




背景
OSS 冷数据并行查询
OSS冷数据并行查询技术,则是通过并发查询执行模型,即增加并发查询线程或任务的数量,来并行处理大规模数据集。此方法充分利用了现代计算资源的多核特性,实现了查询负载在多个处理单元间的均衡分配,极大缩短了查询响应时间。特别是针对数据量庞大的冷数据查询场景,该技术能够有效克服单线程处理的瓶颈,确保查询操作的高效执行与资源的最大化利用。
OSS 冷数据并行查询也是一种查询加速的方法,可以不依赖 OSS FILE FILTER 统计信息,通过增加并行度来提升查询速度。提升的效果和并行查询的并行度正相关。需要注意的是,一个并行查询线程需要 128MB 内存,在实际过程中需要留意实例内存余量。以下介绍如何使用并行查询OSS冷数据。
使用方法
- 在控制台调大参数 loose_csv_max_oss_threads。这个参数表示一个节点可以并行执行的OSS线程数量,默认是1。
- 开启并行查询功能
可以通过多种方法开启并行查询。这里仍以lineitem为例,通过hint开启并行查询后,执行计划上会显示Parallel scan标记。
mysql> explain SELECT /*+ PARALLEL(4) */
-> sum(l_extendedprice * l_discount) AS revenue
-> FROM
-> lineitem
-> WHERE
-> l_shipdate >= date '1994-01-01'
-> AND l_shipdate < date '1994-01-01' + interval '1' year
-> AND l_discount between 0.05 - 0.01 AND 0.05 + 0.01
-> AND l_quantity < 24;
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
| 1 | SIMPLE | <gather1.1> | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | lineitem | NULL | ALL | NULL | NULL | NULL | NULL | 15390122 | 0.41 | Parallel scan (4 workers); Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
2 rows in set, 1 warning (2.17 sec)如果有多个节点,也可以开启ePQ,进一步提升查询性能。开启ePQ后,查询计划会显示有几个节点,总并行度为多少:
mysql> explain SELECT /*+ PARALLEL(4) */
-> sum(l_extendedprice * l_discount) AS revenue
-> FROM
-> lineitem
-> WHERE
-> l_shipdate >= date '1994-01-01'
-> AND l_shipdate < date '1994-01-01' + interval '1' year
-> AND l_discount between 0.05 - 0.01 AND 0.05 + 0.01
-> AND l_quantity < 24;
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
| 1 | SIMPLE | <gather1.1> | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | SIMPLE | lineitem | NULL | ALL | NULL | NULL | NULL | NULL | 59986051 | 0.41 | Parallel scan (8 workers); MPP (2 nodes); Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)性能测试
并行查询技术的核心机制在于通过多个线程并发地执行查询操作,从而提升查询效率。因此性能主要依赖并行度的大小。我们在 10GB 的TPCH数据集上测试Q6的性能,节点规格为32c128g,共有两个只读节点,测试结果如下图所示:
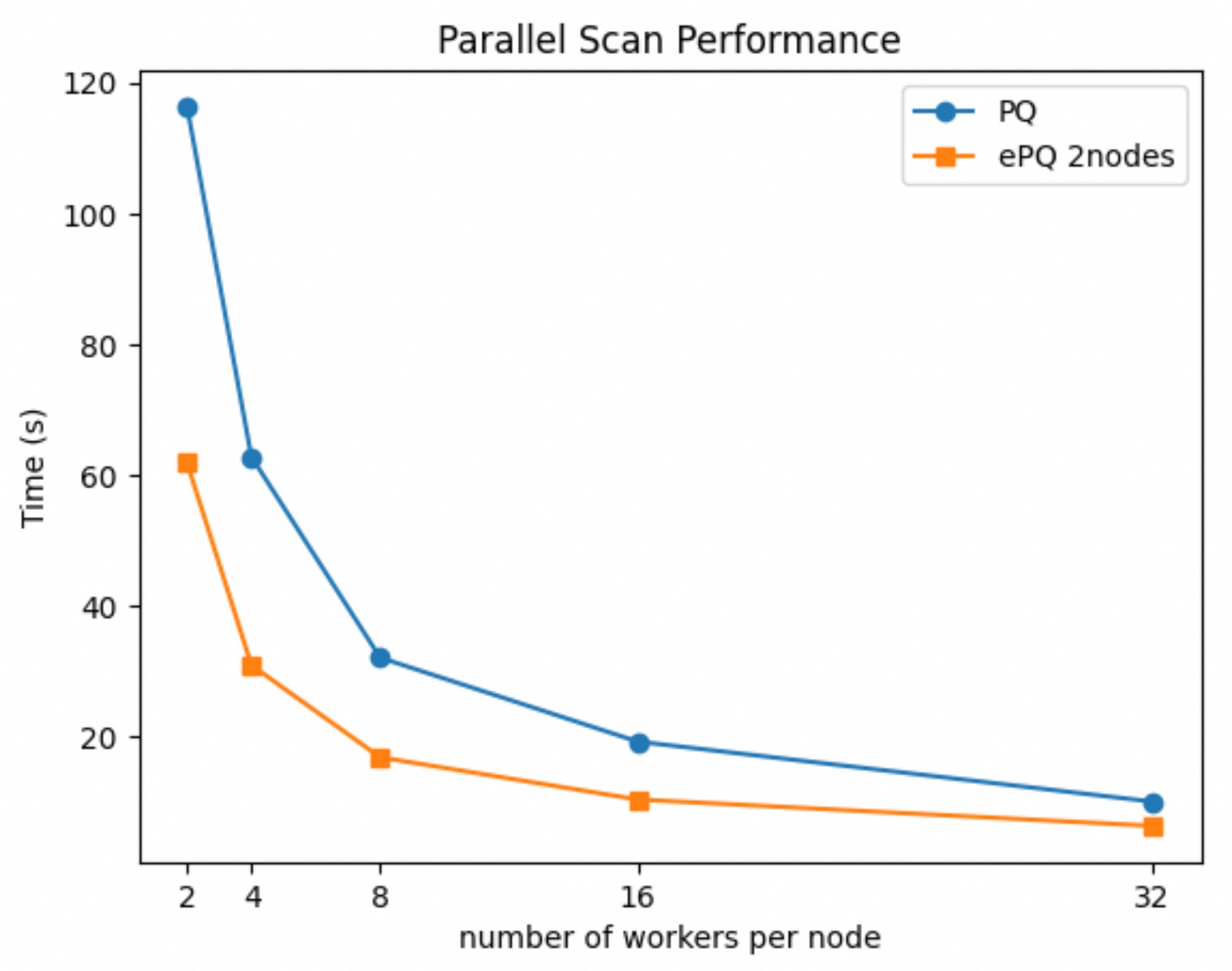
上图中的横坐标为单节点并行度,纵坐标为查询时间。ePQ场景下单节点并行度如果为2的话,由于测试实例的总节点数为2,所以总并行度为4。
可以看到,并行查询也能极大的加快查询速度,如果只是临时对某个冷存表有查询需求,开启并行查询也可以满足这一要求。
总结
PolarDB MySQL针对冷数据查询性能的优化策略聚焦于两点:OSS文件筛选与OSS冷数据并行查询技术。OSS文件筛选机制通过目标列的预筛选,有效过滤无关数据,极大提升了查询效率,而OSS冷数据并行查询技术,则是用户可以灵活地灵活调节并行度,结合ePQ多节点并行进一步缩减查询延迟。
