




在人工智能的广泛领域内,预训练的大型模型,例如BERT和GPT,已经在众多自然语言处理(NLP)任务中展现了非凡的能力。尽管如此,这些模型在特定应用或任务中的性能还有进一步的提升空间。针对这一挑战,监督式微调(Supervised Fine-Tuning,简称SFT)成为了一种提高模型性能的有效方法。本文将详细探讨SFT的定义、步骤以及其在增强模型性能方面的关键作用。
sft开源训练数据集:https://github.com/HqWu-HITCS/Awesome-Chinese-LLM/tree/main?tab=readme-ov-file#sft%E6%95%B0%E6%8D%AE%E9%9B%86
SFT基本概念
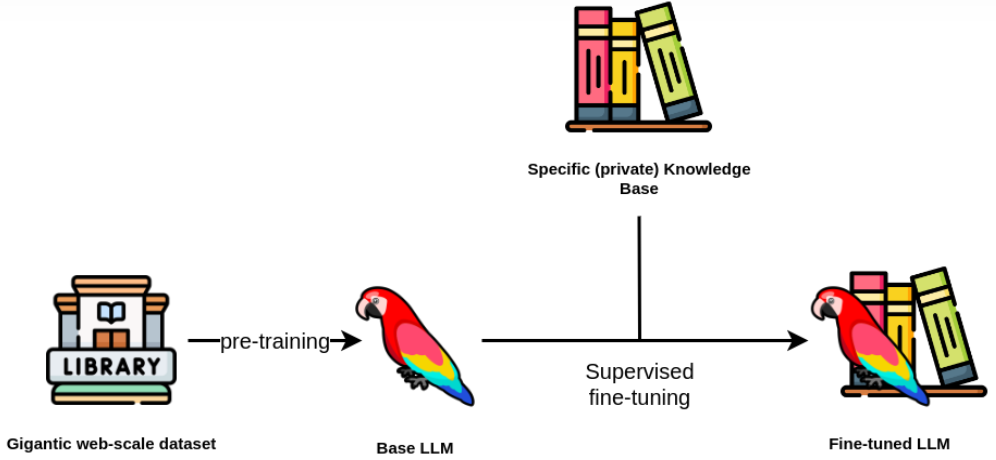
SFT操作流程
预训练模型的选取:选择一个适合特定任务的预训练模型,该模型应在大规模数据集上训练过,具备出色的语言处理能力。
数据的准备:收集并标记用于微调的数据,确保这些数据与目标任务高度相关,以便模型能够学习到任务特有的特征。
微调配置:在微调阶段,大部分模型参数将保持不变,只有少数参数(如输出层)会被调整。这样可以保持预训练模型的通用知识,同时吸收特定任务的知识。
模型训练:使用标记数据对模型进行训练。由于模型已经具备一定的基础能力,这一过程通常需要较少的数据和较短的时间。
性能评估与优化:训练完成后,对模型的性能进行评估,并根据评估结果进行优化,可能包括调整超参数或增加数据增强等策略。
SFT主要优势
快速适应新任务:微调使模型能够迅速适应新任务,无需从头开始训练。
数据效率:SFT通常需要较少的标记数据,这对于数据获取成本较高的领域尤为重要。
性能提升:在特定任务上,SFT可以显著提高模型的性能,尤其是在数据量有限的情况下。
灵活性:SFT可以灵活地应用于不同的模型和任务,具有很好的通用性。
SFT面临的挑战
数据质量:高质量的标记数据对SFT至关重要,数据中的噪声和偏差可能会影响模型的性能。
过拟合风险:在小数据集上进行微调时,模型可能会过拟合到训练数据,导致在未见数据上的性能下降。
计算资源需求:尽管SFT比从头开始训练模型需要的资源少,但在处理大型模型时仍需一定的计算能力。
常见的监督式微调技术
LoRA(Low-Rank Adaptation)
总结
总体而言,监督式微调(SFT)是一种强大的技术,它可以帮助我们在特定任务上提升预训练模型的性能。通过精心设计的训练流程和策略,SFT可以显著提高模型的准确性和效率。随着研究的深入,我们期待SFT在未来能够解决更多的挑战,并在更广泛的应用场景中发挥其潜力。

文章转载自AI 搜索引擎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
