




前言
上一篇我们讲了HaloDB中如何使用Patroni实现高可用,本篇来聊聊HaloDB中的读写分离解决方案DLB,废话不多说,打个广告就开车。
如果有对我们的产品感兴趣的朋友可以通过主页的联系方式与我取得联系,获取license来安装体验,欢迎来喷,进群请私聊我获取。
一、什么是读写分离:
数据库的读写分离是指将数据库的读操作和写操作分别分配到不同的数据库服务器上进行处理,以提高数据库的性能和可用性。具体来说,读写分离的原理是让主数据库(master)处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库(slave)处理SELECT查询操作。
数据库读写分离的好处主要体现在以下几个方面:
- 提高性能:通过将读操作和写操作分散到不同的服务器上,可以降低对主服务器的负载压力,提高数据库的并发处理能力。这样可以避免主服务器在读写操作较多时出现性能瓶颈。
- 降低阻塞 :当主服务器进行写操作时,不会影响查询应用服务器的查询性能,降低了阻塞的发生,提高了并发性。这确保了即使在高并发的情况下,用户也能获得良好的查询体验。
- 提高数据安全性:数据拥有多个容灾副本,可以提高数据安全性。当主服务器出现故障时,可以立即切换到其他服务器,保证系统的可用性。这种容错能力使得读写分离架构在关键业务场景中更加可靠。
- 优化资源配置:读写分离可以根据实际需求调整不同服务器的硬件配置,以更好地满足读写操作的需求。例如,读操作更多的服务器可以配置更多的CPU和内存资源,以提高查询性能;而写操作更多的服务器则可以配置更高的磁盘I/O性能,以确保事务的及时处理。
- 减少锁表时间:在应用程序提交了报表请求、不合理的查询请求时,读写分离架构可以避免长时间的锁表,从而提高了系统的整体性能。
总之,数据库的读写分离架构可以提高数据库的性能和可用性,降低阻塞的发生,提高数据安全性,并优化资源配置。这种架构在应对高并发、大数据量等复杂场景时具有明显优势。
二、HaloDB之DLB简介:
DLB(Database Load Balancer,数据库负载均衡器)是一种高效的数据库读写分离解决方案。它通过智能地分发数据库读写请求到不同的服务器节点上,实现了数据库系统的高性能和可扩展性。
在DLB的架构中,通常包含一个主数据库(Master Database)和多个从数据库(Slave Databases)。主数据库负责处理写操作(如INSERT、UPDATE、DELETE等),确保数据的完整性和一致性;而从数据库则负责处理读操作(如SELECT),为用户提供快速的数据查询服务。
DLB通过负载均衡算法,将读请求分发到多个从数据库上,从而充分利用了系统的硬件资源,提高了系统的并发处理能力和吞吐量。同时,由于读操作不再对主数据库造成压力,主数据库可以更专注于处理写操作,进一步提高了系统的性能。
此外,DLB还具备以下优点:
- 高可用性:DLB支持主从数据库之间的自动切换和故障转移。当主数据库出现故障时,DLB可以自动将从数据库中的一个节点提升为主数据库,确保系统的持续运行。
- 数据一致性:DLB通过复制机制,确保主从数据库之间的数据同步。这保证了在读写分离架构下,用户读取到的数据始终是最新的。
- 灵活性:DLB支持多种数据库类型,如MySQL、PostgreSQL等,并且可以根据实际需求进行配置和扩展。这使得DLB能够适应不同的业务场景和数据库环境。
- 可监控和管理:DLB提供了丰富的监控和管理功能,可以实时监控数据库的运行状态、性能指标和负载情况。这使得管理员可以及时发现潜在的问题并进行处理,确保系统的稳定运行。
总之,DLB作为HaloDB数据库目前的读写分离解决方案,可以帮助企业实现高性能、高可用性和可扩展性的数据库系统。它不仅可以提高系统的性能和并发处理能力,还可以降低系统的故障风险,提高业务的连续性和稳定性。
DLB架构图如下: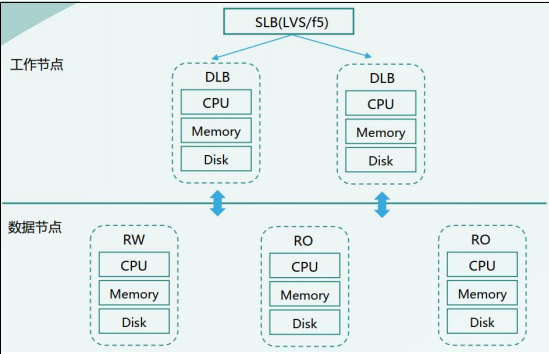
如上图所示,DLB 架构分为两层,上层是工作节点,工作节点存放数据库的元数据,上层DB是无状态,无数据的,可横向拓展的(多工作节点情况就需要在工作节点上面做一层负载均衡可采用 LVS/f5)。下层是数据节点,存放数据的,是一个高可用的集群(如上图所示由一主二从的物理流复制集群组成),工作节点和数据节点之间使用私有的统信协议,避免多次解析。
DLB的工作流程是工作节点在接收到应用发来的 SQL,针对 SQL 语句进行识别,进行分发关于写的 SQL都会分发到写的数据节点进行操作,读操作的 SQL 会分发到三个节点进行处理。用一个流程图来展示更直观些~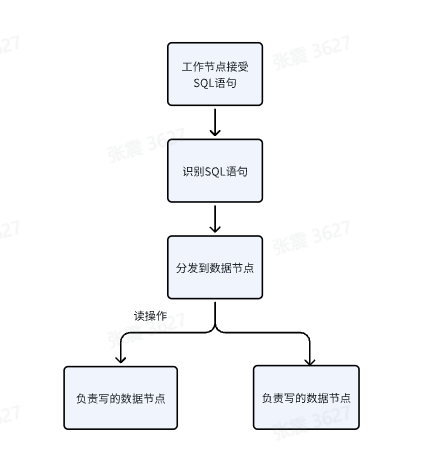
三、DLB的安装部署
1、环境准备:
| IP地址 | 角色 |
|---|---|
| 192.168.231.174 | 工作节点 |
| 192.168.231.175 | 主数据节点 |
| 192.168.231.176 | 备数据节点 |
注意:175 和 176 节点需要完成搭建物理流复制
注意:175 和 176 节点需要完成搭建物理流复制
注意:175 和 176 节点需要完成搭建物理流复制
下面开始DLB的部署:
2、在工作节点的配置文件 postgresql.conf 中修改参数:
Instance_type='RDBMS' --> Instance_type='DLB'
3、启动工作节点的 Halo 数据库并创建测试所需要的扩展,测试数据库和测试用户:
--halo 用户下
--启动数据库
pg_ctl start
--创建测试用户
psql -c "CREATE USER dbadmin SUPERUSER PASSWORD '123456';"
psql -c "CREATE USER halo_test SUPERUSER PASSWORD '123456';"
--创建测试库
psql -c "CREATE DATABASE dlb_test;"
--创建 dlb_fdw 扩展
psql -d dlb_test -c "create extension dlb_fdw;"
4、创建 fdw-server:
在工作节点(192.168.231.174 )上创建,DLB 集群的 fdw (foreign-data wrapper,外部数据包装器)server,一个数据节点对应一个服务,主节点必须是 01。
4.1、halo 用户下使用 psql 登录到 dlb_test 数据库
psql -d dlb_test
4.2、修改为数据节点的 ip 地址、端口、数据库名:
create server dlb_fdw_halo_db_0001 foreign data wrapper dlb_fdw options(host
'192.168.231.175', port '1921', dbname 'dlb_test');
create server dlb_fdw_halo_db_0002 foreign data wrapper dlb_fdw options(host
'192.168.231.176', port '1921', dbname 'dlb_test');
说明:
外部服务的名称:dlb_fdw_halo_db_0001、dlb_fdw_halo_db_0002:
dlb_fdw:为DLB 集群工作节点所必需的插件
host:指定数据节点的 ip
port :指定数据节点的端口
dbname: 指向数据节点的数据库
5、创建用户定义映射:
HaloDB需要将数据节点中的用户映射到工作节点的用户中,以便在访问外部数据源时进行身份验证和授权。这样确保只有经过授权的用户能够访问外部数据源,并且可以根据数据节点中的用户权限来限制工作节点对数据源的访问。
--halo 用户下使用 psql 登录到 dlb_test 数据库
psql -d dlb_test
创建mapping用户:
CREATE user mapping for halo_test SERVER dlb_fdw_halo_db_0001 options(user 'dbadmin',
password '123456', password_required 'false');
CREATE user mapping for halo_test SERVER dlb_fdw_halo_db_0002 options(user 'dbadmin',
password '123456', password_required 'false');
说明:
halo_test:应用链接工作节点的数据库用户(实际外部表属于的数据库用户名)
hds_fdw_halo_db_01、hds_fdw_halo_db_02:外部服务器名称
dbadmin:数据节点数据库用户
需要给每个外部服务器都要创建一个用户映射
6、创建外部表:
外部表的结构要与数据节点的表一致,外部表可通过对应 server 使用对应的映射用户访问到数据节点。单个 dlb 节点可以不用加约束 check(id >= 1 and id <= 9000000000000000)
--halo 用户下使用 psql 登录到 dlb_test 数据库
psql -d dlb_test
create foreign table tab1(id int, name varchar(64), age int,check(id >= 1 and id <=
9000000000000000)) server dlb_fdw_halo_db_0001 options(schema_name 'public',
table_name 'tab1');
7、创建序列:
--halo 用户下使用 psql 登录到 dlb_test 数据库
psql -d dlb_test
create sequence if not exists tab1_id_seq increment by 1 minvalue 1 maxvalue
9000000000000000 start with 1;
8、为业务用户授权:
--halo 用户下使用 psql 登录到 dlb_test 数据库 psql -d dlb_test --授权外部服务器使用权限给业务用户 grant usage on FOREIGN SERVER dlb_fdw_halo_db_0001 to halo_test; --授权外部表给业务用户 GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO halo_test; GRANT ALL PRIVILEGES ON ALL sequences IN SCHEMA public TO halo_test;复制
至此,工作节点的部署就基本完成。下面是数据节点的部署
9、数据节点部署:
175 和 176 作为数据节点需要完成搭建物理流复制,流复制的部署方式可以参考Halo DB 14 小白零基础系列(10)
:https://www.modb.pro/db/1765272479002595328
