




前言
本文主要记录教育行业高校PyFlink整合Flink ML的场景案例实践总结。PyFlink是可以使用Python语言开发Apache Flink的功能API,允许构建批或流任务、机器学习、ETL等场景,分为Table API和DataStreamAPI。
FlinkML类库提供机器学习API、简化构建机器学习流式管道的复杂度,支持Java、Python语言,提供分类、聚类、回归、推荐、特征工程等多种场景的默认实现。欢迎关注微信公众号:大数据从业者
Flink ML模块
源码编译
git clone -b release-2.3.0 https://github.com/apache/flink-ml.gitcd flink-ml && mvn clean package -DskipTests -Pflink-1.17
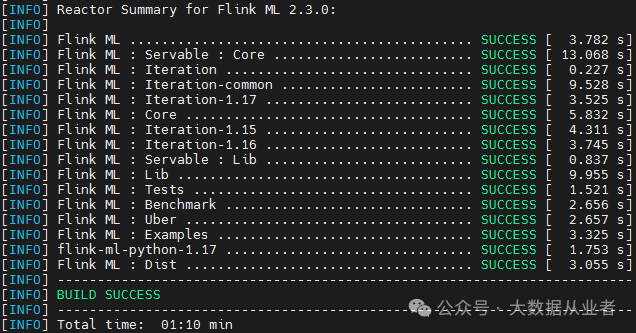
拷贝Jar到Flink部署目录
cp flink-ml-dist/target/flink-ml-2.3.0-bin/flink-ml-2.3.0/lib/flink-ml-uber-1.17-2.3.0.jar /home/myHadoopCluster/flink-1.17.1/lib/cp flink-ml-dist/target/flink-ml-2.3.0-bin/flink-ml-2.3.0/lib/statefun-flink-core-3.2.0.jar /home/myHadoopCluster/flink-1.17.1/lib/cp flink-ml-dist/target/flink-ml-2.3.0-bin/flink-ml-2.3.0/lib/flink-ml-examples-1.17-2.3.0.jar home/myHadoopCluster/flink-1.17.1/examples/
验证Java语言测试用例
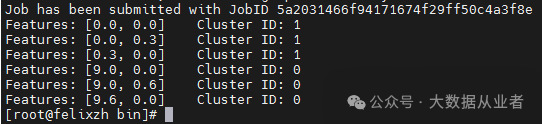
./flink run -t yarn-per-job -c org.apache.flink.ml.examples.clustering.KMeansExample ../examples/flink-ml-examples-1.17-2.3.0.jar
Python虚拟环境
Flink ML使用Python语言开发,需要特定版本:3.7或者3.8。如果你的集群环境Python版本不满足,建议使用如下脚本工具setup-pyflink-virtual-env.sh构建Python虚拟环境:
set -e# download miniconda.shsys_os=$(uname -s)echo "Detected OS: ${sys_os}"sys_machine=$(uname -m)echo "Detected machine: ${sys_machine}"if [[ ${sys_os} == "Darwin" ]]; thenwget "https://repo.anaconda.com/miniconda/Miniconda3-py310_23.5.2-0-MacOSX-${sys_machine}.sh" -O "miniconda.sh"elif [[ ${sys_os} == "Linux" ]]; thenwget "https://repo.anaconda.com/miniconda/Miniconda3-py310_23.5.2-0-Linux-${sys_machine}.sh" -O "miniconda.sh"elseecho "Unsupported OS: ${sys_os}"exit 1fi# add the execution permissionchmod +x miniconda.sh# create python virtual environment./miniconda.sh -b -p venv# activate the conda python virtual environmentsource venv/bin/activate ""# install PyFlink dependencyif [[ $1 = "" ]]; then# install the latest version of pyflinkpip install apache-flinkelse# install the specified version of pyflinkpip install "apache-flink==$1"fi# deactivate the conda python virtual environmentconda deactivate# remove the cached packagesrm -rf venv/pkgs# package the prepared conda python virtual environmentzip -r venv.zip venv
sh setup-pyflink-virtual-env.sh 1.17.1
脚本流程主要是先下载miniconda.sh构建Python虚拟环境venv、然后通过pip安装pyflink的依赖apache-flink、最后打成压缩包venv.zip。最终结果如下:
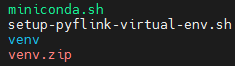
venv虚拟环境验证
source venv/bin/activate # 声明环境变量python --version # 查看Python版本号conda deactivate # 撤销环境变量
pyflink依赖验证(local模式)
source venv/bin/activatepython /home/myHadoopCluster/flink-1.17.1/examples/python/datastream/word_count.py

PyFlink on Yarn实践
通常真实现场环境都是Pyflink提交作业到yarn集群,使用统一的资源管理。针对Python虚拟环境的使用,分为三种方法:
方法1:每个pyflink作业提交时自行上传venv.zip
将示例代码和venv.zip放置到特定目录,如:/tmp/myApp

./flink run-application -t yarn-application -Dyarn.ship-files=/tmp/myApp/ -pyarch myApp/venv.zip -pyclientexec venv.zip/venv/bin/python3 -pyexec venv.zip/venv/bin/python3 -pyfs myApp -pym word_count --output hdfs:///tmp/
方法2:提前上传venv.zip到hdfs供所有pyflink作业使用
hdfs dfs -put ven.zip hdfs:///flink/

./flink run-application -t yarn-application -Dyarn.ship-files=/home/myHadoopCluster/flink-1.18.1/examples/python/datastream/ -pyarch hdfs:///flink/venv.zip -pyclientexec venv.zip/venv/bin/python3 -pyexec venv.zip/venv/bin/python3 -pyfs datastream -pym word_count --output hdfs:///tmp
方法3:提前在每个yarn集群节点本地放置相同路径venv.zip解压文件夹
./flink run-application -t yarn-application -pyclientexec /tmp/venv/bin/python3 -pyexec /tmp/venv/bin/python3 -Dyarn.ship-files=/home/myHadoopCluster/flink-1.18.1/examples/python/datastream/word_count.py -py word_count.py --output hdfs:///tmp/
推荐使用方法3,性能最好。但是,需要注意一点:yarn集群节点扩容时,新节点需要部署相同venv目录即可!
总结
本文记录如何使用conda构建Python虚拟环境、如何使用PyFlink整合使用FlinkML类库。
