





增量物化视图的核心在于"增量",仅处理自上次更新以来的数据变动,避免重新计算整个视图,显著降低计算和时间开销。通过捕获并计算增量数据,它能高效维护最新数据结果,在实时数据分析、报表生成和数据同步等场景中,成为提升查询性能、减少存储开销的不可或缺工具。
在《CloudberryDB内核分享:增量物化视图的原理与实现讲解》直播中,我们深入探讨了视图、物化视图、增量物化视图的基本概念与应用实践,同时分享了Cloudberry Database中的IVM实施策略以及物化视图所展现的高效查询性能。欢迎感兴趣的朋友们回顾本次分享。
视图和物化视图

视图(View)
CREATE VIEW V ASSELECT device_name, pid, price FROM devices dJOIN parts pON d.pid = p.pid;
视图是一种虚拟表,它仅存储定义,并不存储实际的数据。视图是根据基础表通过SQL查询语句组合、计算或过滤数据创建的。用户可以像操作普通表一样对视图进行SELECT操作,但实际上每次查看视图时,都会实时执行相应的查询。
物化视图(Materialized View)
CREATE MATERIALIZED VIEW V ASSELECT device_name, pid, price FROM devices dJOIN parts pON d.pid = p.pid;
与普通视图不同,物化视图不仅存储了视图的定义,还将其查询结果持久化存储在数据库中,通常存储在一个物理表中。因此,当查询命中物化视图时,数据库可以直接从存储的结果中读取数据,而无需重新计算SELECT语句,从而提高了查询效率。但需要注意的是,为了保持数据的时效性,需要手动刷新物化视图来更新其存储的数据。
增量物化视图
CREATE INCREMENTAL MATERIALIZED VIEW mv ASSELECT device_name, pid, price FROM devices dJOIN parts pON d.pid = p.pid;
增量物化视图(Incremental Materialized View,简称IVM)在物化视图的基础上增加了INCREMENTAL关键字,用于指示数据库以增量的方式自动维护视图数据。当基础数据发生变化时,增量物化视图能够自动捕捉这些变化并仅更新受影响的数据部分,而无需重新计算整个视图。
特定情况下,用户也可以使用REFRESH命令手动刷新增量物化视图,以确保数据的完全一致性。
物化视图的维护机制
下图展示了物化视图的维护机制直观流程,图中绿色路径,它代表了传统物化视图的维护过程。其中,D代表基础表是数据变更的源头。每当D发生增量更新(如数据的插入、更新或删除),这些变更会触发一个全面的重新计算过程,沿着绿色路径进行,以生成新的物化视图Vnew。这一过程中,物化视图的内容会被完全重新计算,以确保与基础表D的最新状态保持一致。
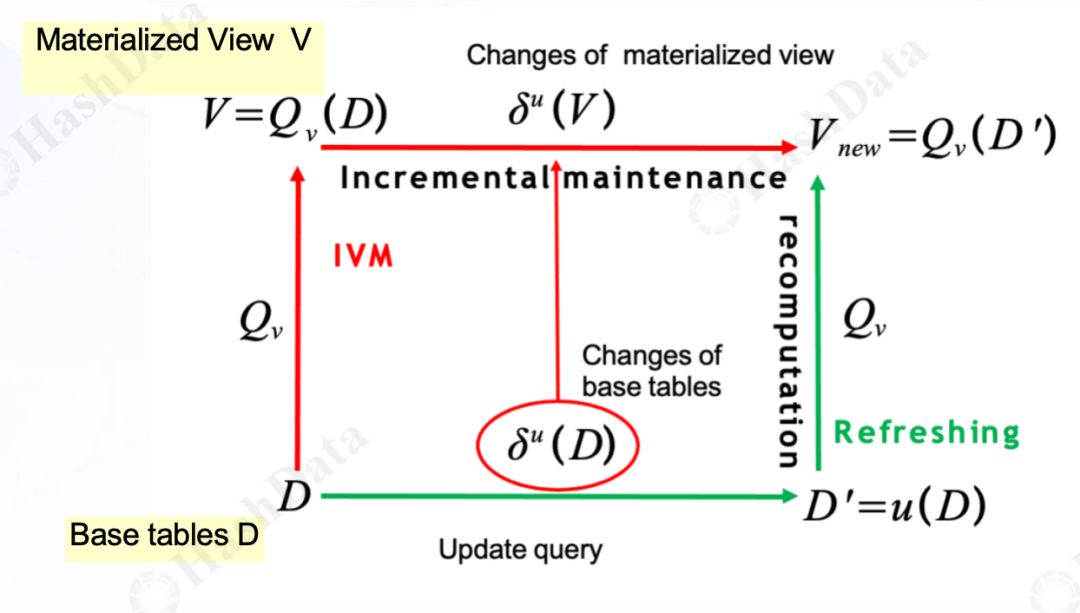
图1 物化视图的维护机制流程与IVM原理
为了优化这一过程,我们引入了增量物化视图(IVM)的概念,其维护方式通过图示中的红色路径清晰展现。与传统方式不同,IVM机制仅关注由基础表D更新引起的物化视图V中的变化部分。当D发生更新时,IVM会精确计算出这些变化对物化视图的具体影响,生成增量数据,并沿着红色路径将这些增量数据应用到现有的物化视图V上,从而生成新的物化视图Vnew。
通过对比两种路径,我们不难发现,IVM维护机制显著减少了计算量,特别是在处理大型数据集和频繁更新的环境中。这种针对性的增量更新策略不仅提高了物化视图维护的效率,还减少了系统资源的消耗,为数据库的整体性能带来了显著提升。
增量物化视图理论基础
增量物化视图将视图的定义转化为关系代数,并针对增量数据部分设计了一个传播方程。这一方程用于计算增量数据,并将这些增量应用到新的物化视图上。
以自然连接为例,假设视图V定义为表R与表S的自然连接。当基表R发生更新时,这些更新可以分解为删除和插入两部分。这里,我们使用∇表示R中被删除的数据,而Δ则代表R中新增的数据。
Natural join view defV = R⋈SChange on a base tableR ← (R − ∇R ∪ ∆R)
接下来,我们可以利用传播方程分别计算出视图V中由于R的更新而产生的删除部分∇V和插入部分ΔV。
Calculation of change on view∇V = ∇R ⋈ S∆V = ∆R ⋈ S
最终,得到更新后的物化视图V ,用代数表达式V← (V − ∇V ∪∆V)表示,即先从原视图v中移除被删除的部分,再并上新增的部分。这样,每次计算都基于增量数据,从而实现了高效的更新机制。
Apply the change to the viewV ← (V − ∇V ∪∆V)
以下图为例,当基础表R发生了一条更新操作,即将原本小写的"one"更新为大写的"ONE"。这是一个典型的数据更新场景。
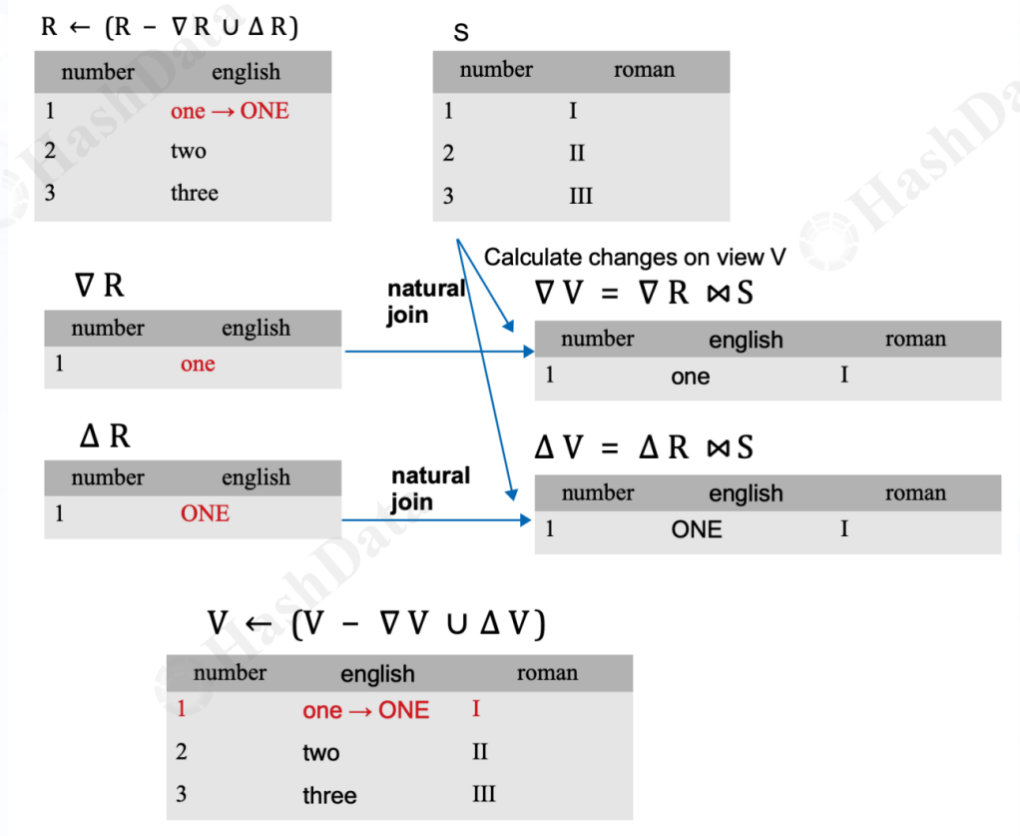
图2 数据更新过程举例
删除部分:删除基础表R中小写的"one",这可以表示为∇R(R中删除的部分)。 插入部分:在基础表R中插入大写的"ONE",这可以表示为ΔR(R中新增的部分)。
删除影响(∇V):将删除部分∇R与基础表S进行自然连接,得到的结果即为视图V中需要删除的部分。在这个例子中,小写的"one"与S连接后得到的结果集(假设为1条数据,仅为示例)需要从V中移除。 增加影响(ΔV):将新增部分ΔR(即大写的"ONE")与基础表S进行自然连接,得到的结果即为视图V中需要新增的部分。连接后得到的结果集我们称之为ΔV,它将被添加到V中。
视图V的最终更新是通过从当前V中减去删除部分(∇V),并加上增加部分(ΔV)来完成的。这样,V就反映了基础表R和S的最新自然连接结果。
CloudberryDB的IVM场景
IVM的即时维护
接下来,我们深入解析Cloudberry Database中IVM的立即维护流程,该流程主要包括以下三个步骤:
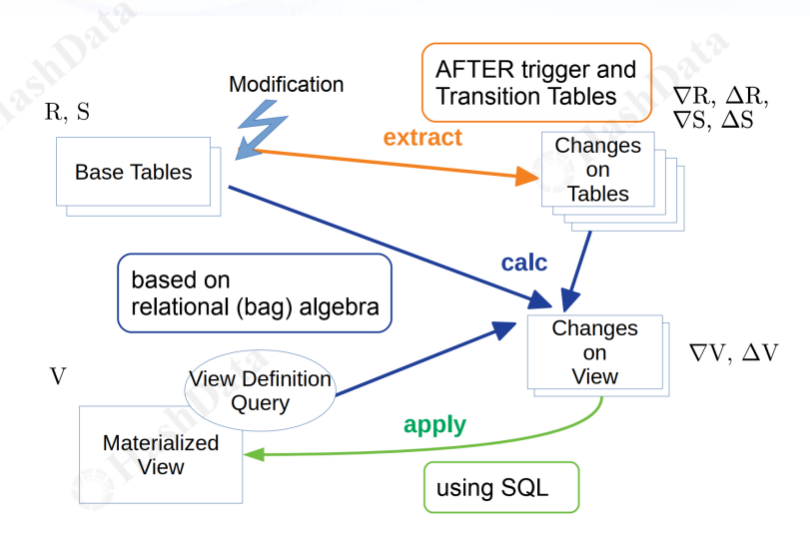
图4 元素增删示例
1.数据变化捕获:CloudberryDB利用触发器(after trigger)和转换表机制,实时追踪并获取基表的数据变动情况。
2.ΔV计算:这一过程涉及基表、基表变化数据以及可能的跨表连接(join)操作。计算基于关系代数和传播方程,处理包括简单的select、project、join操作,不包含更复杂的CTE和子查询(subquery)。
3.物化视图更新:将计算得到的Delta V应用到原物化视图上。这通常是一个追加(append)过程,可能伴随删除操作,以确保物化视图与基表数据的一致性。
在这一过程中,主要面临以下技术难点和挑战:
捕获增量变化的数据:采用AFTER trigger、Transition Table或WAL(Write-Ahead Logging)的逻辑解码等多种技术手段,确保增量数据的精准捕获。
增量计算:基于关系代数理论,实现Selection-Projection-Join视图的增量计算,确保计算的准确性和效率。
视图增量处理:针对重复元素问题,引入计数算法,通过动态调整计数来决定行的增删改操作,确保视图的准确性。
处理视图中的重复元素
在视图增量写入时,重复元素的考虑尤为重要。为此,CloudberryDB引入了一种计数(counting)算法。这种算法会对每一行进行计数,通过动态调整计数来决定行的增删改操作。例如,当删除一个元素时,其计数会减少;当插入一个新元素时,计数会增加。只有当计数变为0时,这一行才会真正被删除。
让我们通过一个具体的例子来说明这一点。假设视图中有重复元素,并且这个视图支持删除和插入操作。当删除一个元素时,其计数会从2减到1;当插入一个新元素时,计数也会相应地变化,比如从1增加到2。只有当计数变为0时,这一行才会真正被删除。还有一些规则用于判断,例如:
当元素被插入到视图中时,计数增加。
当元素从视图中被删除时,计数减少。
如果计数变为零,这个元素将被删除。
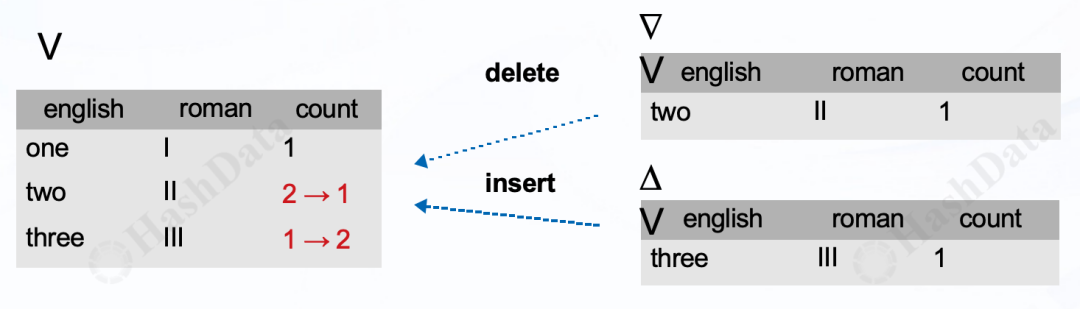
图5 IVM加速查询示例
聚合函数支持
count(x) ← count(x) ± [count(x) from delta table]
sum(x) ← sum(x) ± [sum(x) from delta table]
avg(x) ← (sum(x) ± [sum(x) from delta]) (count(x) ± [count(x) from delta])
min(x), max(x)
When tuples are inserted:
min(x) ← least (min(x), [min(x) from delta table])
max(x) ← greatest (max(x), [max(x) from delta table])
When tuples are deleted:
If the old min(x)
实践应用
在CloudberryDB中测试TPCH时,我们尝试利用IVM来加速性能。以Q9查询为例,我们创建了一个名为revenue0的视图。这个视图的定义并未发生改变,查询代码也保持不变,但现在它可以直接利用物化视图和增量物化视图的结果。

图5 IVM加速查询示例
针对不同的数据量,我们进行了一系列的测试,包括1GB、5GB和10GB的数据集。在使用revenue0这个视图时,如果是普通视图,1GB数据的查询时间是813ms。而如果使用增量优化视图,查询时间则缩短至43ms。对于更大的数据集,如10GB,普通视图的查询时间是7,057ms,而增量物化视图的查询结果仅为102ms,分别实现了~20倍与~70倍的性能提升。
需要注意的是,由于我们采用的是立即维护增量物化视图的方式,这会在一定程度上拖慢整个插入操作的性能。相比普通插入操作,带增量物化视图的插入操作性能会下降大约一倍左右。这是因为在进行插入操作时,系统还需要同时维护增量物化视图。
为了解决这个问题,我们在HashData Enterprise版本产品推出了异步维护功能。通过异步维护,系统可以在不牺牲插入性能的前提下,实现增量物化视图的更新和优化。
利用物化视图快速响应查询
如何利用物化视图快速响应查询?首先,明确问题定义:用户提出一个查询Q,我们手头有一系列物化视图的定义(V1到Vn)。目标是进行查询重写,得到一个与原查询Q等价的Q1',并在此过程中利用已有条件和视图来支撑这一改写。
问题定义:
Input: Query Q
View definitions: V1,……, Vn
A rewriting:
a query Q’ that refers only to the views and interpreted predicates
An equivalent rewriting of Q using V1,……, Vn:
a rewriting Q’, such that Q’ ⇔ Q
“Answering queries using views: A survey” by Alon Halevy.
VLDB Journal 10:270-294 (2001).
在实现查询重写时,首要原则是保持查询的等价性。我们采用基于规则的方法来实现查询的重写,并借助代价模型来选择最优的物化视图。这一过程对用户是透明的,即在执行查询计划时,系统会自动将查询替换为对物化视图的查询,从而显著提升查询性能。
create table agumv_t1(c1 int,c2 int,c3 int) distributed by(c1);insert into agumv_t1select i, i+l, i+2 from generate series(1,10000000)i;insert into agumv_t1 select * from agumv_t1;create incremental materialized view agumv_t1 0 as select * from agumv_t1 wherecl=2;select * from agumv_t1 where c1=2;
以T1表为例,该表包含三列并插入了1000万行数据。我们为其创建了一个特定条件下的增量物化视图。当执行满足这些条件的查询时,系统能够自动利用这个物化视图,将查询时间从1659ms缩短至43ms,实现了对用户透明的~40倍性能提升。
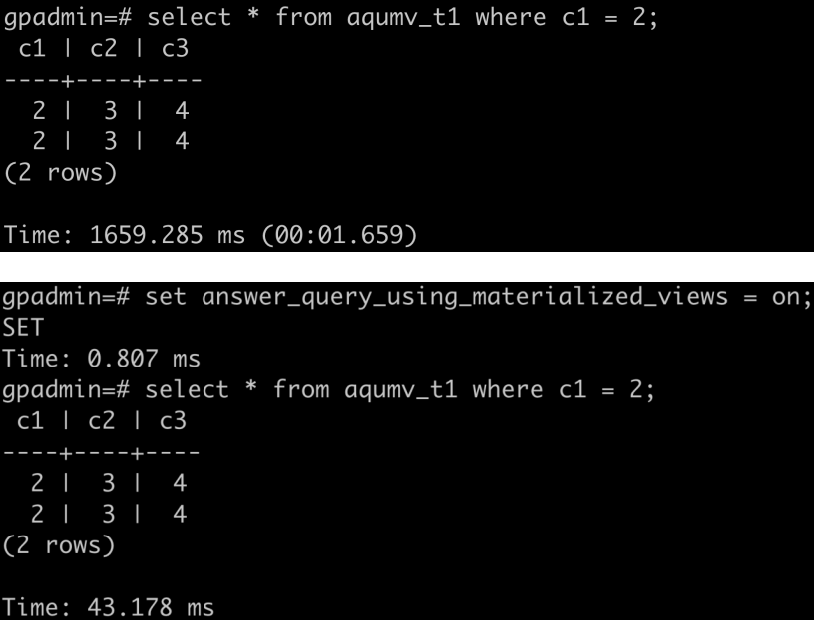
图6 查询结果对比
对于异步维护的物化视图,如果视图不是最新的,我们可能需要生成最新的查询计划。为了解决这个问题,我们引入了数据序列扫描算子。这个算子会首先尝试命中已有的物化视图版本,如果仍有部分数据未应用增量优化,则会通过SQL扫描进行额外的聚集运算。
最终,这两部分的结果会通过append算子进行合并,并经过必要的重排序和最终聚集后返回给用户。这一过程也是我们在HashData Enterprise版本产品中针对异步维护场景的具体实现。
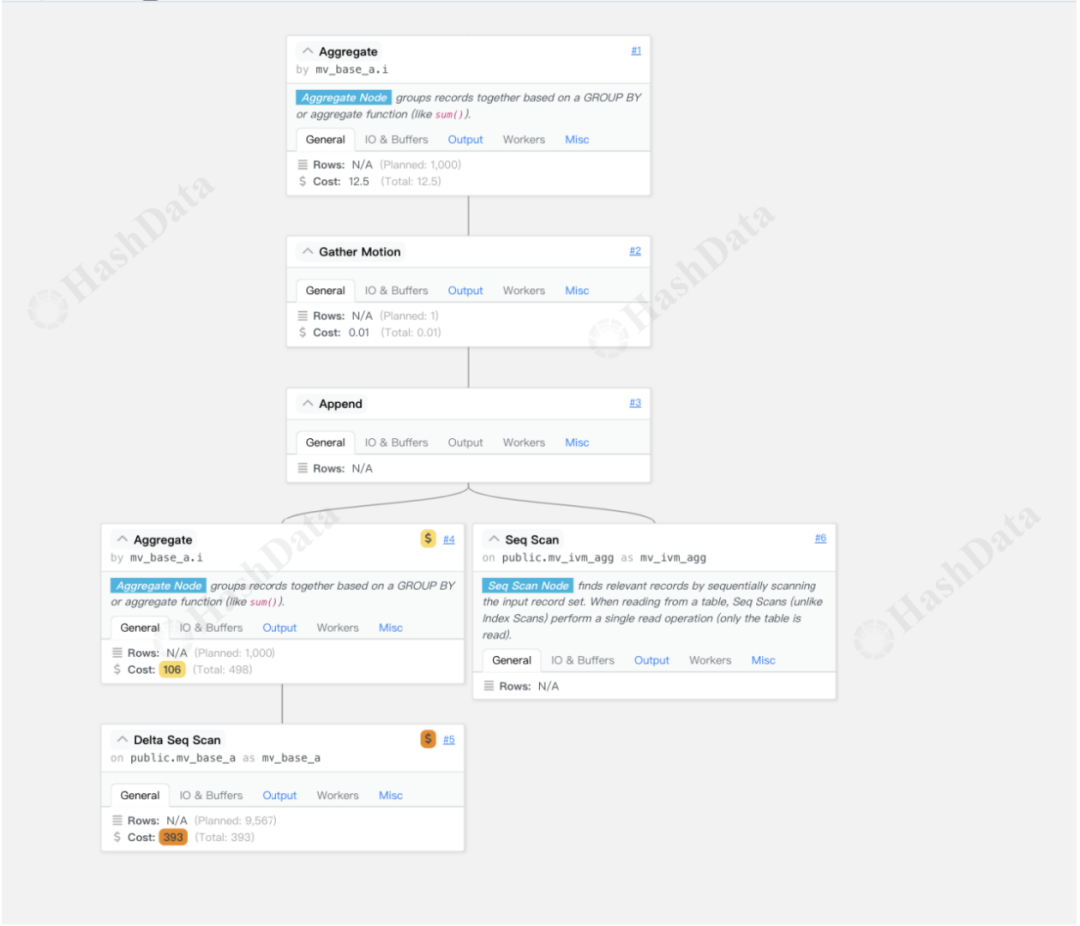
图7 Delta 执行计划
总结
需要强调的是,CloudberryDB当前版本的增量物化视图(IVM)功能仍存在一定的限制,例如它不支持某些特定函数、复杂查询(例如公用表表达式CTE、子查询、窗口函数)、特定类型的连接(如左连接、外连接)以及分区表。我们期待能与CloudberryDB开源社区共同努力,不断完善这一功能,共同推动数据库技术的发展,相信在未来的版本中,这些限制将得到有效的解决和改进。











