




本期内容如下:
- PG发布注记增强
- PG文档搜索增强
- 客户端插入表情符
- openGauss分区边界案例
PG发布注记增强
9月26日PG 17正式发布时,在我微信群发了一个感慨:
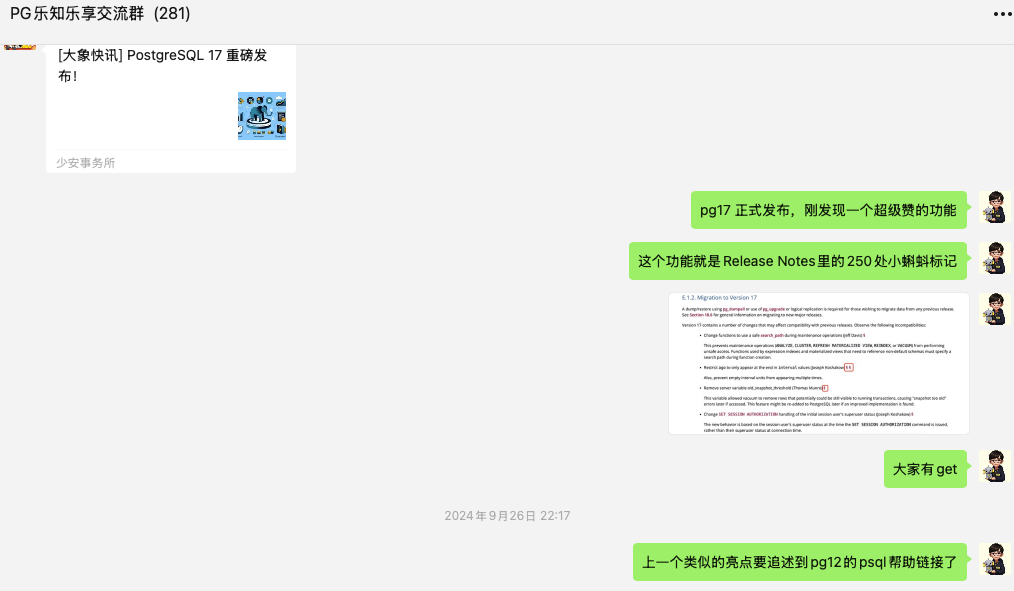
虽然不是什么大的特性,但能从这两百多处链接直获取一些宝贵的信息。
最近看到一篇文章: Enhanced Postgres Release Notes 也在描述这个感慨,知音难觅,于是摘录分享给大家。
PG全球开发组一直使用git来跟踪项目特性的提交,从17开始每条发布注记后面都有相应的单条或多条git提交链接。

点击发布注记后面的§符号,即可打开git链接如下:包括开发者的特性讨论及完整提交过程。
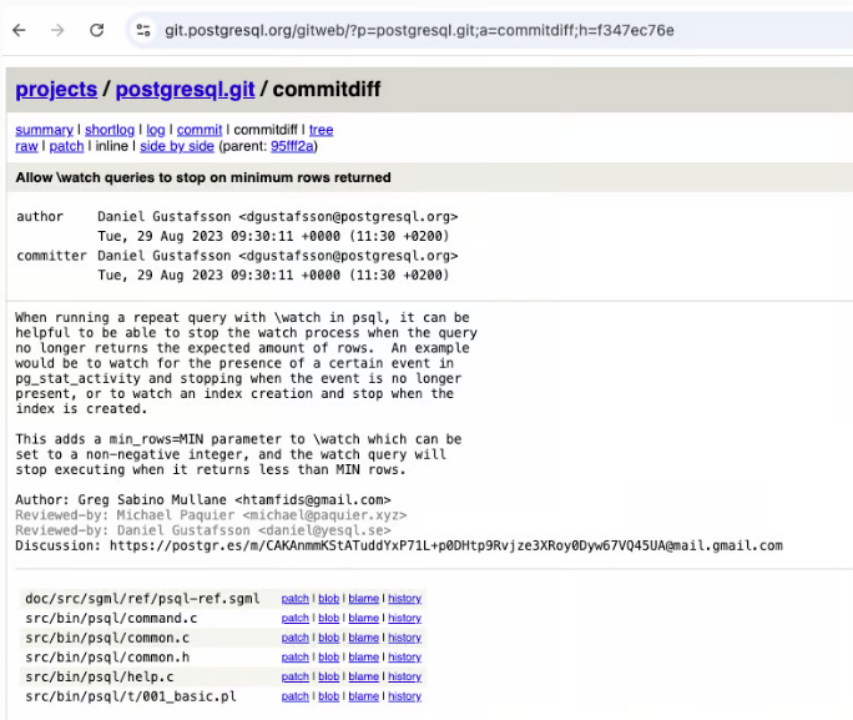
注记的编写并不是一件容易的事,即要兼顾不同提交者的声音,又要对所有的变化保持简明扼要及张弛有度。
可对于新特性重度爱好者,注记内容的详实度级别是不够的,而这些新增的链接对他们如获至宝。
通过链接他们不仅可以详细了解特性的源码实现,还能通过一些注释加深理解,更多注记里没有的细节都能映入眼帘。
感谢PG社区提升的这一品质,不仅联结了大版本变化的实现细节,也联结了特性提交者,让更多关注的人参与发现bug,互惠互利。
PG文档搜索增强
最近关注到一个网站:pgdoc.link 从名称也可了解其定位,可根据关键字快速搜索直接定位至PG文档的子页面,而且非常精准。包括一些常见的工具程序、SQL命令、配置参数、extension模块、开发函数、系统视图等。
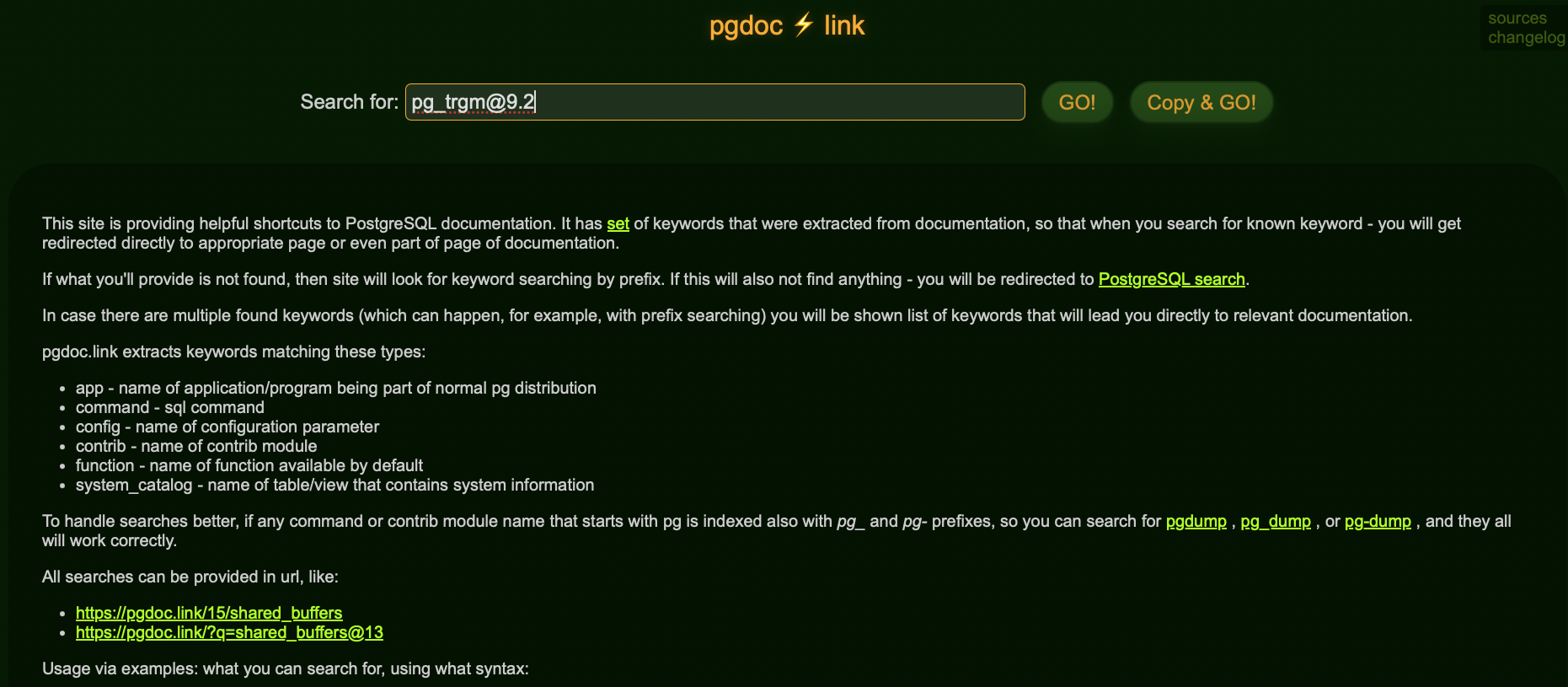
支持带版本号限定搜索,且搜索框下面有搜索指引:
- shared_buffers
Documentation for shared_buffers config parameter in “current” (17) version - 13/shared_buffe
Documentation for shared_buffers (prefix matching) config parameter in version 13 - jit@14
Documentation for jit config parameter (prefix matching knows more jit* variables, but this one matches perfectly) in version 14 - jit*
List of all known keywords that start with jit for “current” (17) version - pg_dump@11
Manual for pg_dump program in version 11 - 12/pgdump
Manual for pg_dump program in version 12 - pg-dump
Manual for pg_dump program in “current” (17) version - xactage*
Looks for any keywords that contain xact, and (later) age.
PG客户端如何插入emoji表情符
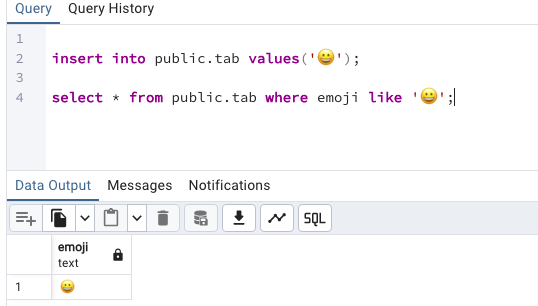
使用官方的pgadmin4可以直接复制表情符或输入unicode码进行表情符的写入或查询
查询窗口使用示例如下:
insert into public.tab values('😀');
select * from public.tab where emoji like '😀';
截图如下:
通过pgadmin4唤起psql也支持表情符的写入或查询
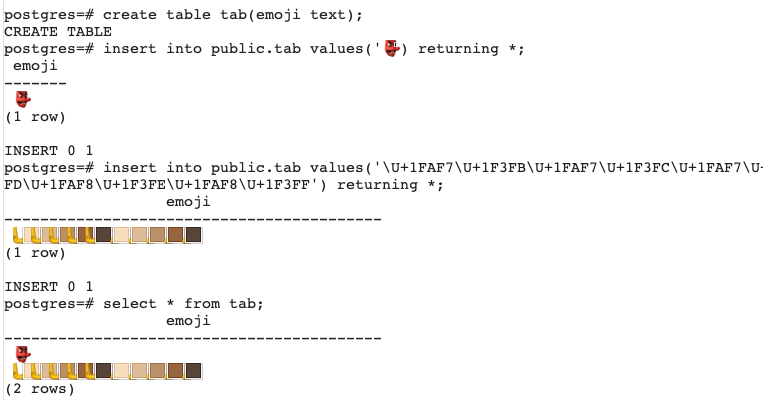
直接复制表情符或者按unicode码两种方式都支持
insert into public.tab values('🫷🏻🫷🏼🫷🏽🫷🏾🫷🏿🫸🏻🫸🏼🫸🏽🫸🏾🫸🏿') returning *;
insert into public.tab values('\U+1FAF7\U+1F3FB\U+1FAF7\U+1F3FC\U+1FAF7\U+1F3FD\U+1FAF7\U+1F3FE\U+1FAF7\U+1F3FF\U+1FAF8\U+1F3FB\U+1FAF8\U+1F3FC\U+1FAF8\U+1F3FD\U+1FAF8\U+1F3FE\U+1FAF8\U+1F3FF') returning *;
openGauss分区边界案例
在openGauss里使用如下语句创建分区表,业务期望设置10月和11月两个分区
CREATE TABLE test(
id bigserial PRIMARY KEY,
uid varchar,
create_time timestamp(0) NOT NULL
) PARTITION BY RANGE (create_time) (
PARTITION P2410 START ('2024-10-01 00:00:00') END ('2024-11-01 00:00:00'),
PARTITION P2411 START ('2024-11-01 00:00:00') END ('2024-12-01 00:00:00')
);
不过查看分区表详情,发现分区名称发生了一些变化
select relname,parttype,parentid,boundaries
from pg_partition
where parentid in(select oid from pg_class where relname='test');
relname | parttype | parentid | boundaries
---------+----------+----------+----------------------------
test | r | 27304 |
p2410_0 | p | 27304 | {"2024-10-01 00:00:00+08"}
p2410_1 | p | 27304 | {"2024-11-01 00:00:00+08"}
p2411 | p | 27304 | {"2024-12-01 00:00:00+08"}
(4 rows)
系统自动帮我们生成了10月之前的上边界分区,同时利用了10月的分区名称,10月之前的上边界分区名称为p2410_0,10月的分区名称为p2410_1,11月的分区名称保持不变。
此时如果我们直接按p2410分区名查询数据会遇到分区不存在的报错
postgres=# SELECT * from test partition (p2410);
ERROR: partition "p2410" of relation "test" does not exist
为了避免系统的这种默认行为,创建分区时,我们应该提前设计上边界分区,上面的建表语句可修改为:
CREATE TABLE test(
id bigserial PRIMARY KEY,
uid varchar,
create_time timestamp(0) NOT NULL
) PARTITION BY RANGE (create_time) (
PARTITION p_min END ('2024-10-01 00:00:00'),
PARTITION p2410 START ('2024-10-01 00:00:00') END ('2024-11-01 00:00:00'),
PARTITION p2411 START ('2024-11-01 00:00:00') END ('2024-12-01 00:00:00')
);
再次查看分区表详情,符合预期
select relname,parttype,parentid,boundaries
from pg_partition
where parentid in(select oid from pg_class where relname='test');
relname | parttype | parentid | boundaries
---------+----------+----------+----------------------------
test | r | 19075 |
p_min | p | 19075 | {"2024-10-01 00:00:00"}
p2410 | p | 19075 | {"2024-11-01 00:00:00"}
p2411 | p | 19075 | {"2024-12-01 00:00:00"}
(4 rows)
本文结束~
往期回顾
- 数据库微观案例第51期
- 数据库微观案例第50期
- 数据库微观案例第49期
- 数据库微观案例第48期
- 数据库微观案例第47期
- 数据库微观案例第46期
- 数据库微观案例第45期
- 数据库微观案例第44期
- 数据库微观案例第43期
- 数据库微观案例第42期
- 数据库微观案例第41期 |NULL值案例
- 数据库微观案例第40期
- PostgreSQL智慧碎片|微观案例 |宏观收获
- PostgreSQL小案例集|4月刊
与我联系
- 微信公众号:象楚之行
- 墨天轮:https://www.modb.pro/u/15675
- 微信:skypkmoon
勤耕细作,用心积微;静待花开,量变质成。
