




1. 正则表达式作用
检查文本中是否含有指定的特征词
找出文中匹配特征词的位置
从文本中提取信息,比如:字符串的子串
修改文本
2. 正则表达式常用规则
表 1. 简单的转义字符
表达式 | 说明 | 例子 |
\r\n | 回车换行符 | |
\t | 制表符 | 代表Tab(0x09) |
\\ | 代表”\”本身 | "c:\\":表示"c:\" |
\^ | 代表^本身 | "x\^2":表示"x^2" |
\$ | 代表$本身 | "30\$":表示"30$ " |
表2. 代表抽象意义的特殊符号
抽象意义的符号本身不匹配任何字符,它要求匹配的位置。
表达式 | 说明 | 例子 |
^ | 从字符串头部进行匹配。要匹配"^" 字符本身,使用"\^" | "^[a-zA-Z]": 匹配以大小写字母开头的字符串 |
$ | 从字符串尾部进行匹配。要匹配"$" 字符本身,使用"\$" | "^.{3}$":三个任意字符结尾 |
\b | 匹配一个单词边界 | "\btest\b":只匹"test",不会匹配"tester" |
| | 左右两边表达式直接“或”的关系,匹配左边或者右边。匹配"|" 本身,使用"\|" | "IBM Notes│Lotus Notes": 匹配含有"IBM Notes" 或者 "Lotus Notes" 的字符串 |
() | (1)在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰(2)取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到。要匹配小括号,使用"\(" 和"\)" | "Inbox(\(\d+\))?":匹配"Inbox"或"Inbox(1) "或"Inbox(15) "等等; |
[] | 用来自定义能够匹配'多种字符' 的表达式。要匹配中括号,请使用"\[" 和"\]" | " [abc] ": 匹配a或b或c |
{} | 修饰匹配次数的符号。要匹配大括号,请使用"\{" 和"\}" | "ab{2,5}":要求a后面可以有2-5个b("abbb", "abbbb", or "abbbbb") |
. | 匹配除了换行符(\n)以外的任意一个字符。要匹配小数点本身,请使用"\." | "a.[0-9]":一个a加一个字符再加一个0到9的数字; " [\n.] ":包括\n在内的任意字符 |
? | 修饰匹配次数为0 次或1 次。要匹配"?" 字符本身,请使用"\?" | "ab?":和ab{0,1}同义,可以没有或者只有一个b("a","ab") |
+ | 修饰匹配次数为至少1 次。要匹配"+" 字符本身,请使用"\+" | "ab+":和ab{1,}同义,匹配以a开头,但最少要有一个b存在 ("ab", "abbb"等) |
* | 修饰匹配次数为0 次或任意次。要匹配"*" 字符本身,请使用"\*" | "ab*":和ab{0,}同义,匹配以a开头,后面可以接0个或者n个b组成的字符串("a", "ab", "abbb"等) |
表3. 匹配多种字符的特殊符号
表达式 | 说明 | 例子 |
\d | 匹配0~9中的任意一个数字,相当于[0-9] | "^\d{18}|\d{15}$":验证身份证号码 |
\D | 匹配所有的非数字字符,等价于[^0-9] | "\D+":匹配"IBM Notes 9.0"中的"IBM Notes" |
\w | 任意一个字母(A~Z,a~z)或任意一个数字(0~9)或下划线(_) | "\w+([-+.]\w+)*@\w+([-.]\w+)*.\w+([-.]\w+)*":匹配邮箱地址 |
\W | 匹配所有的字母、数字、下划线以外的字符 | "\W":匹配"50%"中的"%" |
\s | 匹配空白字符中的任意一个(包括空格,制表符,换页符等) | "\s\w*":匹配"IBMNotes"中的"Notes" |
\S | 匹配所有非空白字符 | "\S\w*":匹配"IBMNotes"中的"IBM" |
表4. 表示匹配次数的特殊符号
表达式 | 说明 | 例子 |
{n} | 表达式重复n次, | "a{5}":相当于"aaaaa" |
{m,n} | 表达式至少重复m次,最多重复n次 | "ba{1,3}":可以匹配"ba"或"baa"或"baaa" |
{m,} | 表达式至少重复m次 | "\w\d{2,}":可以匹配"a12", "_456","a12344"等等 |
3. Pattern和Matcher的应用
在频繁使用正则表达式的场合,可以用Pattern的complier方法对字符串进行剖析,验证,确定正则表达式语法无误,再对字符串进行匹配和比较,这样有助于提高效率。
Pattern p1 = Pattern.compile(".*<tr.*>TESTCASE RESULT:\\s*(\\w.*? )\\s*:\\s*([A-Z\\s]+?)<.*/tr>.*", Pattern.DOTALL) ;String matchString = "TESTCASE RESULT: testcase_gvt.teamroomx1.teamrm1: PASSED"String result = "";String name = "";Matcher m1 = p1.matcher(matchString);if(m1.find()){name = m1.group(1);result = m1.group(2);}
代码中的group是指里用括号括起来的,能被后面的表达式调用的正则表达式。
group 0 表示整个表达式
group 1表示第一个被括起来的group,以此类推。
A(B(C))D里面有三个group:group 0是ABCD, group 1是BC,group 2是C。
4. ASCII控制字符的匹配
\\p{Cntrl} 表示控制字符

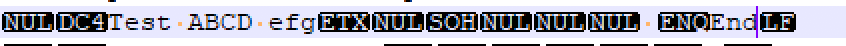
int[][] asciis = {{0,20}, {3, 0, 1, 0, 0, 0, 32, 5}};String matchedStr = ascii2String(asciis[0]) + "Test ABC efg" + ascii2String(asciis[1]) + "End\n";String pattern = "^\\p{Cntrl}{2}([A-Za-z\\s]+)(\\p{Cntrl}{1,})(\s\\p{Cntrl}End\n)$";Matcher keyMatcher = Pattern.compile(pattern).matcher(matchedStr);if (keyMatcher.find()) {System.out.println(keyMatcher.group(0));System.out.println(keyMatcher.group(1));System.out.println(str2Ascii(keyMatcher.group(2)));System.out.println(str2Ascii(keyMatcher.group(3)));}
group0: Test ABC efg Endgroup1: Test ABC efggroup2: [3, 0, 1, 0, 0, 0]group3: [32, 5, 69, 110, 100, 10]
