------------#[monitor] 2024-10-14 23:40:33: Received message from(RW1)WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN2024-10-14 23:40:31 STARTUP OK RW1 MOUNT PRIMARY NULL 8 45015298 45015298[monitor] 2024-10-14 23:40:33: Received message from(RW2)WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN2024-10-14 23:40:30 OPEN OK RW2 OPEN PRIMARY VALID 8 45047073 45047073show2024-10-14 23:40:48#================================================================================#GROUP OGUID MON_CONFIRM MODE MPP_FLAGGRP1 453331 TRUE AUTO FALSEGROUP SPLIT:1: DATABASE(RW2):<<DATABASE GLOBAL INFO:>>DW_IP MAL_DW_PORT WTIME WTYPE WCTLSTAT WSTATUS INAME INST_OK N_EP N_OK ISTATUS IMODE DSC_STATUS RTYPE RSTAT192.168.xx.207 62141 2024-10-14 23:40:44 GLOBAL VALID OPEN RW2 OK 1 1 OPEN PRIMARY DSC_OPEN TIMELY VALIDEP INFO:INST_IP INST_PORT INST_OK INAME ISTATUS IMODE DSC_SEQNO DSC_CTL_NODE RTYPE RSTAT FSEQ FLSN CSEQ CLSN DW_STAT_FLAG192.168.xx.207 5236 OK RW2 OPEN PRIMARY 0 0 TIMELY VALID 3453762 45047237 3453762 45047237 NONE2: DATABASE(RW1):<<DATABASE GLOBAL INFO:>>DW_IP MAL_DW_PORT WTIME WTYPE WCTLSTAT WSTATUS INAME INST_OK N_EP N_OK ISTATUS IMODE DSC_STATUS RTYPE RSTAT192.168.xx.206 62141 2024-10-14 23:40:45 GLOBAL SPLIT STARTUP RW1 OK 1 1 MOUNT STANDBY DSC_OPEN TIMELY INVALIDEP INFO:INST_IP INST_PORT INST_OK INAME ISTATUS IMODE DSC_SEQNO DSC_CTL_NODE RTYPE RSTAT FSEQ FLSN CSEQ CLSN DW_STAT_FLAG192.168.xx.206 5236 OK RW1 MOUNT STANDBY 0 0 TIMELY INVALID 3447215 45015298 3447215 45015298 NONEDATABASE(RW1) APPLY INFO FROM (RW2), REDOS_PARALLEL_NUM (1), WAIT_APPLY[FALSE]:DSC_SEQNO[0], (RSEQ, SSEQ, KSEQ)[3447215, 3447215, 3447215], (RLSN, SLSN, KLSN)[45015298, 45015298, 45015298], N_TSK[0], TSK_MEM_USE[0]REDO_LSN_ARR: (45015298)
5、为了避免前端的应用请求异常的主库,手动将角色设置为STANDBY。
SP_SET_PARA_VALUE(1, 'ALTER_MODE_STATUS', 1);alter database standby;SP_SET_PARA_VALUE(1, 'ALTER_MODE_STATUS', 0);
6、尝试把备库拉起来,但是主从同步依旧存在问题。
SP_SET_PARA_VALUE(1, 'ALTER_MODE_STATUS', 1);alter database open force;SP_SET_PARA_VALUE(1, 'ALTER_MODE_STATUS', 0);
7、进一步与厂家确认沟通,只能对备库进行重建修复。
三、快速重建备库
1、执行主库的全备作业,生成最新全量备份集。
方法一:$ disql SYSDBA/密码SQL> backup database full backupset '/dmdata/dmbak/DB_dmdb_FULL_2024_10_14_2248'compressed level 1 task thread 8 parallel 8;方法二:--1716962375 bakfull-- select * from sysjob.sysjobs where name='bakfull';-- SP_DBMS_JOB_RUN (1716962375);
2、将最新全备文件传到备库
$ cd dmdata/dmbak$ scp -r DB_dmdb_FULL_2024_10_14_2248 dmdba@192.168.xx.206:/dmdata/dmbak/
3、通过监视器,执行login登录后将备库踢出集群。
dmmonitor path=/dmdata/monitor/man.inilogindetach database RW1
4、备库还原数据库
1、守护服务关闭DmWatcherServiceDW statusDmWatcherServiceDW stop2、DM服务关闭DmServiceDW statusDmServiceDW stop3、对DAMENG数据目录进行备份4、进行数据恢复dmrmanRMAN> restore database '/dmdata/data/DAMENG/dm.ini' from backupset '/dmdata/dmbak/DB_dmdb_FULL_2024_10_14_2248'RMAN> recover database '/dmdata/data/DAMENG/dm.ini' from backupset '/dmdata/dmbak/DB_dmdb_FULL_2024_10_14_2248'RMAN> recover database '/dmdata/data/DAMENG/dm.ini' update db_magicRMAN> exit5、mount方式启动dmserver dmdata/data/DAMENG/dm.ini mount6、将数据库模式改为STANDBYdisql SYSDBA/'"密码"'@localhost:5236SP_SET_PARA_VALUE(1, 'ALTER_MODE_STATUS', 1);ALTER DATABASE STANDBY;SP_SET_PARA_VALUE (2,'ALTER_MODE_STATUS',0);exit7、第5步窗口执行exit退出
5、启动备库,并将备库加入集群
1、启动备库DmServiceDW startDmWatcherServiceDW start2、通过监视器将备库加入集群dmmonitor monitor/man_dmmonitor.iniattach database RW1
6、以上是对备库修复的步骤。而对于脑裂环境,备库还是处于MOUNT状态。
四、脑裂知识扩展及关键修复点
[dmdba@localhost DAMENG]$ more dmwatcher.ctl_delDMWATCHER8001y info in sysopenhistory, set local to split status.!!!][dmdba@localhost DAMENG]$ strings dmwatcher.ctl_delDMWATCHER8001[!!! Local(RW1, PRIMARY & MOUNT & OK)'s sysopenhistory is included inremote(RW2, PRIMARY & OPEN & OK), but local apply info is largeror corssed with remote apply info in sysopenhistory,set local to split status.!!!]
近期热门文章:
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
文章转载自数据库运维之道,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
