摘要
本文提出了一种名为 CoAct 的多 Agent 协作框架,它将人类社会的层级规划和协作机制融入到大型语言模型(LLM)中,以提升其推理能力。
CoAct 框架由两个核心组件构成:
- 全局规划智能体,它的任务是把握问题的全局视角,制定总体策略,并为局部执行智能体提供具体的子任务指导;
- 局部执行智能体,它在多级任务执行框架中工作,专注于精确执行全局规划中的特定任务。
在 WebArena 网络环境中,CoAct 的表现超越了 ReAct。并且 CoAct 在 WebArena 的各种网络环境中均是有效的。
核心内容
1. 整体框架
CoAct 是一个基于 LLM 的多代理系统,专为不同代理之间的分层协作而设计。下图显示了该框架,其中包括分解任务、分配和传达子任务、分析和执行子任务、收集反馈、评估进度以及必要时重新规划等操作。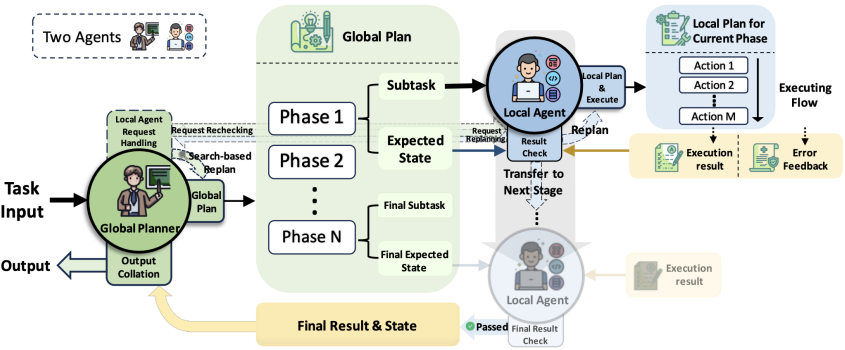
2. Global Planning Agent
它负责制定详尽的计划,并将这些计划分解成一系列具有明确目标的阶段性子任务。该智能体负责监督整个计划的执行,确保每个阶段的目标都清晰无误。当局部执行智能体提供反馈时,全局规划智能体会进行评估,并在必要时提出调整建议,以指导和优化执行过程。它维护计划的连贯性,并在需要时进行整合或修改,以确保最终结果与最初的策略保持一致。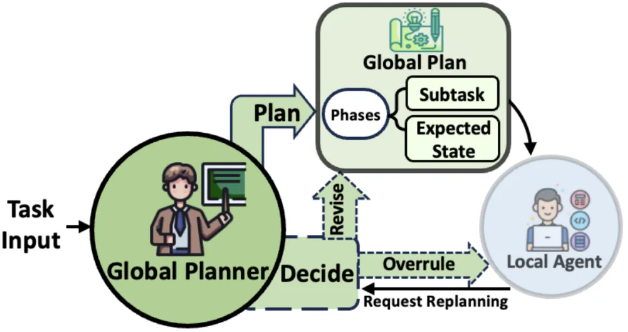 提示词:
提示词:

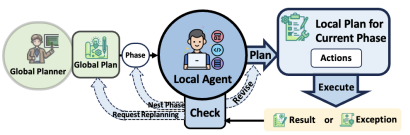
3. Local Execution Agent
微观执行智能体致力于执行宏观规划智能体制定的具体任务。
它负责任务的实施、网络浏览,并确保每一步都与整体战略保持一致。该智能体细致地分析每项子任务,按顺序执行操作,并对照宏观计划进行验证。它根据收集到的反馈来评估任务的进展,并决定是否需要请求宏观规划智能体对计划进行调整,或是继续执行后续步骤。
此外,它提供的详尽的执行结果反馈对于确保与宏观目标的一致性以及整合操作和结果至关重要。
 提示词:
提示词:

实验
在我们的研究中,我们以WebArena论文中使用的ReAct模型作为比较基准。对于我们的方法,我们提出了CoAct w/ FS这一改良版本,其中"FS"代表强制停止机制,意味着当对话轮次达到预设的上限时,系统将自动结束对话。下表展示了ReAct与我们提出的CoAct框架在WebArena基准测试中的对比数据。结果显示,CoAct相较于ReAct在性能上提升了超过40%,在需要强制中断干预的情况下,提升幅度更是达到了70%。此外,CoAct在所有五个测试任务中均优于ReAct,这证明了CoAct在处理实际任务时的高效性和适应性。 在标准的ReAct配置中,代理遵循一系列步骤:首先,确定合适的子类别;其次,定位到正确的类别;然后,根据价格对选定类别内的产品进行排序;最后,分批次浏览页面以定位目标商品。然而,当任务不符合预设的类别时,ReAct处理起来会遇到困难。这是因为代理在类别搜索过程中积累了过多的上下文信息,这阻碍了模型在失败后识别出需要跳出类别搜索流程的信号。
在标准的ReAct配置中,代理遵循一系列步骤:首先,确定合适的子类别;其次,定位到正确的类别;然后,根据价格对选定类别内的产品进行排序;最后,分批次浏览页面以定位目标商品。然而,当任务不符合预设的类别时,ReAct处理起来会遇到困难。这是因为代理在类别搜索过程中积累了过多的上下文信息,这阻碍了模型在失败后识别出需要跳出类别搜索流程的信号。 在CoAct中,全局规划代理会在宏观层面上将任务执行过程分解成多个阶段,并将各个子任务分配给本地执行代理。即使积累了上下文信息,与子任务描述相关联的提示也能在规划出现错误时引导重新定向。本地执行代理可以请求对全局计划进行调整,实现宏观层面的重新规划。因此,CoAct和ReAct的核心区别在于对上下文的分割、注意力的分配以及内存的管理。CoAct更加明确和灵活,普遍适用于解决跨类别的实际任务。
在CoAct中,全局规划代理会在宏观层面上将任务执行过程分解成多个阶段,并将各个子任务分配给本地执行代理。即使积累了上下文信息,与子任务描述相关联的提示也能在规划出现错误时引导重新定向。本地执行代理可以请求对全局计划进行调整,实现宏观层面的重新规划。因此,CoAct和ReAct的核心区别在于对上下文的分割、注意力的分配以及内存的管理。CoAct更加明确和灵活,普遍适用于解决跨类别的实际任务。总结
CoAct 框架,由宏观规划智能体和微观执行智能体构成,旨在将人类社会的层级规划与合作策略引入大型语言模型(LLM)的应用之中。实验证明,CoAct 框架不仅能够在遇到失败时重新规划执行路径,而且在处理长文本网络任务方面,其表现也超越了ReAct框架。







