




今天分享的是一篇由自孟加拉国工程技术大学、北德克萨斯大学和 Cohere For AI 社区等机构联合发布的文章:
Open-RAG:使用开源大型语言模型增强的检索增强推理

论文链接: https://arxiv.org/pdf/2410.01782
代码链接: https://openragmoe.github.io/
摘要
检索增强生成(RAG)已被证明能够提高大型语言模型(LLMs)的事实准确性,但现有方法在有效利用检索到的证据时,推理能力通常有限,特别是在使用开源LLMs的情况下。为了解决这一问题,OPEN-RAG将任意密集的LLM转化为一种参数高效的稀疏专家混合模型(MoE),从而使其能够处理复杂的推理任务,包括单跳和多跳查询。同时,OPEN-RAG通过训练模型有效应对那些看似相关但实际上可能误导的干扰项,动态选择相关专家并整合外部知识,以提供更准确和上下文相关的响应。此外,OPEN-RAG还提出了一种混合自适应检索方法,以确定检索的必要性,并在性能提升与推理速度之间找到平衡。
方法
OPEN-RAG框架推理流程
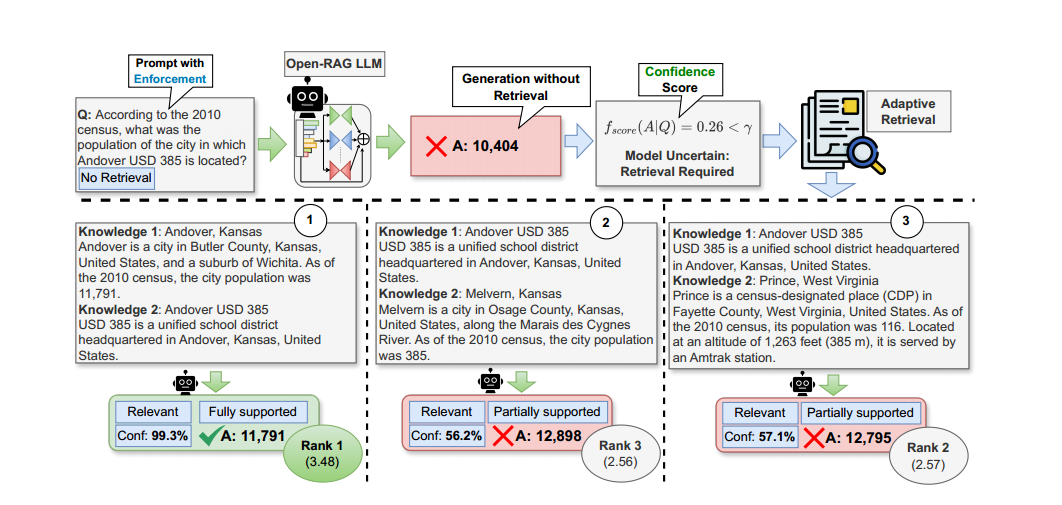
输入查询:用户提供一个查询q。 生成检索标记:模型首先生成检索标记([RT]/[NoRT]),指示是否需要检索。 无检索生成答案:如果模型判断不需要检索([NoRT]),模型仅利用其参数知识生成答案。 自适应检索:如果模型判断需要检索([RT]),则使用预定义的固定检索器R,从外部知识源D中检索前k个文档S,根据需要,可以执行单次检索或多跳检索。 文档评估:对于每个检索到的文档,模型进行一下评估: 相关性评估(Relevant/Irrelevant):对检索到的文档进行相关性评估。如果文档与查询相关,则标记为“Relevant”。如果文档与查询不相关,则标记为“Irrelevant”。 支持度评估(Fully supported/Partially supported/Not supported):对文档支持答案的程度进行评估。如果答案完全由文档支持,则标记为“Fully supported”。如果答案部分由文档支持,则标记为“Partially supported”。如果文档不支持答案,则标记为“Not supported”。 效用评分(Utility U):评估文档对回答的有用性,范围从1到5。 生成答案:模型并行处理每个检索到的文档,生成多个候选答案yt。 输出最终答案:根据模型对相关性、支持度和效用标记的置信度,对所有候选答案进行加权排序。选择最佳的答案作为最终响应ypred。
数据收集
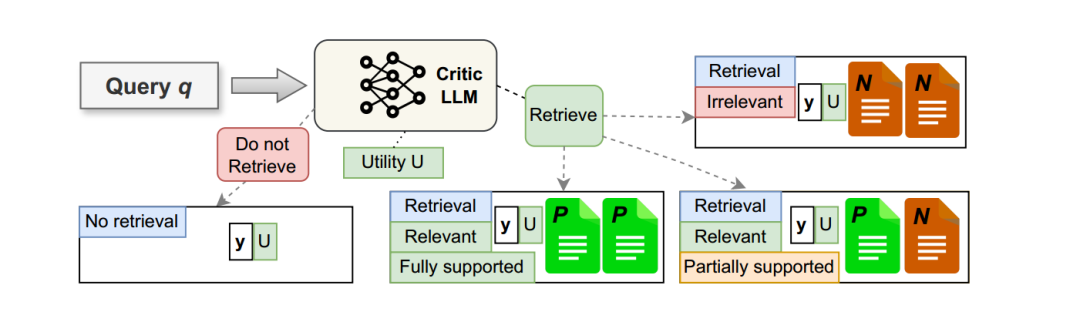
原始数据对:从原始数据集中获取输入输出数据对 ( (q, y) )。 添加反射标记:使用真实标签或Critic LLM来为数据对增强反射标记。 创建实例:
不需要检索([NoRT]):当添加的检索标记为 [NoRT] 时,直接生成答案并标记为“[NoRT]”。 需要检索([RT]):添加的检索标记为 [RT] 时,创建三个不同的新实例。首先使用R来检索前k个文档S。对于每个检索到的文档,Critic LLM 评估是否相关,并返回相关性标记。 完全支持([Fully Supported]):所有段落都预测为[RT],则添加“ [Fully Supported]”作为基础标记。 部分支持([Partially Supported]):部分段落预测为[RT],则添加“ [Partially Supported]”作为基础标记。 不相关([Irrelevant]):使用与问题不相关的文档,标记为“[Irrelevant]”。 相关([Relevant]):当预测为[Relevant]时,使用Critic LLM 评估支持度。
效用评分:无论相关性标记如何,都使用 Critic LLM 提供 y 对 q 的效用评分。
MoE微调过程
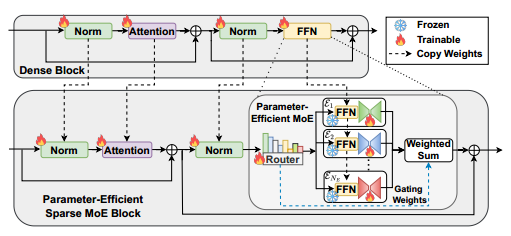
模型转换: OPEN-RAG将任意密集的LLM动态转换为稀疏混合专家(MoE)架构,在保持模型规模的同时,提升模型处理复杂推理任务的能力。 适配器模块: 每个专家的适配器模块(Aₑ)负责调整专家的输出,以更好地适应当前的查询。适配器模块的参数是在训练过程中更新的,而原始的FFN层参数保持不变。 适配器的公式为: 路由机制: 路由模块(R)根据输入选择Top-K个专家参与当前查询的处理。 路由公式为: 输出: MoE模型的输出 是激活的专家输出的加权和。 输出公式为: 微调过程: 在微调过程中,使用QLoRA适配器进行训练,目标包括标准的条件语言建模和负载平衡。 仅激活2个专家进行训练和推理,增强模型在复杂查询下的推理能力。
混合自适应检索方法
训练阶段: 模型学习生成检索反射标记([RT]和[NoRT])。 推理阶段: 在推理时,通过在输入中添加[NoRT],强制设置为无检索,并测量输出序列的置信度,形式为: 置信度评分: 采用两种不同的置信度评分函数 : 最小置信度 ( ):生成序列中每个标记概率的最小值。 平均置信度 ( ):生成序列中每个标记概率的几何平均值。 阈值控制: 使用一个可调的阈值(γ)来控制是否进行检索。如果置信度评分低于阈值,则触发检索;否则,不进行检索。
总结
Open-RAG 将传统的密集型大语言模型(LLM)转变为参数高效的稀疏专家混合(MoE)模型,使其能够处理复杂的推理任务,包括单跳和多跳查询。通过动态选择相关专家,Open-RAG 能有效应对看似相关但实际误导的干扰因素。此外,Open-RAG 引入了一种混合自适应检索方法,帮助模型在性能提升与推理速度之间取得平衡。该框架在复杂推理任务中表现出显著的性能改进。

文章转载自AI 搜索引擎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
