




背景
最近巡检数据库,发现开发库的索引表空间达到99.8%,于是统计了下数据库里面的大表发现:T_ORDERS(已做脱敏)达到了39.56GB。和开发沟通此表可以清理,但需要留一部分数据。
- 操作方案:索引表空间直接从99.8%下降到26%
SQL> create table T_ORDERS_TMP as
select * From T_ORDERS
where create_date >=to_date('2024-08-15','yyyy-mm-dd');
SQL> select count(*) from T_ORDERS_TMP;
COUNT(*)
----------
9001563
SQL> truncate table T_ORDERS;
Table truncated.
SQL> select count(*) from T_ORDERS;
COUNT(*)
----------
0
SQL> insert into T_ORDERS select * from T_ORDERS_TMP;
9001563 rows created.
SQL> commit;
- 遇到的问题:
执行 truncate table T_ORDERS hang住没反应,开发人员反馈数据库很慢,我查数据库状态返回也很慢,明眼看数据库的状态就不对。
问题排查
1、查看锁情况,发现SID=322 会话里多了个对MLOG$表的锁
SELECT b.session_id AS sid,
NVL(b.oracle_username, '(oracle)') AS username,
a.owner AS object_owner,
a.object_name,
Decode(b.locked_mode, 0, 'None',
1, 'Null (NULL)',
2, 'Row-S (SS)',
3, 'Row-X (RX)',
4, 'Share (S)',
5, 'S/Row-X (SSX)',
6, 'Exclusive (X)',
b.locked_mode) locked_mode,
b.os_user_name
FROM dba_objects a,
gv$locked_object b
WHERE a.object_id = b.object_id;
SID USERNAME OBJECT_OWNER OBJECT_NAME LOCKED_MODE OS_USER_NAME
----- ---------- -------------------- ------------- --------------- --------------
322 two SYS MLOG$ Row-X (RX) oracle
322 two two T_ORDERS Exclusive (X) oracle
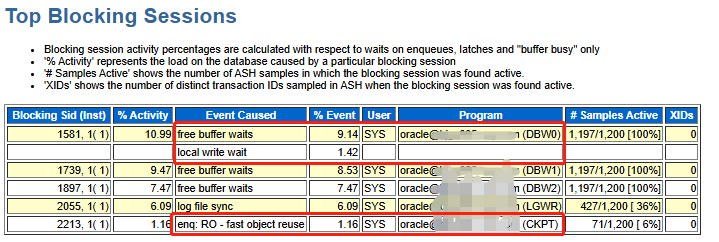
2、查看当时ash报告
- truncate 引起:local write wait、enq: RO - fast object reuse两个等待事件

- 进程:CKPT =>enq: RO - fast object reuse;
- 进程:DBW0 =>local write wait、free buffer waits
3、查看redo 切换频率
- 按小时查看切换频率
select thread#,trunc(completion_time) as "date",to_char(completion_time,'Dy') as "Day",count(1) as "total",
sum(decode(to_char(completion_time,'HH24'),'00',1,0)) as "h00",
sum(decode(to_char(completion_time,'HH24'),'01',1,0)) as "h01",
sum(decode(to_char(completion_time,'HH24'),'02',1,0)) as "h02",
sum(decode(to_char(completion_time,'HH24'),'03',1,0)) as "h03",
sum(decode(to_char(completion_time,'HH24'),'04',1,0)) as "h04",
sum(decode(to_char(completion_time,'HH24'),'05',1,0)) as "h05",
sum(decode(to_char(completion_time,'HH24'),'06',1,0)) as "h06",
sum(decode(to_char(completion_time,'HH24'),'07',1,0)) as "h07",
sum(decode(to_char(completion_time,'HH24'),'08',1,0)) as "h08",
sum(decode(to_char(completion_time,'HH24'),'09',1,0)) as "h09",
sum(decode(to_char(completion_time,'HH24'),'10',1,0)) as "h10",
sum(decode(to_char(completion_time,'HH24'),'11',1,0)) as "h11",
sum(decode(to_char(completion_time,'HH24'),'12',1,0)) as "h12",
sum(decode(to_char(completion_time,'HH24'),'13',1,0)) as "h13",
sum(decode(to_char(completion_time,'HH24'),'14',1,0)) as "h14",
sum(decode(to_char(completion_time,'HH24'),'15',1,0)) as "h15",
sum(decode(to_char(completion_time,'HH24'),'16',1,0)) as "h16",
sum(decode(to_char(completion_time,'HH24'),'17',1,0)) as "h17",
sum(decode(to_char(completion_time,'HH24'),'18',1,0)) as "h18",
sum(decode(to_char(completion_time,'HH24'),'19',1,0)) as "h19",
sum(decode(to_char(completion_time,'HH24'),'20',1,0)) as "h20",
sum(decode(to_char(completion_time,'HH24'),'21',1,0)) as "h21",
sum(decode(to_char(completion_time,'HH24'),'22',1,0)) as "h22",
sum(decode(to_char(completion_time,'HH24'),'23',1,0)) as "h23"
from v$archived_log
where first_time > trunc(sysdate-10)
and dest_id = (select dest_id from v$ARCHIVE_DEST_STATUS where status='VALID' and type='LOCAL')
group by thread#, trunc(completion_time), to_char(completion_time,'Dy')
order by 2,1;

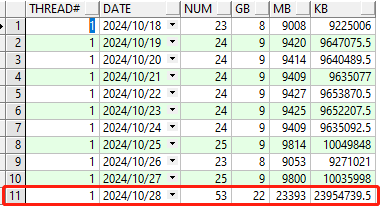
- 按天统计日志量
select THREAD#, trunc(completion_time) as "DATE"
,count(1) num
,trunc(sum(blocks*block_size)/1024/1024/1024) as GB
,trunc(sum(blocks*block_size)/1024/1024) as MB
,sum(blocks*block_size)/1024 as KB
from v$archived_log
where first_time > trunc(sysdate-10)
and dest_id = (select dest_id from V$ARCHIVE_DEST_STATUS where status='VALID' and type='LOCAL')
group by thread#,trunc(completion_time)
order by 2,1;
4、等待事件简介
Free Buffer waits:
- 产生原因:
- 当进程在buffer cache中找不到空闲的buffer时会向DBWR进程发出写入请求,直到DBWR进程完成,在这期间就会产生该等待事件。
- 检查db_writer_processes参数,默认每8个CPU会有一个dbwr进程;
- SQL效率差,物理读过大或者要构造的CR块过多,比如大表select *,笛卡尔积等;
- DBWR进程写缓慢或DBWR进程的工作量过多;
- 存储性能有问题,可能写脏数据慢,可能写redo慢;
- 延迟块清除,这种行为可能会占用大量的buffer;
- db_cache_size值太小,一般由Oracle管理,默认为0;
enq: RO - fast object reuse:
- 产生原因
RO排队称为“多对象结果”排队,用于同步前台进程和后台进程(如DBWR或CKPT)之间的操作。它通常发生于DROP或TRUNCATE命令。 - 以下是发生DROP或TRUNCATE命令的事件顺序:
1.前台流程以独占模式获取“RO”排队
2.发出跨实例调用(如果是单个对象,则发出一个调用)(获取“CI”排队)
3.每个实例上的CKPT进程请求DBWR将脏缓冲区写入磁盘,并使所有干净缓冲区无效。
4.DBWR完成所有块的写入后,前台进程释放RO入队。 - 等待的时间也受到扫描缓冲区缓存以查找要写入磁盘和从缓存中清除的脏块所花费的时间的影响。缓冲区缓存越大,找到这些块所需的时间就越长。若缓冲区缓存非常大,减小其大小对提高性能非常有效。
Local write waits
- 产生原因
基本上’local write’ wait 表示会话在等待自己的写操作。。在磁盘发生严重问题时会发生(例如RAID 5的一个磁盘崩溃,或者磁盘控制器错误),这在正常的系统中极少发生,在TRUNCATE 一个大表而这个表在缓存中的时候,会话必需进行一个localcheckpoint,这个时候会话会等待localsession wait.
总结
通过自己的操作流程及等待事件的表现来分析:
- 1、create table T_ORDERS_TMP as select * From T_ORDERS where create_date >=to_date(‘2024-08-15’,‘yyyy-mm-dd’); 操作将39G的数据全部加载到SGA,SGA仅有18GB;
- 2、因此导致buffer cache中找不到空闲的buffer时会向DBWR进程发出写入请求,从而产生“Free Buffer waits”事件;
- 2、然后频繁的写入,日志切换很频繁,可能会引起DBWR进程的等待,而执行truncate需要做Checkpoint,同样会等待DBWR;
- 3、dbw0进程写回buffer cache中的脏数据块, 出现等待事件“enq: RO - fast object reuse”、“Local write waits”;
- 4、从而导致truncate 表hang住的原因。全程都在等dbw0刷脏结束;
欢迎赞赏支持或留言指正

最后修改时间:2024-11-01 11:16:40
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
