




背景
IoT(Internet of Things,物联网)是指通过互联网将各种物理设备、传感器、软件和其他技术连接起来,形成一个智能网络。这些设备可以相互通信、数据交换、收集和分析信息,从而实现自动化、远程监控和控制。
常见IOT智能设备包括了:
- 智能家居:如智能灯泡
、智能温控器、智能音响等 - 智慧城市:优化交通管理、智能照明、环境监测等
- 工业互联网:传感器监控设备等
- 健康监测:可穿戴设备监测健康数据,如电子手表等。
IOT场景的显著特征是:
- 设备之间是平等的,不存在“冷设备”、“热设备”,所有设备都会以一个相对固定的频率产生实时的数据;
- 数据量超级大,通常是百亿、千亿级别。
- 多样的数据类型,IoT设备可以采集各种类型的数据,如温度、湿度、位置、速度、图像等,这些数据的丰富性也增加了数据量。
存储IOT采集到的海量数据,通过对这些数据分析加工,可以为各行各业带来巨大的经济和社会效益。
例如,我们做一个智能家居中常用的温度传感器:
- 该传感器1分钟会采样一次温度,并将温度数据上传;
- 该传感器卖出50万件;
- 数据保留3个月。
会产生多少数据呢?简单计算下,500000*60*24*30*6=650亿,平均每秒产生8300条。
存储如此庞大的数据量,我们很多时候会使用一些时序数据库
- 时序数据库,具有较高的写入性能,能够快速处理大量的实时数据;
- 时序数据库,优化了数据存储
方式,通常使用特定的压缩技术来减少存储空间,能降低存储成本;
但出于一些原因,也会用关系型数据库
- MySQL、PG等关系型数据库历史更长,稳定性等风险更低;
- 会用MySQL、PG的人更多,学习成本低,用着丰富的上下游生态工具,开发成本低;
- 二级索引、事务等能力让关系型数据库更易用;
- 我就是喜欢关系型数据库,就是想用!
实际上只要在合理使用关系数据库
今天,我们会探讨一下,如何使用分布式数据库
如何设计合适的表结构
一般IOT设备的采集表如下:
create table device_data(
id int primary key auto_increment,
gmt_create datetime,
device_id varchar(128),
c1 int,
c2 varchar(128),
c3 int,
c4 int
);其中device_id表示采集的设备ID,gmt_create表示采集的时间戳,c1……c4各个字段表示采集的信息,如果一开始设计成单表,要存储650亿条数据, 根本就不可能:
- 受限于单节点的CPU/内存/IOPS资源以及B+树层树变高,性能会变差;
- 单个节点无法提供200T的数据空间。
所以在PolarDB-X里头,我们很容易想到按照设备ID做拆分,将上面的表改成分区表
create table device_data(
id int primary key auto_increment,
gmt_create datetime,
device_id varchar(128),
c1 int,
c2 varchar(128),
c3 int,
c4 int
) PARTITION BY KEY(`device_id`)
PARTITIONS 512;将表拆分成512张分区表:
- 一张分表的数据行数控制在5000万以下,可以避免B+树增加带来的查询代价变高的问题;
- 拆成多个分表,利用多个数据节点存储200T数据,同时充分利用分布式资源可以承担百亿表的查询和更新。
表设计好后,我们做了一波压测,发现随着数据量越来越多,数据库查询和更新性能抖动越来越厉害,反应到Buffer Pool刷脏率也在慢慢变高。
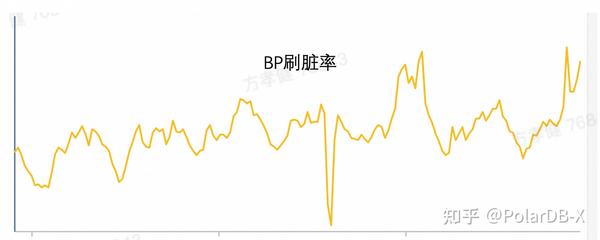
其实也好理解,按照设备ID做拆分,写入和查询会涉及到所有的分表,各个表都会加载到BP上去,能命中BP性能更好,但是随着表数据越来越多,不能保证所有的分表都可以被BP全部加载,出现BP被击穿,BP大量换入换出,性能下降明显。
但是我们知道IOT场景有一个显著的特征:
数据有比较强的时间属性,经常需要查询或者更新最近的数据
在这类背景下,推荐建表的分区策略:采用hash+range的二级分区策略,一级分区按照设备ID做hash,二级分区按照时间,每天一个子分区。
CREATE TABLE device_data (
.....
KEY idx (device_id,create_time)
)
PARTITION BY KEY(`device_id`)
PARTITIONS 128
SUBPARTITION BY RANGE(TO_DAYS(`create_time`))
(SUBPARTITION `p20240901` VALUES LESS THAN (739282),
SUBPARTITION `p20240902` VALUES LESS THAN (739311),
SUBPARTITION `p20240903` VALUES LESS THAN (739342),
SUBPARTITION `p20240904` VALUES LESS THAN (739372),
SUBPARTITION `p20240905` VALUES LESS THAN (739403),
SUBPARTITION `p20240906` VALUES LESS THAN (739433),
SUBPARTITION `p20240907` VALUES LESS THAN (739464),
SUBPARTITION `p20240908` VALUES LESS THAN (739495),
SUBPARTITION `p20240909` VALUES LESS THAN (739525),
....
);可以确保数据写入和更新都发生在每个一级分区内的最后一个子分区,保证其他非最新的分区都可以从BP淘汰出去,确保最后的一个新分区始终在BP中,这样可以确保写入和查询性能。随着数据量增多,BP的刷脏可以保持稳定,写入性能很平稳。
如何高效的处理实时数据
在IOT场景中除了数据上报入库外,经常需要查询最近一批数据的场景,比如获取一个设备的最新实时状态,指定一个设备ID,查询最近一段时间内的1000条上报记录:
select * from device_data where device_id = 1
order by create_time desc limit 1000;在一级按照设备ID拆分,二级采用Range分区,上述SQL可以利用设备ID裁剪到某个一级分区下,但是无法对二级分区做进一步裁剪。
二级分区是range分区
- 第一轮,扫描最新的p20240925分区,是否找到符合条件的1000条数据,找全查询结束;否则继续;
- 第二轮,扫描p20240924和p20240923分区,继续找到符合条件的数据,找全1000条数据,查询结束;否则继续
- 第三轮,扫描p20240922、p20240921、p20240920和p20240919分区,继续找到符合条件的数据,找全1000条数据,查询结束;否则继续
- ...
充分利用利用Range分区的有序性,采用自适应prefech机制,可以有效降低对二级分区的扫描,降低RT。
除了查询场景以后,IOT场景中会根据设备device_id对采集的数据进行维护和更新。
update device_data set xxx where device_id=xx and id=?由于IOT业务特点,数据的更新是有明显的时效性的,也即,大多数要更新的数据都是最近的数据(很好理解,只有设备离线时间比较久,才会出现很久以前的数据被更新),这里可以理解上述业务发起更新的时候,往往可以在最近一天的Range分区找到待更新的数据,所以我们在实际更新过程
但存在一种场景,如果按照最近时间倒序串行去更新数据,如果业务上更新的是几天前的数据,那么就存在交互多次,性能会有很大的回退。为此我们和业务上可以有一个约定,如果业务上确实具备最近更新的特征,那么SQL上可以改写成
update device_data where device_id=? and id=?
and create_time<=now()
order by create_time desc limit 1;- 为了扫描预建的未来的分区,增加条件create_time<=now();
- 因为更新有时效性,增加order by create_time desc 优先从最近的分区开始尝试更新,利用Range Scan的特性,更新一条后即结束
- 可以按情况增加limit 1。分区键不包含主键id,不保证id的全局唯一性,可以增加limit 1。如果是自增id,满足唯一性约束,可以不用增加
这样数据库可以精确识别业务场景,借用Range分区的有序性,做到高效的更新。
如何最大限度降低存储成本
IOT场景中每时每刻都在产生数据,所以存储成本的优化是绕不开的话题。有更多的IOT数据,可以利用这些历史数据进行预测,提前识别潜在问题或需求变化。同时鉴于一些合规性需求,要求存储数据
以上面智能家居中温度传感器采集表为例,如果要求库存一年的数据,我们来计算一笔账。
一年的800T的IOT数据,按照单价1000元 TB/月,光存储成本一年就得800w
这成本还是很高的。但是一般IOT的数据有很强的时间属性,往往是最热的数据作为分析和决策更有价值。借助PolarDB-X提供的透明归档能力,我们可以考虑非最近采集到的数据最归档,归档到更低成本的OSS上去,具体使用可以参考官网文档:冷数据归档(TTL)。
比如这里把最近1个月的数据存储到PolarDB-X行存里头,其他11个月的数据以列存
一年有66T的IOT数据,存放在行存,存储成本是66w;剩余734T的行存数据,以列存格式归档到对象存储,按照5倍压缩比计算,实际需要空间是146T数据空间,这部分数据在对象存储存放一年的成本是21W。总存储成本是87W。
从800W到87W,存储成本下降至10%,下降幅度非常明显。
用户只需要对上面表device_data执行一条归档的DDL语句就行。
ALTER TABLE device_data
MODIFY TTL
SET
TTL_ENABLE = 'ON'
TTL_EXPR = `gmt_create` EXPIRE AFTER 30 DAY TIMEZONE '+08:00'
TTL_JOB = CRON '0 0 2 */1 * ? *' TIMEZONE '+00:00';上面数据执行后,我们每天凌晨2点后检测并将device_data表中30天之前的数据归档到对象存储上去,归档过程中在线的,不影响在线业务。同时我们的在线归档
- 支持对冷数据做DDL和数据变更;
- 归档后的冷数据查询方式和行存数据一样,并不会改变用户习惯。
up!up!up!一站式的HTAP能力
IOT场景的数据除了要保证高效的实时入库、更新和查询,这些采集到的数据也非常庞大,在对用户的行为数据做分析,有助于提供产品决策,提供更好的服务。比如在工业监控场景上,通过监控设备工作状态来预测故障,进行预防性维护
在此之前我们会把存储在关系数据库或者时序数据库的大量IOT数据,同步到结合传统的数据仓库工具,如Hadoop或Spark,对历史数据进行深度分析。
现在借助PolarDB-X提供的一站式HTAP能力,我们可以在PolarDB-X数据库内即可以满足高效的入库和更新需求,借助于我们的列存索引满足对海量数据分析
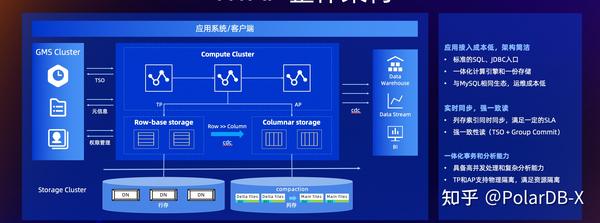
在IOT场景上,合理使用关系数据库是可以兼具高性能和低成本的优势。在用户真实的IOT场景中,从时序数据库迁移到PolarDB-X,成本和性能都极具优势。同时关系数据库又有着时序数据库无法比拟的优势:
