




背景
2022年5月,PolarDB-X为了加强数据库HTAP一体化能力,便开始构思行列混存架构,希望通过列式存储格式的数据进一步加强AP能力,同时具有更好的数据压缩比,降低存储成本,在数据分析场景能够让用户有更好的体验。
PolarDB-X V2.4版本在2024年4月份发布,首次推出列存索引能力,在原来的架构上增加了列存引擎节点(Columnar),目前的架构如下:
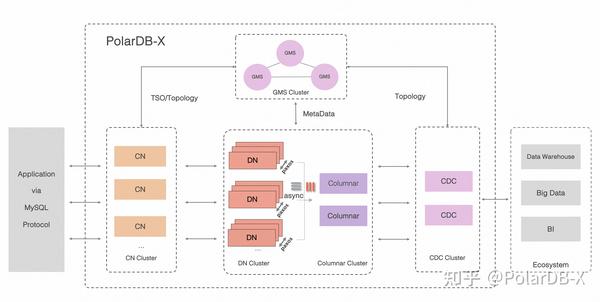
- 计算节点(CN, Compute Node)
计算节点是系统的入口,采用无状态设计,包括 SQL 解析器、优化器、执行器等模块。负责数据分布式路由、计算及动态调度,负责分布式事务 2PC 协调、全局二级索引维护等,同时提供 SQL 限流、三权分立等企业级特性。 - 存储节点(DN, Data Node)
存储节点负责数据的持久化,基于多数派 Paxos 协议提供数据高可靠、强一致保障,同时通过 MVCC 维护分布式事务可见性。 - 元数据服务(GMS, Global Meta Service)
元数据服务负责维护全局强一致的 Table/Schema, Statistics 等系统 Meta 信息,维护账号、权限等安全信息,同时提供全局授时服务(即 TSO)。 - 日志节点(CDC, Change Data Capture)
日志节点提供完全兼容 MySQL Binlog 格式和协议的增量订阅能力,提供兼容 MySQL Replication 协议的主从复制能力。 - 列存节点 (Columnar)
列存节点提供持久化列存索引,实时消费分布式事务的binlog日志,基于对象存储介质构建列存索引,能满足实时更新的需求、以及结合计算节点可提供列存的快照一致性查询能力。
1. 设计思路
第一步,当然是确定架构,该架构需满足如下期望点:
- 不希望对现有的行存造成影响,需要进行资源隔离,所以新增列存节点
- 采用计算存储分离架构,能够较大提高资源利用率和高可用能力,所以需要计算节点和存储节点分离
- 沿用分布式框架,加强可扩展性,所以采用共享存储
满足这三点的前提下,一个大概的分布式数据库雏形就出现了:
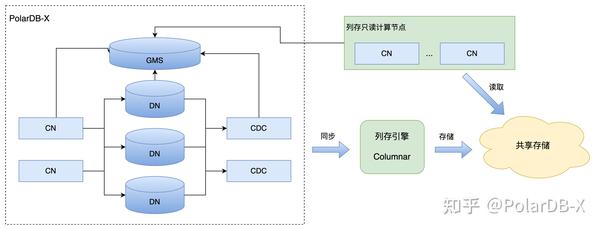
如图所示,左边的PolarDB-X是之前只有行存的架构,在此基础上,增加一个列存引擎,负责同步行存的数据,并以列式格式存储到共享存储中,以一个个文件的形式存储数据,列存只读计算节点负责接收用户的sql请求,解析成需要查询的各个算子,通过读取共享存储中的文件,返回数据给用户。至此,一个完整的数据链路就形成了,各个组件的功能也明确,下一步,便是细化各个组件的设计。
第二步,确定共享存储的形态,列存更多是面向分析型计算场景,该数据场景对存储有几点要求:
- 海量存储:存储量大,对存储伸缩性高,可扩展
- 带宽高:AP场景计算量大,多线程并发高,需要较高带宽
- 持久化和安全性:存储需具备的基本特点
- 存储成本尽可能低:在满足性能和可靠性要求下,尽可能降低存储成本,是所有用户期望的
综合上述几点,PolarDB-X首选了阿里云的对象存储(OSS)作为常用场景,阿里云对象存储OSS(Object Storage Service)是一款海量、安全、低成本、高可靠的云存储服务,可提供99.9999999999%(12个9)的数据持久性,99.995%的数据可用性,性能上普通用户便可达10Gbps带宽,最重要的,它的存储成本极低,按量付费存储价格:
| 存储类型 | 标准型单价 | 低频访问型单价 | 归档型单价 |
| 数据存储(本地冗余存储) | 0.12 元/GB/月 | 0.08 元/GB/月 | 0.033 元/GB/月 |
| 数据存储(同城冗余存储) | 0.15 元/GB/月 | 0.10 元/GB/月 | 0.033 元/GB/月 |
OSS存储价格截取的2024年9月阿里云官网OSS价格计算表,详细请见:链接
如此低廉的价格成本能够让列存存储成本降到非常低,而且列式存储文件支持不同的压缩算法,通常具备3~10倍的数据压缩效率,更加降低压缩成本。当然,OSS存储比较适合公有云用户,对于其它应用场景,需支持其它共享存储,例如NFS、S3等,所以列存引擎和计算节点需要抽象出文件系统接口,方便后续兼容不同的存储模型。
第三步,列存只读计算节点如何设计,PolarDB-X行存已经是一个较为成熟的计算节点设计方案,但列存和行存在优化器和执行器层面会有较大区别,AP场景和TP场景有着本质上的区别,所以列存只读计算节点需要设计一套适合AP场景的优化器和执行器,PoldarDB-X选择在现有的行存计算节点上进行设计,使用同一套代码,以不同模式启动,方便后续在行列混存一体化上面设计出最佳执行计划,充分利用行存和列存特性,用户执行一条sql,可同时在行存和列存组合执行,返回用户结果,在行列混存的新型数据库架构中造探索出最佳实践,以更好地适应多样化的数据处理需求,在数据库前沿方向进行技术创新。
第四步,设计合适的列存存储引擎,完成数据同步,将行存转成列存,该部分也是本文将要详细介绍的内容。
