





在现如今激烈的市场竞争中,销售数据是企业下一步市场决策的重要依据。销售数据提供了关于市场需求、客户行为、产品表现等方面的详细信息。通过深入分析这些数据,企业销售人员、决策者等可以获取有关市场趋势和消费者偏好的宝贵洞察,从而做出更加明智和精准的决策。

某公司的市场份额一直处于快速增长的态势,为了更好的统一数据口径、保障数据质量、控制数据权限,企业内部已将分散的销售数据统一到一套可视化分析平台中。
该平台之前由开源ClickHouse作为数据分析引擎,但在引入鉴权ACL用于管理数据权限、保障数据安全之后,该平台出现性能不足、影响用户体验的情况。
ByteHouse是火山引擎推出的一款定位为OLAP的分析型数据库,基于ClickHouse进行架构升级和优化,在复杂查询层面拥有显著优势。
该公司引入ByteHouse之后,结合相关销售场景,对ByteHouse优化器能力点对点优化,实现查询效率显著提升,在某些场景下效率提升达到16倍。
本文将从业务痛点、解决方案、优化结果三个方面,详细拆解该公司销售数据平台如何基于ByteHouse复杂查询能力实现效率提升。
01
业务背景
SELECT(concat(one_year,'-',casewhen substring(one_quarter, 5) = '01' then 'Q1'when substring(one_quarter, 5) = '02' then 'Q2'when substring(one_quarter, 5) = '03' then 'Q3'when substring(one_quarter, 5) = '04' then 'Q4'else nullend)) AS _1700010720846,(sum(CAST(daily_value_usd 100000 as Nullable(Float64)))) AS _sum_1700010720933FROM`aeolus_data_db`.`aeolus_data_table`WHERE(p_date >= '2024-02-20')AND (p_date <= '2024-02-20')AND arraySetCheck(`emp_ids`, (1527))GROUP BYconcat(one_year,'-',casewhen substring(one_quarter, 5) = '01' then 'Q1'when substring(one_quarter, 5) = '02' then 'Q2'when substring(one_quarter, 5) = '03' then 'Q3'when substring(one_quarter, 5) = '04' then 'Q4'else nullend)LIMIT10000
SELECT(concat(one_year,'-',casewhen substring(one_quarter, 5) = '01' then 'Q1'when substring(one_quarter, 5) = '02' then 'Q2'when substring(one_quarter, 5) = '03' then 'Q3'when substring(one_quarter, 5) = '04' then 'Q4'else nullend)) AS _1700010720846,(sum(CAST(daily_value_usd 100000 as Nullable(Float64)))) AS _sum_1700010720933FROM(SELECT*FROM`aeolus_data_db`.`aeolus_data_table`WHERE(`oid` IN (SELECT`oid`FROM`db`.`auths` as auth_table_c4cde165_485d_4bWHERE((arraySetCheck(auth_table_c4cde165_485d_4b.`emp_ids`, (1527))or arraySetCheck(auth_table_c4cde165_485d_4b.`dept_ids`,(123456,234567,345678,456789))or arraySetCheck(auth_table_c4cde165_485d_4b.`sales_owner_dept_ids`,(13579, 246810))or arraySetCheck(auth_table_c4cde165_485d_4b.`queue_ids`,(6969968376940593921))or arraySetCheck(auth_table_c4cde165_485d_4b.`auth_code_ids`,(654321,54321,86421)))and auth_table_c4cde165_485d_4b.`is_active` == 0))))WHERE(p_date >= '2024-02-20')AND (p_date <= '2024-02-20')GROUP BYconcat(one_year,'-',casewhen substring(one_quarter, 5) = '01' then 'Q1'when substring(one_quarter, 5) = '02' then 'Q2'when substring(one_quarter, 5) = '03' then 'Q3'when substring(one_quarter, 5) = '04' then 'Q4'else nullend)LIMIT10000
02
业务痛点
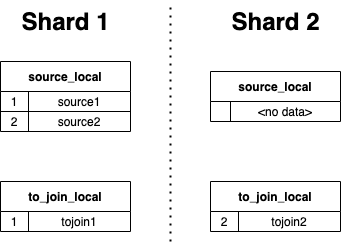
SELECTsource.key,source.value,to_join.valueFROM source AS sourceINNER JOIN(SELECT *FROM to_join AS tj) AS to_join USING (key)
+-----+---------+| key | value |+-----+---------+| 1 | tojoin1 || 2 | tojoin2 |+-----+---------+
SELECTsource.key,source.value,to_join.valueFROM source AS sourceGLOBAL INNER JOIN(SELECT *FROM to_join AS tj) AS to_join USING (key)
03
解决方案
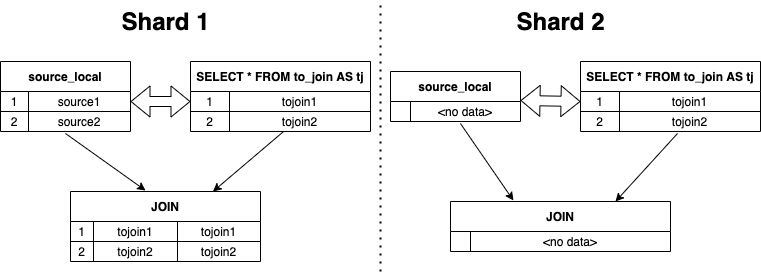
set enable_optimizer=1;EXPLAINSELECTsource.key,source.value,to_join.valueFROM source AS sourceGLOBAL INNER JOIN(SELECT *FROM to_join AS tj) AS to_join USING (key)┌─explain─────────────────────────────────────────────────┐│ Projection Est. ? rows ││ │ Expressions: [key, value], to_join.value:=value_1 ││ └─ Gather Exchange Est. ? rows ││ └─ Inner Join Est. ? rows ││ │ Condition: key == key_1 ││ ├─ TableScan test.source Est. 0 rows ││ │ Outputs: [key, value] ││ └─ Broadcast Exchange Est. 0 rows ││ └─ TableScan test.to_join Est. 0 rows ││ Outputs: key_1:=key, value_1:=value │└─────────────────────────────────────────────────────────┘
┌─explain─────────────────────────────────────────────────┐│ Projection Est. ? rows ││ │ Expressions: [key, value], to_join.value:=value_1 ││ └─ Gather Exchange Est. ? rows ││ └─ Inner Join Est. ? rows ││ │ Condition: key == key_1 ││ ├─ Repartition Exchange Est. 0 rows ││ │ │ Partition by: {key} ││ │ └─ TableScan test.source Est. 0 rows ││ │ Outputs: [key, value] ││ └─ Repartition Exchange Est. 0 rows ││ │ Partition by: {key_1} ││ └─ TableScan test.to_join Est. 0 rows ││ Outputs: key_1:=key, value_1:=value │└─────────────────────────────────────────────────────────┘
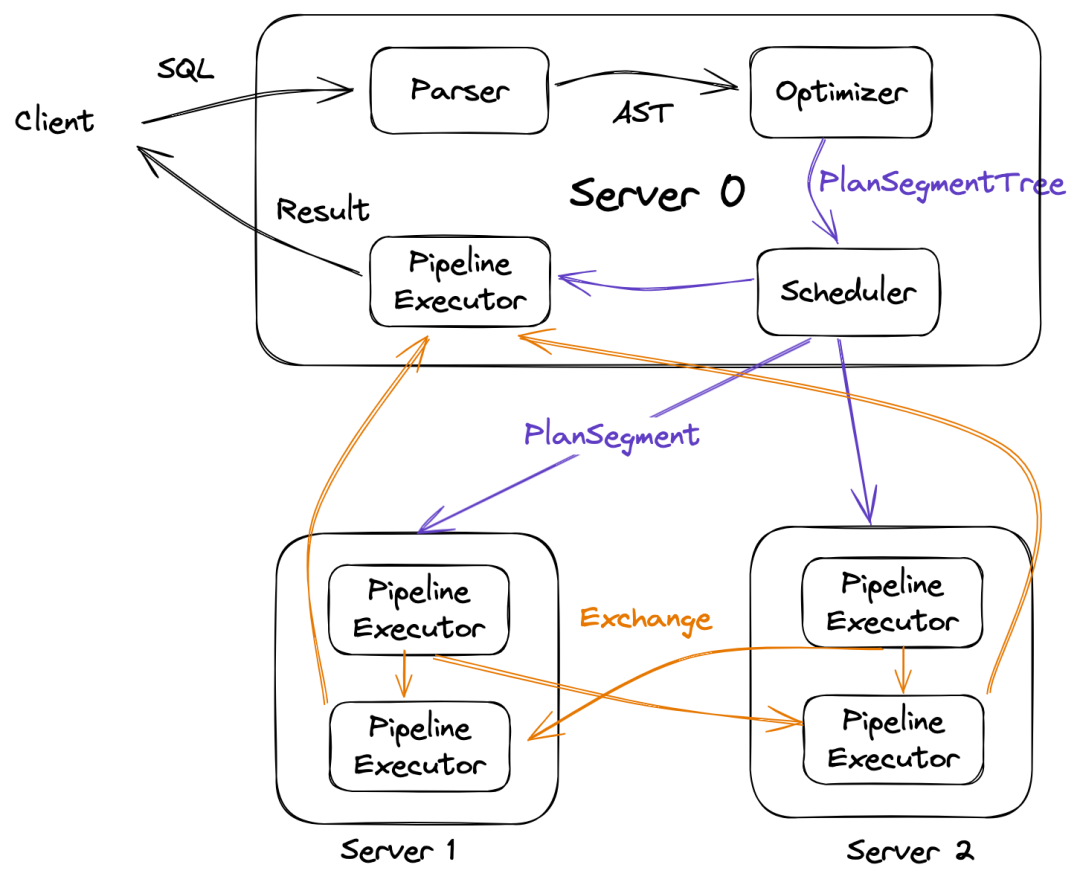
● 优化一:RBO
1. 解关联
2. 非等值Join优化
● 优化二:CBO
● 优化三:分布式计划优化
● 优化四:高阶优化能力
下面为tpch的数据(6亿数据的lineitem表)在一个两节点集群测试(最后merge的节点为同一个),SQL如下:
select count(distinct l_orderkey) from lineitem
04
优化结果
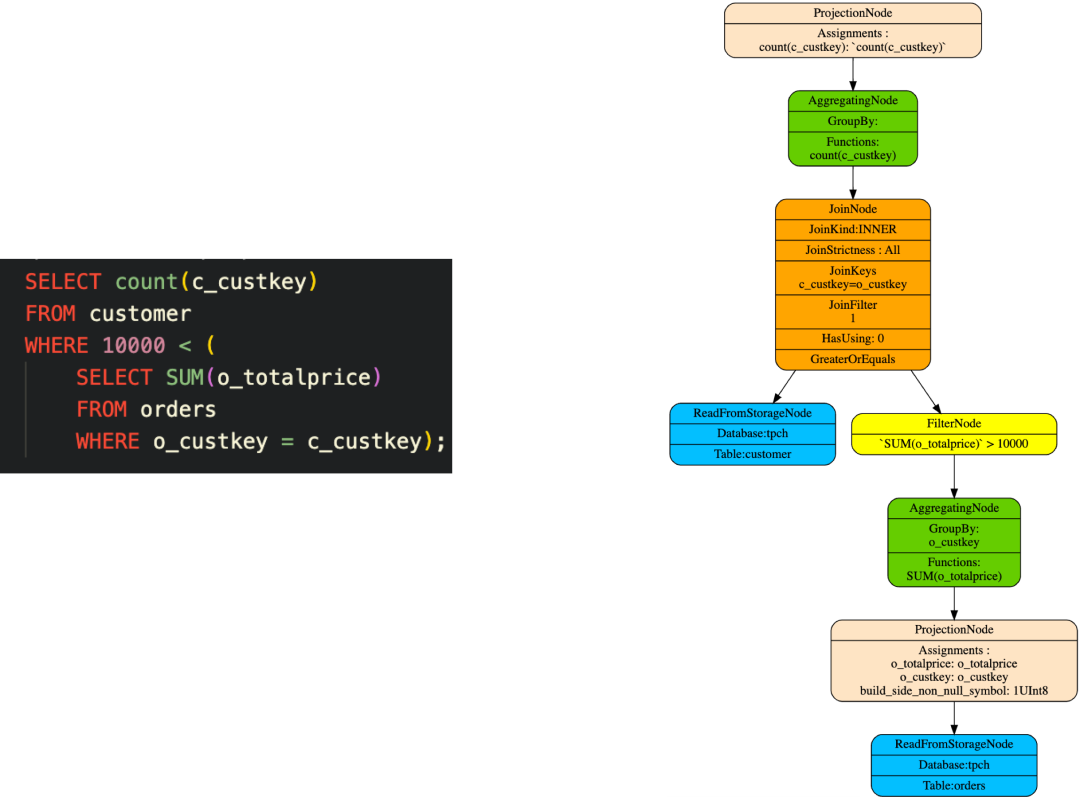
抽取该公司销售平台某数据集测试
抽取该公司销售平台某数据集测试

往期推荐




 点击阅读原文,了解ByteHouse产品信息
点击阅读原文,了解ByteHouse产品信息文章转载自字节跳动数据平台,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
