




0 前言
使用机器学习的方法对云数据库进行参数调优具有较大的潜力,但是面对个性化的需求,预训练模型会出现无法匹配的问题,若使用在线学习的方法,则可能导致冷启动问题,导致较长的训练时间和性能波动。针对这些不足,本文带来SIGMOD的论文:HUNTER: An Online Cloud Database Hybrid Tuning System for Personalized Requirements,介绍一种针对个性需求在线云数据库的调优方法。
1 HUNTER
HUNTER的模型架构如下图所示,主要分为两个部分:controller和hybrid tuning system。controller模块和用户、数据库系统和tuning system进行交互,可进一步分为actors和CDBs两个子模块,CDBs中是从云端复制的用户实例,actors收集数据库系统的运行信息并管理CDBs上的并发执行。hybrid tuning system包括一个shared pool和三个模块,分别是sample factory(第2节内容),search space optimizer(第3节内容)和recommender(第4节内容)。sample factory用来生成高质量的样本避免冷启动问题,search space用来降维提高效率,recommender生成最后的推荐参数。
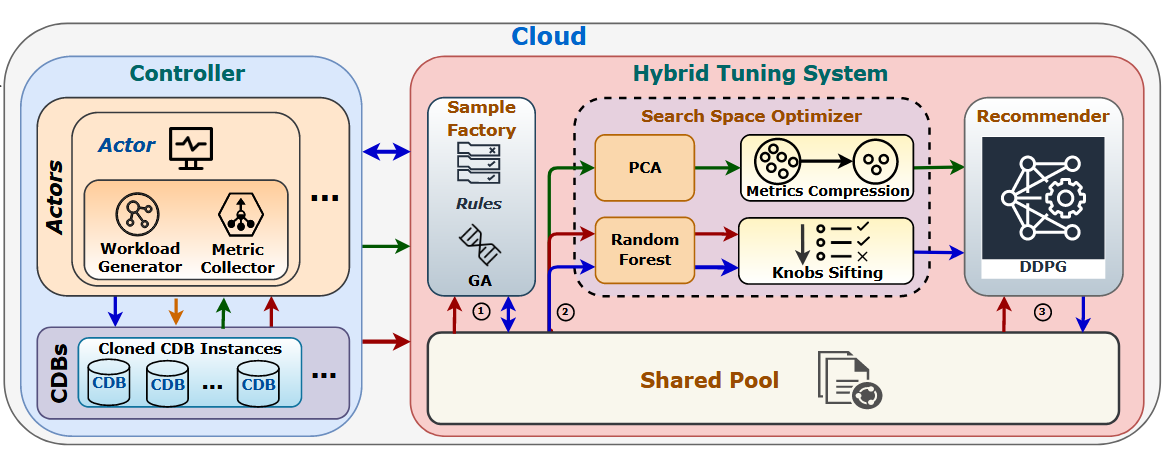
HUNTER的运行流程如下:
1、用户输入查询、规则、预算等信息;
2、actors生成随机配置参数,在CDBs上进行压力测试,每个压力测试后生成样本对(S,A,P),S为评价参数,A和P是一组旋钮配置参数及其性能。然后将这些信息放到shared pool中,sample factory基于这些样本进行增强,这个过程一直迭代直到样本数量达到预期或在很长一段时间内性能没有改善;
3、search space optimizer基于shared pool中的样本进行搜索空间优化,包括metric compression和knobs sifting两个部分;
4、recommender使用强化学习模型生成新的配置参数,在给定的时间预算中选择最好的那组。
2 Sample Factory
sample factory的主要作用是基于随机生成的样本对进行数据扩充,让数据中包含更泛化的特征让模型去学习。sample factory基于规则和遗传算法生成更多的样本,规则是用户自定义的信息,遗传算法基于这些规则生成高质量的样本。
为什么需要高质量的样本?高质量样本可以帮克服冷启动问题。现有方法基于try-and-error的策略,使用随机采样或超拉丁立方进行样本采样,然而,若采样的样本中不包含较高质量的样本,模型基于这些样本进行学习也无法获得较优的参数推荐,因此,研究如何生成高质量的样本是必要的。
遗传算法是一种自组织、自适应的算法,通过模拟生物进化的过程来进行演进,包括进化、突变、自然选择、杂交。其算法流程如下:
1、初始化:用随机生成的样本构成初始种群POP={$K_1,K_2,…K_n$},其中$K_i$为种群中的一个个体,$K_i=${$K1,K2,…K^m$}表示要被调整的$m$个旋钮;
2、适应度函数:评价每个个体的适应度,本文将吞吐量和延迟加入到适应度函数中,公式如下所示:
$$
f\left(K_{i}\right)=\alpha \frac{T_{\text {cur }}-T_{\text {def }}}{T_{\text {def }}}+(1-\alpha) \frac{L_{\text {def }}-L_{\text {cur }}}{L_{\text {def }}}
$$
3、选择策略:种群中具有更高适应度的个体应该具有更大的概率被选中,其概率公式如下:
$$
p_{i}=\frac{f\left(K_{i}\right)}{\sum_{j=1}^{n} f\left(K_{j}\right)}
$$
4、杂交策略:选择$K_i$和$K_j$生成一个新的个体,选择两个个体中的片段构成一个新的旋钮配置;
5、基因突变策略:加入一些随机性更好地探索配置空间,旋钮配置中每个元素都有$\beta$的概率突变。
3 Search Space Optimizer
除了样本质量,高维带来的巨大搜索空间是影响模型性能的另一个重要因素。为了降低搜索空间,本文分别使用主成分分析(Principle Component Analysis,PCA)和随机深林(Random Forest,RF)进行metrics compression和knobs sifting。
3.1 Metric Compression
PCA是机器学习中的一种降维方法,它保留高维度的数据中最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。
假设原始的数据$X$的维度为$R^{u\times l}$,其中$u$是metric的维度,$l$是metric的个数,PCA通过矩阵$P$将$X$降维为$Z$,$Z$的维度为$R^{v\times l}$,$v$表示降维后的metric维度,降维公式如下所示:
$$
Z = PX
$$
$P$中包含了协方差矩阵$XX^T$中前$v$个特征值最大的特征向量,通过$P$可以将维度为$u$的特征投影到正交空间中,正交空间中的第一个坐标轴是原始数据中方差最大的方向,第二个坐标轴是与第一个正交的平面中方差最大的方向,依次类推,得到$k$个方向,而后面的方向中方差为0,因此可以忽略。总结来说,PCA是在原来数据的$n$维特征上构造$v$维特征,这$v$维特征是全新的正交特征,是包含最大差异性的主成分。
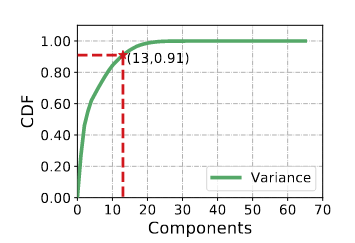
如下图所示,将原始的维度进行主成分分析,将维度降维至13维,CDF达到91%。
3.2 konbs shifting
通常来说,根据以下两个原则设置旋钮:一是DBA的建议,二是运行结果。本文使用随机深林(RF)从运行结果中捕获重要特征。随机森林是一种有监督的机器学习算法,可以被用来处理分类和回归问题,采用多棵决策树进行投票来选择重要的特征。
本文中,采用CART树来构建决策树,构建的深林中包含200棵树,每一棵树都是一个分类器来对旋钮的重要性进行投票,然后采用投票最多者优先的原则。每一棵决策树的构建就是一个训练的过程。假设要调参的旋钮个数为$n$,共$m$个样本,构成了一个$R^{m\times n}$的空间,从这个空间中构建一个子集$C\in R^{g\times n}$,$g$是在$m$中的随机采样,然后用$C$去训练CART树,每棵CART树的训练数据$C$都是独立且不同的。基于$C$,CART从根节点基于Gini系数来选择最好的旋钮来递归构造树。在每棵CART树中,计算出每个旋钮的Gini系数,200棵树中旋钮的平均Gini系数表代表了最终的重要性程度。
实验结果如下图所示:
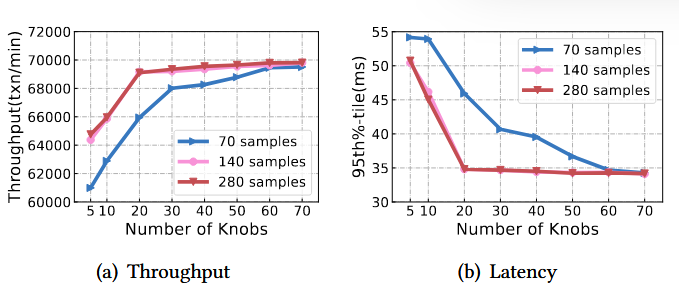
由图a和图b可知,样本数量在140和280时性能曲线基本没有区别,且调优前20个旋钮和调优全部的旋钮性能相当,因此,本文选择使用140个样本,在前20个旋钮上进行调优。
4 Recommender
DDPG(Deep Determine Policy Gradient)算法在调优前期没有取得较好的性能,但在后期展现出最好的性能上限,因此,在经过metric compression和knobs sifting后仍是选择DDPG算法进行最终的调优。
DDPG是一个actor-critic模型,将整个模型分成以下6个部分:
Agent:agent根据reward和state来制定policy,从而推荐action,使得下一次的reward最大化;
Environment:即CDB,在具体实现中,使用controller来管理CDBs;
State:使用PCA降维后的主要性能指标;
Action:推荐的前k个旋钮参数配置;
Reward:action导致的性能和模型默认性能比较;
Policy:agent的模型参数,将state映射到action,它由reward来训练,目标是让reward最大化。
在DDPG模型中,包含了两个神经网络DDPG-actor网络和DDPG-critic网络。DDPG-actor网络将state映射到action,DDPG-critic则用来评价DDPG-actor和reward的性能。
前面提到,DDPG模型前期较难收敛,本文提出了一种Fast Exploration策略,在实现中,根据以下方法来选择action:
$$
A={A_c, A_{best} }
$$
其中,$A_c$是DDPG-actor生成的action,$A_{best}$是当前最好的性能参数配置加上一个随机变量。本文使用$P(A_c)$和$P(A_{best})$来分别代表选择$A_c$和$A_{best}$的概率,其计算公式如下所示:
$$
P(A_c) + P(A_{best}) = 1 \tag{5}
$$
$$
\lim_{t \to \infty}P(A_c) = 1 \tag{6}
$$
$$
\frac{dP(A_c)}{dt} >0\tag{7}
$$
其中,$t$表示迭代的次数,从以上的公式中看出,初始时根据经验选择性能较好的action,随着模型训练,逐渐信任DDPG-actor生成的action。经实验,当$t$=0时,取$P(A_c)=0.3$取得较好的性能。
