




在现代应用程序中,读写操作的需求往往是截然不同的。为了应对这些差异,CQRS
(Command Query Responsibility Segregation,命令查询职责分离), 逐渐成为一种广泛使用的架构模式。它通过将读操作和写操作进行分离,解决了传统架构下的一些常见问题,尤其在性能和可扩展性方面优势显著。
什么是 CQRS?
CQRS 的核心思想是:将处理“命令”(Command)与处理“查询”(Query)的职责分离开来。在传统的单体应用中,我们的服务往往既负责处理用户的写入请求(如修改数据),也负责处理读取请求(如展示数据)。这种模式简单且直观,但随着业务复杂度的增加,容易产生以下问题:
• 读写需求不匹配:读操作和写操作的性能需求不同,写操作通常涉及事务管理和一致性保证,而读操作则需要更快速和高效的响应。
• 数据模型复杂化:为同时支持读写操作,往往需要设计复杂的数据库结构,而这些结构可能并不能很好地服务于两者。
• 性能瓶颈:随着系统规模增长,既要处理大量并发写操作,又要保证实时数据查询的效率,容易导致瓶颈。
CQRS 是如何解决这些问题的?
CQRS 架构将系统中的写操作和读操作分为两个独立的职责模块:
1. Command(命令)模型:负责处理写操作。每个命令都是对系统状态的一次变更,它遵循操作性的一致性(如事务性),以保证数据写入的正确性。
2. Query(查询)模型:负责处理读操作。这个模型专注于快速、高效地返回数据,不涉及修改操作。它的核心目标是优化查询性能,因此可以根据不同的业务场景,使用不同的数据模型、索引或缓存策略。
这种职责分离使得我们可以针对不同的需求进行优化。例如:
• 写入系统可以优化事务处理、数据校验等功能,保障数据一致性和安全性。
• 读取系统可以专注于缓存、分片、索引等优化策略,最大限度提高响应速度。
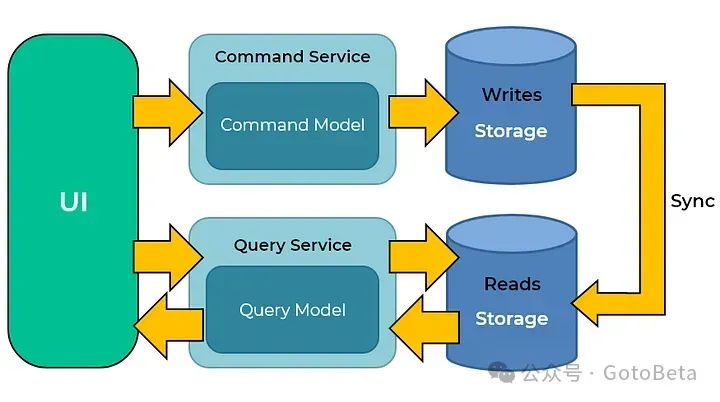
图:CQRS 体系下的读写分离架构
CQRS 的优势
1. 性能提升
由于读取和写入操作分离,开发者可以针对两者的不同特性进行优化。例如,写操作可能需要较重的事务管理,而读操作则可以利用缓存或异步处理来提升速度。
2. 更简单的模型
写入和读取使用不同的数据模型,开发者无需为兼顾两者而设计复杂的数据库表结构。这样不仅提高了设计的清晰度,还能使代码更加简洁易维护。
3. 扩展性更强
由于读和写被解耦,系统可以根据负载分别扩展。例如,如果系统中的读请求远多于写请求,可以独立扩展查询服务,而不需要同时扩展写服务,减少资源浪费。
4. 增强的安全性
CQRS 提供了更精细的权限控制。我们可以确保命令(写操作)部分仅允许授权用户访问,而查询(读操作)部分可以相对开放,甚至使用缓存或异步队列来处理。
CQRS 的挑战
当然,CQRS 并非没有挑战。引入 CQRS 意味着系统架构的复杂度增加,开发和运维团队需要更细致的设计和测试:
1. 复杂性增加
在传统架构中,读写是通过单一数据模型处理的,而在 CQRS 中,读写分别使用不同的数据模型和服务。这意味着我们需要为写操作和读操作分别设计、实现和维护两套逻辑。
2. 事件同步
CQRS 通常与**事件溯源(Event Sourcing)**结合使用,写操作的变更会通过事件驱动的方式同步到读操作模型。这种模式虽然提升了灵活性,但同时也引入了数据一致性的问题,开发者需要仔细设计事件的传播和处理流程。
3. 事件最终一致性
在 CQRS 架构中,由于写操作和读操作在不同系统中进行,数据同步往往是异步的。因此,我们需要接受一种“最终一致性”的概念,即系统中的数据可能在短时间内不同步,但最终会达到一致状态。这种不即时一致的设计需要在业务层进行合理的应对。
CQRS 的典型应用场景
虽然 CQRS 听起来很有吸引力,但它并非适用于所有项目。它特别适合以下场景:
1. 高并发系统:在需要处理大量读写请求的系统中,CQRS 可以很好地分担负载,避免读写冲突。
2. 复杂的查询需求:如果系统的读取需求非常复杂(如需要聚合大量数据、计算复杂的统计信息等),使用 CQRS 可以根据读取需求优化查询模型。
3. 领域驱动设计(DDD):CQRS 是 DDD(领域驱动设计)的一部分,它与事件溯源等技术结合,可以很好地管理复杂的业务逻辑和状态变更。
4. 微服务架构:CQRS 非常适合微服务架构。不同的微服务可以独立处理读写操作,各自优化自己的服务逻辑。
总结
CQRS 通过读写分离的设计,为现代高并发、高性能的系统架构提供了一种极具吸引力的解决方案。尽管它增加了系统的复杂度,但在特定的场景下,它能够显著提升系统的性能、扩展性和维护性。
在实际项目中,我们应根据具体的业务需求评估是否采用 CQRS。如果系统需要处理大量的读写请求,或存在复杂的查询逻辑,CQRS 将是一个强大的工具。希望本文能帮助你更好地理解 CQRS,并在实际项目中灵活运用!
