





点击上方【蓝字】关注我们
数据仓库建设的目的仍是为了下游应用,因此,降低下游用户的应用成本是至关重要的。下面这些问题,你可以看看是否遇到过。很多表名非常类似,涉及各个层级的数据,也不知道粒度如何,用起来非常混乱!表内的字段名特别乱,甚至不同表中相同含义字段的命名不一致!任务名与表名差异很大,很难找到表对应的调度任务是哪一个!以上这些问题,都是由于命名不规范所导致的。那规范的命名又包括哪些方面呢?下面,我们一起来看一下。
表命名规范
表命名,核心原则是“见名知意”,通过规范的标准,降低用户的识别成本。表命名的通用方式为[数据分层]_[业务域]_[内容描述]_[刷新周期]_[存储策略]。
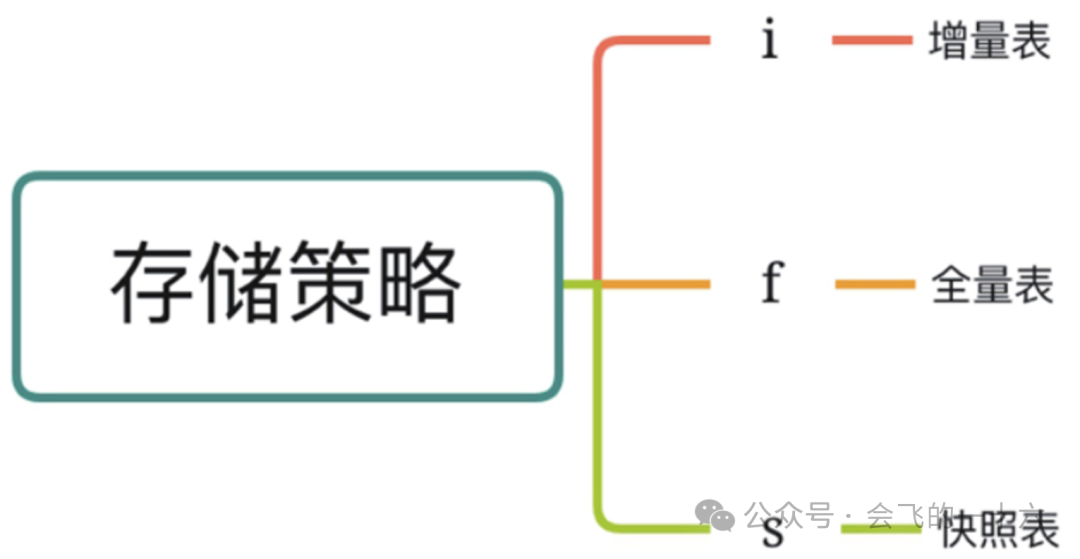
维表 命名形式:dim_描述 事实表 命名形式:fact_描述_[AB] 临时表 命名形式:tmp_ 正式表名_ [C自定义序号] 宽表 命名形式:dws_主题_描述_[AB] 备份表 命名形式:正式表名_bak_yyyymmdd
1)表名使用英文小写字母,单词之间用下划线分开,长度不超过40个字符,命名一般控制在小于等于6级。 2)其中ABC第一位"A"时间粒度:使用"c"代表当前数据,"h"代表小时数据,"d"代表天数据,"w"代表周数据,"m"代表月数据,"q"代表季度数据, "y"代表年数据。 3)其中ABC的第二位"B"表示对象属性,用"t"表示表,用"v"表示视图。 4)其中ABC的第三位"C"自定义序号用于标识多个临时表的跑数顺序。 
STORED AS INPUTFORMAT‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat’OUTPUTFORMAT‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat’

1.8 来源系统
如果数据来自特定的源系统,可以在名称中标注。
例如:_erp
、_crm
、_pos
-- 创建订单事实表(每日粒度)CREATE TABLE fact_order_daily (order_id INT,customer_id INT,order_date DATE,total_amount DECIMAL(10,2),-- 其他字段...);-- 创建客户维度表CREATE TABLE dim_customer (customer_id INT,customer_name VARCHAR(100),customer_email VARCHAR(100),-- 其他字段...);-- 创建来自ERP系统的库存汇总表(月度粒度)CREATE TABLE dws_inventory_monthly_erp (product_id INT,warehouse_id INT,month_date DATE,avg_stock_qty INT,-- 其他字段...);-- 创建临时表用于数据处理CREATE TABLE tmp_order_analysis (-- 临时分析用字段...);
下划线连接:使用下划线 _
连接不同的单词,提高可读性。

字段命名规范

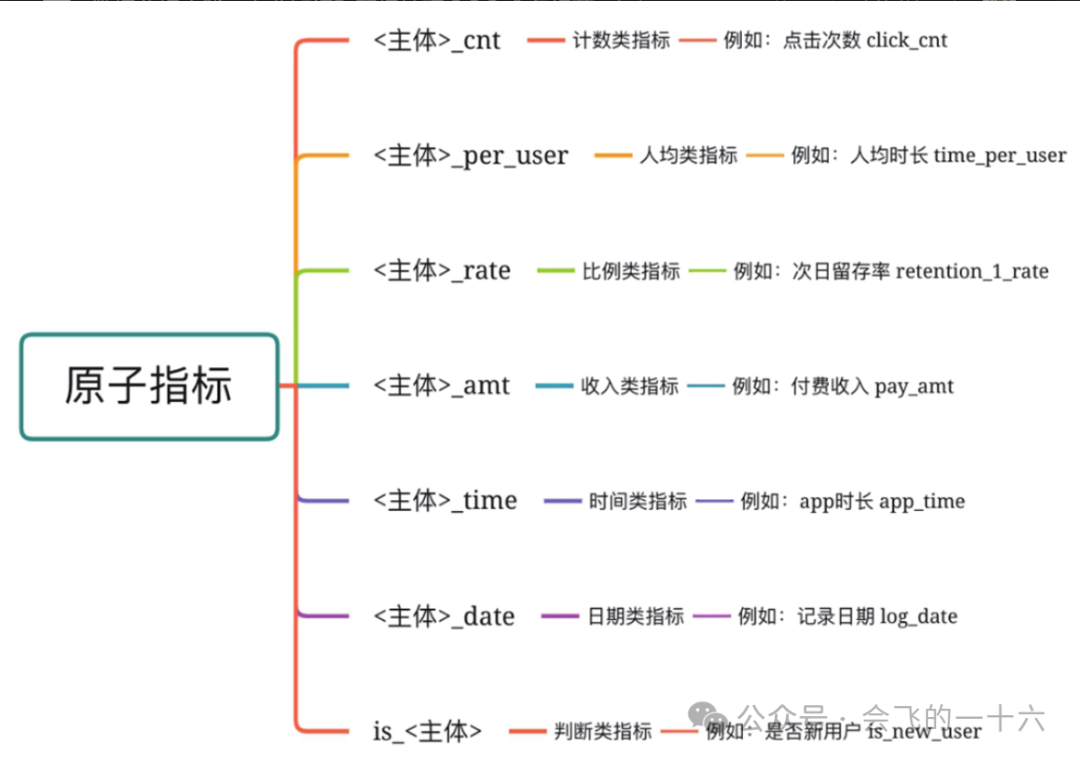

3) 派生指标

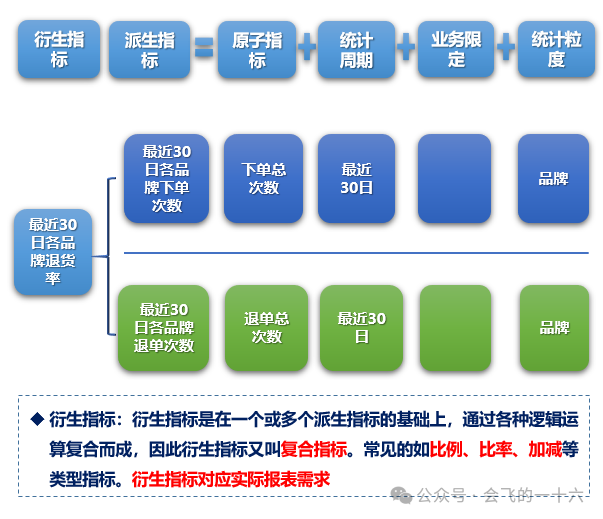
4)衍生指标
is_ 表示布尔值(例如:is_active)has_ 表示布尔值(例如:has_children)num_ 表示计数(例如:num_orders)pct_ 表示百分比(例如:pct_discount)amt_ 表示金额(例如:amt_total)
date 后缀表示日期(例如:order_date) time 后缀表示时间(例如:login_time) timestamp 后缀表示时间戳(例如:create_timestamp)
例如:customer_id、order_id外键:外键字段应与引用表的主键名称保持一致。例如:如果 customer 表的主键是 customer_id,那么在 order 表中引用它的外键也应该叫 customer_id
CREATE TABLE fact_order (order_id INT PRIMARY KEY,customer_id INT, -- 外键,引用 dim_customer 表order_date DATE,order_timestamp TIMESTAMP,total_amount DECIMAL(10,2),num_items INT,is_paid BOOLEAN,payment_method VARCHAR(50),discount_pct DECIMAL(5,2),shipping_amt DECIMAL(8,2),has_gift_wrap BOOLEAN,-- 其他字段...);CREATE TABLE dim_customer (customer_id INT PRIMARY KEY,customer_name VARCHAR(100),customer_email VARCHAR(100),registration_date DATE,is_active BOOLEAN,last_login_timestamp TIMESTAMP,lifetime_value DECIMAL(12,2),-- 其他字段...);
在这个例子中,我们可以看到:
字段名清晰描述了其内容(例如 total_amount、num_items)使用了适当的前缀(例如 is_paid、discount_pct)时间相关字段使用了统一的后缀(_date、_timestamp)主键和外键的命名保持一致(customer_id)所有字段名都是小写并使用下划线连接通过遵循这些规则,我们可以创建出清晰、一致且易于理解的数据模型,大大提高了数据仓库的可用性和可维护性。

任务命名规范

表的生成代码往往需要配置一个调度任务加以完成,这里需要注意,调度任务命名需与表命名一致,建议采用相同的名称,如果已被占用,建议使用表命名作为基准,增加后缀作为任务命名,方便后续查找应用。
命名规范
ETL 脚本名称尽可能和所产出的表同名;数据采集、数据推送脚本尽可能标识数据去向;ETL 脚本若产生多个表,采用对应的数据域和语义描述命名;Jar 包命名以实际的业务处理逻辑语义描述为主,调度任务命名同样尽量以产出表名命名根据脚本命名规范。
dws_jttl_pull_month_tmp_exp.sh
dws_jttl_pull_month.sh
dws_phm_switchshock_min_hh_mm.sh
层级命名规范

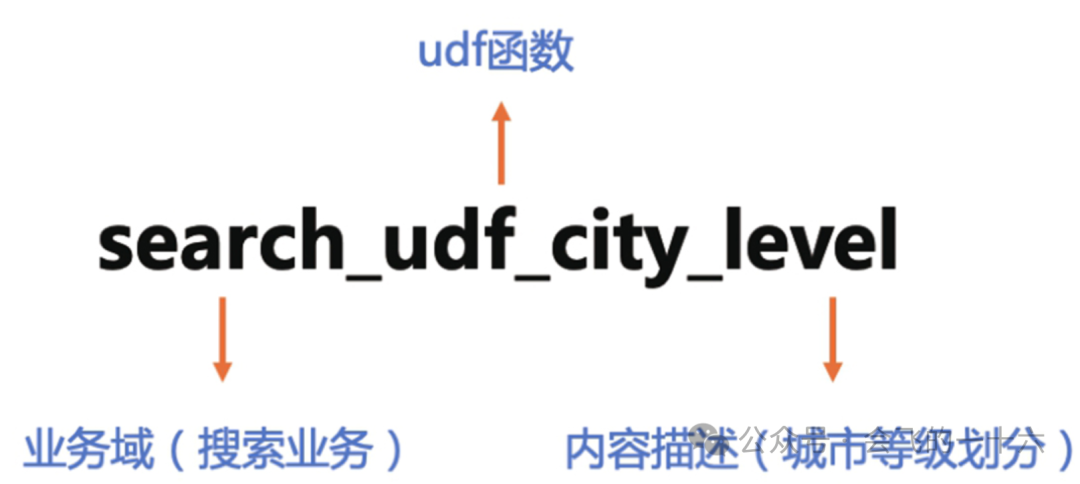
自定义函数命名规范
~~未完待续~~
猜你喜欢


公众号:会飞一十六
扫码关注 了解更多内容

点个 在看 你最好看
文章转载自会飞的一十六,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
