




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
flink背压过高产生的原因
短时间的负载高峰导致系统接收数据的速率远高于它处理数据的速率。一个flink任务由多个oprators组成,由于flink的机制,无论哪个环节出现了问题,最终都会反压导致source的背压变高。
flink背压过高的危害
系统性能下降 背压导致数据阻塞,进而造成系统吞吐量降低和延迟增大,影响整体处理效率。 内存压力增大 大量未处理的数据会堆积在网络层或内存中,占用计算节点的内存资源,可能导致内存溢出。 系统稳定性下降 严重的背压可能导致任务执行过程中节点由于内存溢出等问题而崩溃,进而影响任务的正常运行。 影响Checkpoint机制 背压可能导致Checkpoint超时失败,进而影响状态数据的保存和恢复。 影响数据一致性 如果上游是Kafka数据源,在一致性的要求下,背压可能导致offset提交不上,进而影响数据的一致性。
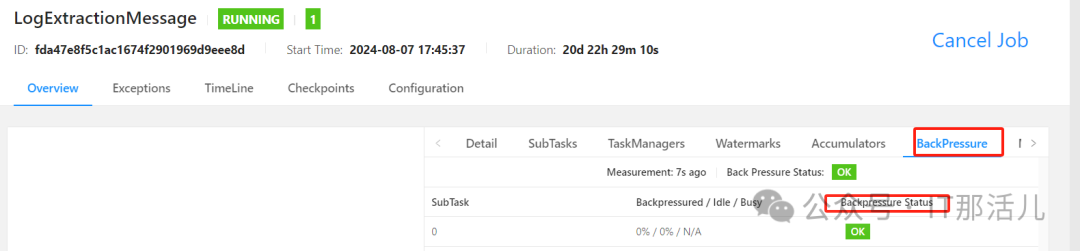
flink背压过高定位
通过颜色和数值来展示繁忙和压力的程度; 通过UI进入jobs查看SubTask的Records Sent 和 Record Received 项确认是否存在数据倾斜,存在倾斜也会导致背压过高问题; 再通过BackPressure确认是否背压过高,过高状态为“HIGH”,该方式可快速确定是否存在背压高的情况。
top -H -p pid
本文作者:曹安匀(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
