




1、概述
xx公司现网大数据平台主要进行数据采集和汇总分析,其中数据采集通过Hadoop平台进行批采和实时采集,数据汇总主要通过数据仓库进行。数据仓库作为一个数据集中的存储和分析平台,能够帮助企业从海量数据中提取有价值的信息,从而支持更有效的决策制定。
1.1、现网架构
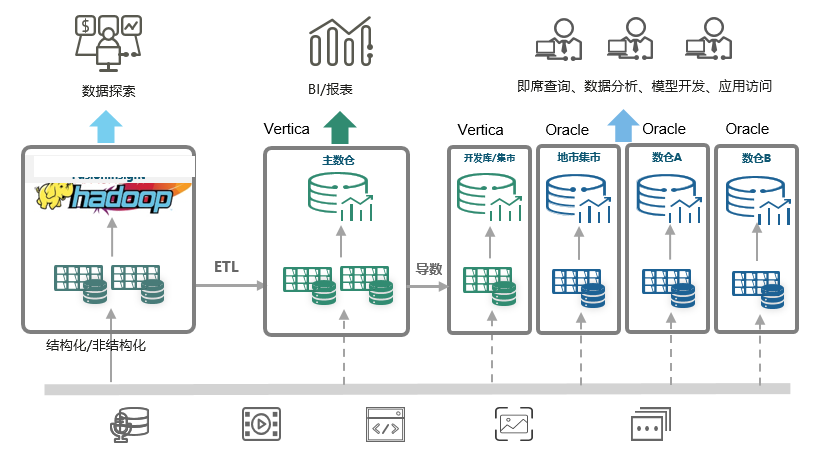
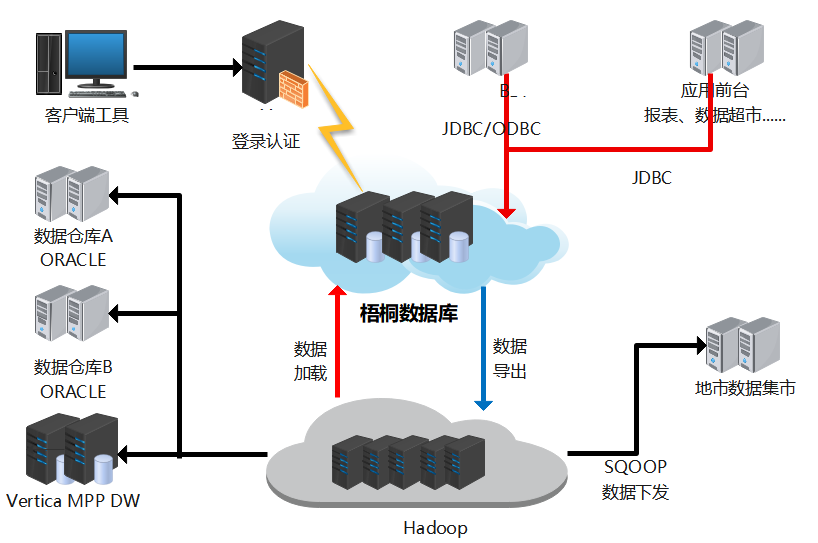
xx公司数据仓库按照主题域划分为N个数据仓库和N个数据集市,分别为MPP主数仓、考核业务数据仓库、业务应用数据库仓库和地市数据集市、开发数据集市。
-
MPP主数仓
主要负责B域基础业务的数据加载和汇总,为考核数仓和应用数仓提供基础数据。
-
考核数仓
主要负责集团考核业务的数据生成和上报。
-
应用数仓
主要负责高度汇总模型的统计分析,如:报表、关键指标,为全省分析人员提供业务决策数据。
总体数据仓库架构如下图所示:
1.2、现网架构存在的问题
现网数据仓库由多个异构数据库组成,数据库之间交互存在瓶颈,严重影响业务系统的处理效率,目前现网的数据仓库架构主要存在以下问题:
- 多个异构数据仓库平台,数据交互困难
现网数仓平台由多个品牌数据库组成,没有统一的数仓平台,并且异构数据库之间无法进行数据交互,造成业务系统增加大量的冗余模型和数据同步流程,增加了业务处理流程的复杂度,降低了业务处理效率。
- MPP主数仓存算一体架构,平台扩容及其困难
MPP主数仓为存算一体架构,目前存储使用率已超告警阈值,如需增加存储容量需要进行MPP主数仓横向扩容,新增扩容节点必须为现有节点的整数倍,同时数据重新分布需要较长的时间完成,严重影响业务系统的稳定运行。
- 开发平台及开发语言不统一,业务开发及维护复杂且成本高
由于采用多个数据库产品,开发人员需要使用不同的开发平台和开发语言,导致开发效率降低,维护成本提升。
- 国外产品面临数据安全和许可证风险,不符合自主可控要求
现网数仓采用国外数据库品牌,面临数据安全、许可证、供应链风险。随着国家对关键信息基础设施安全保护的重视,加速用户在核心系统实现自主可控的决心。
1.3、目标架构
针对上述现网数仓平台存在的问题,后续大数据平台数据仓库演进的目标为“自主可控+统一数仓+弹性伸缩+存算分离+湖仓融合”数据仓库平台,具体目标架构如下图所示
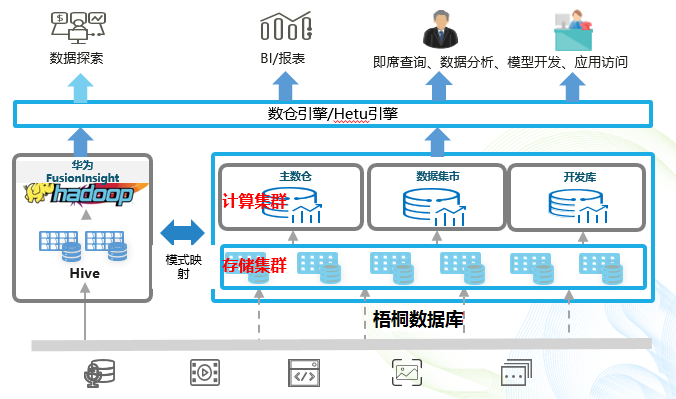
目标架构的优势:
- 统一底层技术架构,实现统一数仓平台,多子集群共享一份数据。
- 存算分离的云原生架构,可支撑湖仓一体,解决数据孤岛问题。
- 统一SQL访问及作业脚本开发,减少业务开发及维护复杂度,提升效率。
- 梧桐数仓存储与计算分别独立扩展,提升资源利用率和扩容灵活性。
- 数仓平台实现国产化,自主品牌、自主可控的云原生分布式数据库产品。
1.4、梧桐数据库介绍
梧桐数据库(WuTongDB)通过实现存算分离、节点无状态架构提供高可用、高可靠、高扩展能力,通过实现向量化计算引擎提供极速数据分析能力,提供云原生部署和弹性伸缩能力,可以帮助企业用户轻松构建核心数仓、数据集市、实时数仓以及湖仓一体数据平台。
2、梧桐数据库POC
本次梧桐数据库POC测试的目的是用于验证数仓产品能否支撑现网大数据业务处理能力和是否具备灵活的可扩展性和易维护性、安全性以及与其它数据库平台连通能力。
2.1、POC测试环境
- 硬件环境配置
| 类型 | 单机配置 | 数量(台) |
|---|---|---|
| 数仓主机 | B1型主机:中兴R5300 G4 2*5218-16Core,12*32GB内存,2*480GB SATA SSD+12*1.92TB SATA SSD,4*10GE光口+2*GE电口+1*IPMI(板载) | 98 |
| Hadoop主机 | C3型主机(2台):中兴R8500 G4 4*6248-20Core,24*32GB内存,2*480GB SATA SSD+6*960G SATA SSD,4*25GE光口+2*GE电口+1*IPMI(板载) B2型主机(60台):2*5218-16Core,12*16GB内存,2*480GB SATA SSD+12*8TB SATA HDD,4*10GE光口+2*GE电口+1*IPMI(板载) | 62 |
- 软件环境配置
| 类型 | 软件配置 | 备注 |
|---|---|---|
| 数仓主机 | 操作系统:BCLinux For Euler 21.10 | |
| Hadoop主机 | 操作系统:redHat7.9 Hadoop平台:华为FI 6.5.1.7 | 对齐Hadoop平台开源版本3.1.1 |
2.2、数据加载测试
- 梧桐数据库加载测试
| 测试项目 | 表名 | 数据量 | 用时(秒) |
|---|---|---|---|
| 单并发客户表加载 | XXX.TEST1 | 376494426 | 55 |
| 8并发客户表加载 | XXX.TEST1 | 376494426 | 82 |
| 32并发客户表加载 | XXX.TEST1 | 376494426 | 211 |
- 生产MPP加载用时
| 测试项目 | 表名 | 数据量 | 用时(秒) |
|---|---|---|---|
| 客户表加载 | XXX.TEST1 | 376494426 | 56 |
2.3、数据导出测试
- 梧桐数据库导出测试
| 测试项目 | 表名 | 数据量 | 用时(秒) |
|---|---|---|---|
| 单并发客户表导出 | XXX.TEST2 | 71251640 | 110 |
| 4并发客户表导出 | XXX.TEST2 | 71251640 | 125 |
| 16并发客户表导出 | XXX.TEST2 | 71251640 | 241 |
| 32并发客户表导出 | XXX.TEST2 | 71251640 | 483 |
- 生产MPP导出用时
| 测试项目 | 表名 | 数据量 | 用时(秒) |
|---|---|---|---|
| 客户表导出 | XXX.TEST3 | 71251640 | 49 |
2.4、数据汇总测试
- 梧桐数据库汇总测试
| 测试项目 | 用时(秒) |
|---|---|
| 单并发用户日汇总 | 136 |
| 4并发用户日汇总 | 606 |
| 8并发用户日汇总 | 1318 |
| 16并发用户日汇总 | 1356 |
- 生产汇总用时
| 测试项目 | 用时(秒) |
|---|---|
| 用户日汇总 | 117 |
2.5、扩展能力测试
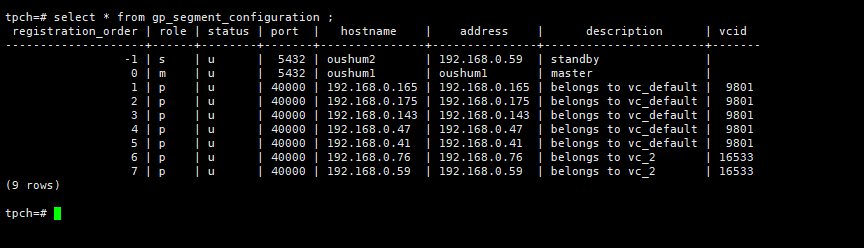
2.5.1、计算节点扩容
测试内容: 测试集群独立扩展计算节点的能力。计算节点扩容集群正常运行。
测试截图:
2.5.2、存储节点扩容
测试内容: 测试集群独立扩展存储节点的能力。存储节点扩容集群正常运行。
测试截图:
2.6、高可用能力测试
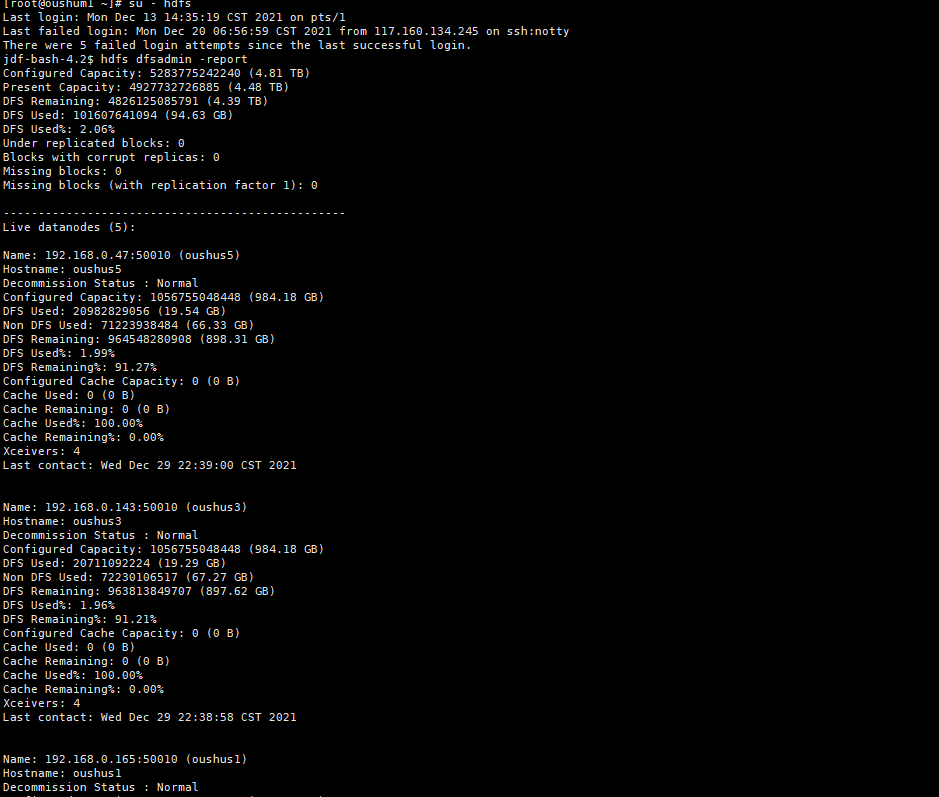
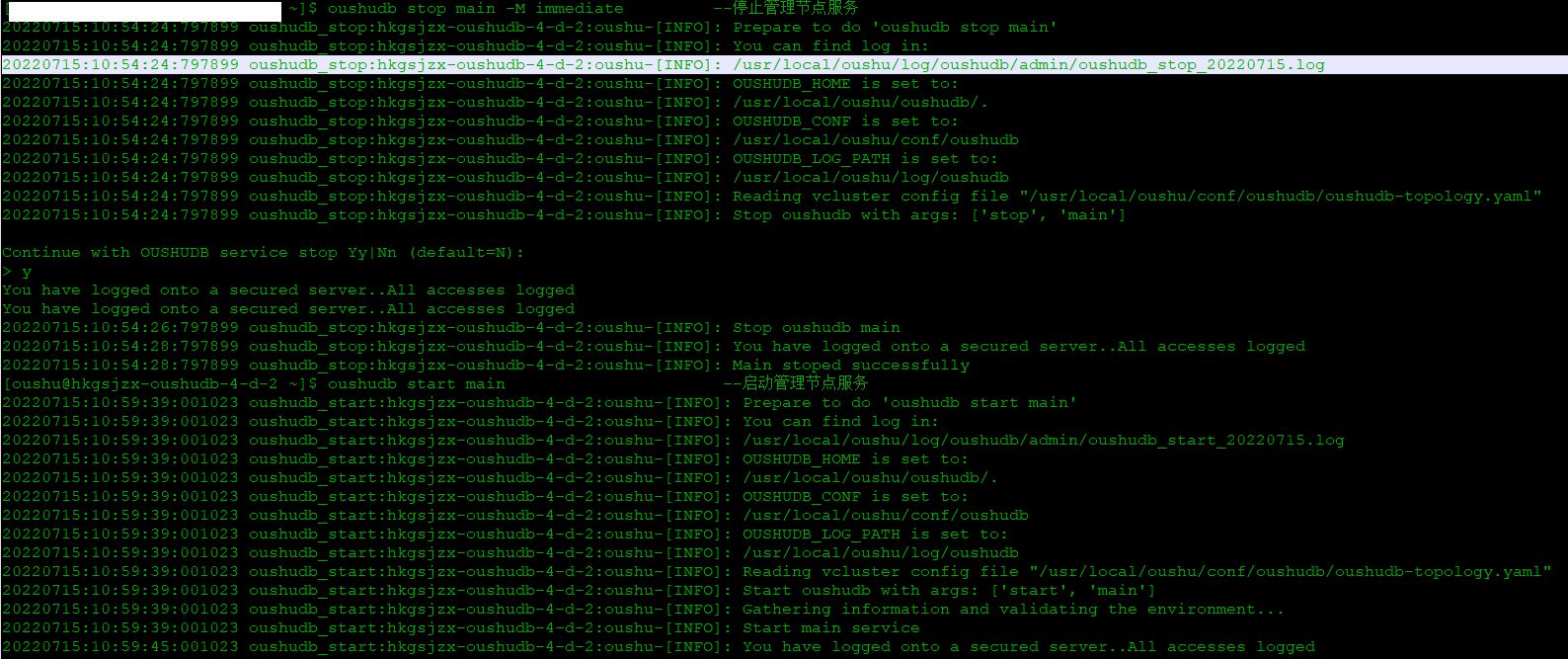
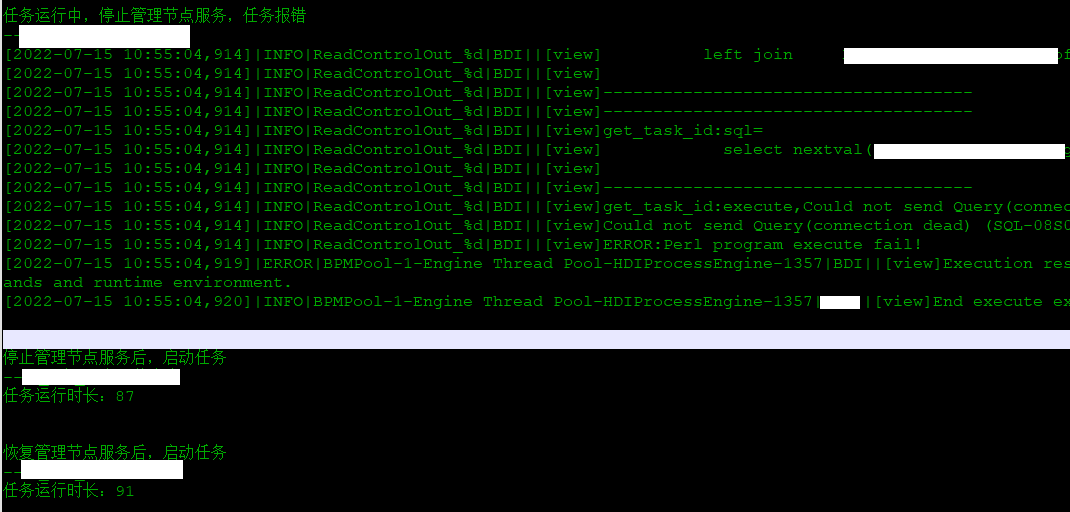
2.6.1、管理节点高可用
测试内容: 停止一个管理节点,后续业务应用能否正常运行
测试截图:
2.6.2、元数据节点高可用
测试内容: 停止一个元数据节点,后续业务应用能否正常运行
测试截图:
停止元数据节点

连接梧桐数据库,执行SQL

2.6.3、计算节点高可用
测试内容: 停止一个计算节点,后续业务应用能否正常运行
测试截图:
停止计算节点
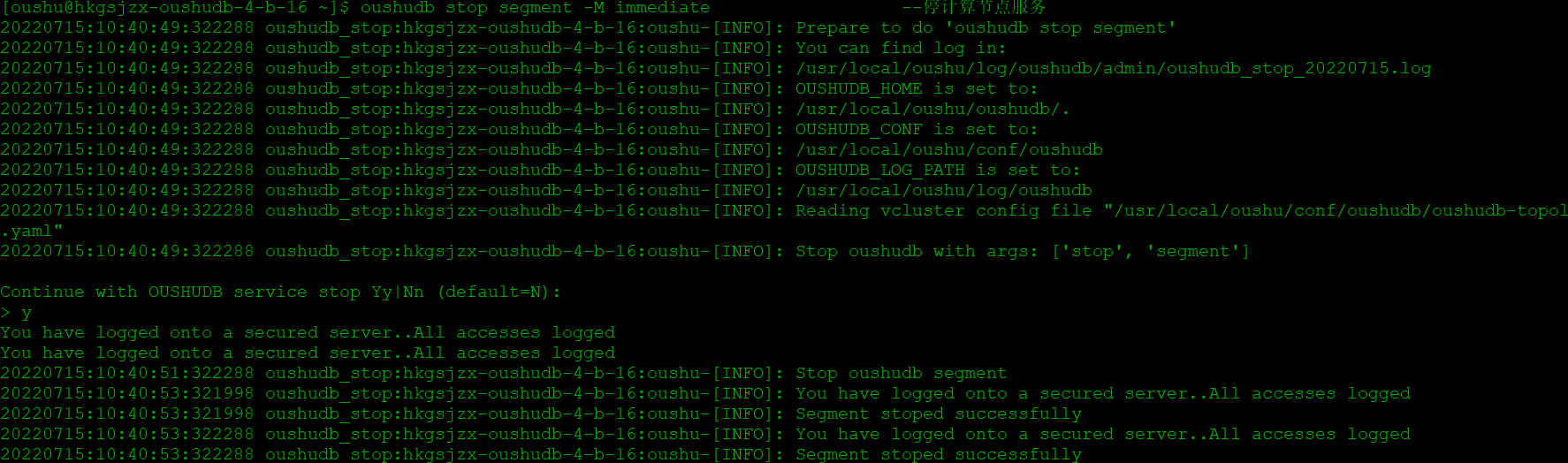
任务执行
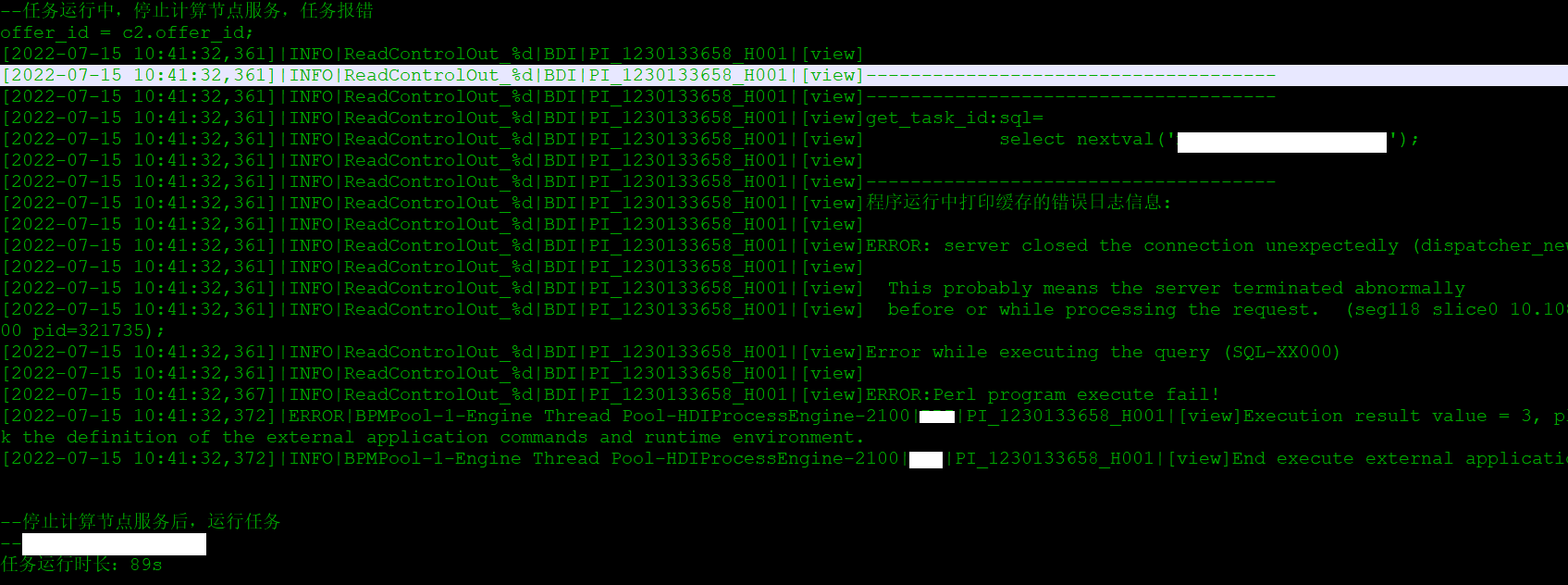
2.7、测试结论
1、业务能力
包括入接口和出接口业务;统计汇总;前台报表刷新;自动化元数据迁移和脚本翻译;数据集市数据下发。
结论:梧桐数仓满足业务功能要求。
2、平台能力
包括平台全域节点在线扩容;平台全域节点高可用;全局监控能力。
结论:梧桐数仓目前支持全域节点的在线扩容和高可用能力。
3、梧桐数仓建设方案
3.1、梧桐数仓组网
根据XX公司现网MPP数仓平台存在“同步流程多、主数仓扩展受限、开发效率低”等问题,需要一款弹性伸缩、存储共享、计算和存储解耦的MPP数据库产品。保障自主品牌MPP数据库快速应用落地、见到成效;完成数仓平台由“存算一体”向“存算分离”架构的演进,保持架构领先。
3.2、梧桐数仓规划
根据MPP数据仓库本地的使用情况和规划目标,XXX公司规划建设“1+N+1”存算分离数仓集群,第一个1表示:“一套物理集群”,“N” 表示:”多个计算逻辑子集群”;“第二个1”表示:“一套共享存储集群”。计算子集群包含主数仓、数据集市、开发库、考核库等子集群。计算子集群采用C3型服务器,存储集群其中数据节点采用B2型服务器,管理节点采用B1型服务器。
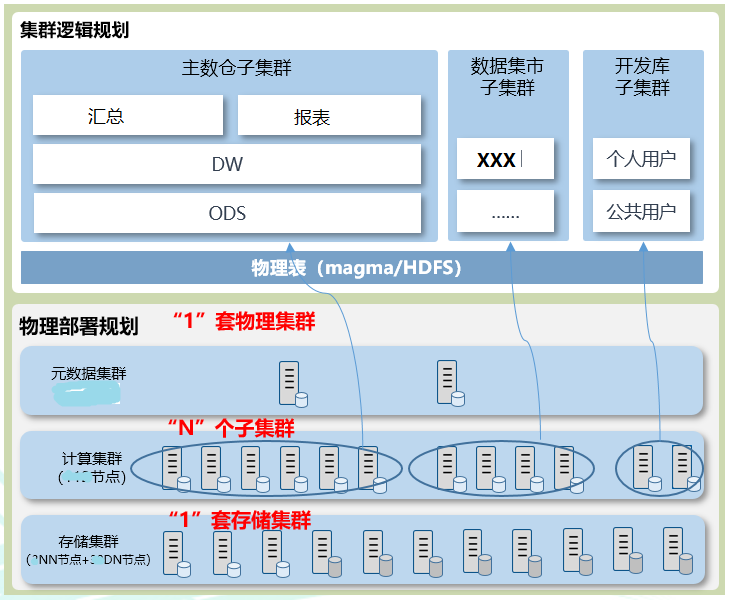
集群初步规划总计由上百台节点组成。分别包括管理节点+计算节点。具体如下表所示:
| 节点类型 | 规划节点数 | 功能说明 |
|---|---|---|
| 管理+计算节点 | XXX | 计算节点用于国产数仓的关联汇总、分组排序、数据聚合等操作的计算节点。 |
| 存储节点 | XX | 主要用于存储国产数仓HDFS数据的元数据信息;DN节点规划XX台,用于采用HDFS文件系统存储国产数仓数据。 |
3.3、元数据迁移
元数据范围包括:schema、用户、表结构、视图、序列、权限等对象,迁移具体步骤包含两部分:第一、差异识别:识别表字段使用差异;第二、通过自动转换工具迁移元数据,包含四小部分 : (1)提取源库创建语句;(2)自动转换;(3)脚本发布;(4)对象迁移;(5)异常处理。
3.3.1、差异识别
Vertica数据库与梧桐数据库数据类型比对
| Vertica数据库 | 梧桐数据库 |
|---|---|
| binary | Bytea |
| bytea | Bytea |
| boolean | Boolean |
| char | Char |
| varchar | Varchar |
| long varchar | Text |
| date | Date |
| time | Time |
| time with timezone | time with timezone |
| timestamp | Timestamp |
| timestamp with timezone | timestamp with timezone |
| interval | Interval |
| interval day to second | interval day to second |
| interval year to month | interval year to month |
| double precision | double precision |
| float | Float |
| float(n) | float(n) |
| float8 | float8 |
| real | real |
| integer | integer |
| int | int |
Oracle数据库与梧桐数据库数据类型比对
| Oracle | 梧桐数据库 |
|---|---|
| number | numeric |
| integer/number | bigint |
| binary_float | numeric/double |
| binary_double | double |
| char | char |
| varchar2 | varchar |
| nvarchar | varchar |
| nvarchar2 | varchar |
| nchar | char |
| blob | bytea |
| raw | bytea |
| long raw | bytea |
| clob | text |
| nclob | text |
| bfile | text |
| long | text |
3.3.2、元数据自动迁移工具
1、提取源库DDL 点击重新获取DDL,获取到Vertica/Oracle中的DDL语法。
2、自动转换: 点击全部转化将其转化为梧桐的DDL。
3、脚本发布: 全部成功后点击全部上传,发布到国产数仓客户端。
4、对象迁移: 在国产数仓客户端执行发布脚本,元数据对象应该到国产数仓。
5、异常处理: 对象迁移失败,进行人工判断,共性问题修改迁移工具,重新进行脚本转换。

3.4、业务数据迁移
因Vertica、Oracle迁移到梧桐数据库为异构平台,目前还没有库间高效直接数据迁移工具,需采用通过HDFS文件系统转接方式进行数据迁移。
3.4.1、Vertica迁移至梧桐数据库
Vertica数据迁移到梧桐数据库一般采用2种方案,第一、采用JDBC;第二采用Vertica专用工具。
- 1、JDBC
采用JDBC连接方式将Vertica数据库抽取到HDFS,梧桐数据库建立外部表映射到导出的HDFS文件,最好将外部表数据插入到内表。 - 2 Vertica专用工具
采用Vertica提供的导出工具Parallelexport或export to csv,将vertica数据按照节点导出到HDFS,梧桐数据库建立外部表映射到导出的HDFS文件,最好将外部表数据插入到内表。 - 3 性能指标对比
| 性能指标 | JDBC | 专用导出工具 | 描述 |
|---|---|---|---|
| 数据导出效率 | 慢 | 高效 | JDBC方式多并发大概实际测试50-100W/秒,而专用导出工具800-100W/秒 |
| 系统影响 | 严重 | 中 | JDBC方式需要较多的数据库连接资源,影响系统运行 |
| 通用性 | 普及 | 专用接口 | 针对不同的HDFS jdbc方式都可以适配,Vertica专用导出工具需要定制 |
通过对比,XX公司Vertica数据迁移到梧桐数据库采用第二种方案。
3.4.1.1、Vertica数据导出HDFS
1、以票据方式登录Vertica
vsql -h <IP> <port> -k <票据>
2、导出vertica数据到HDFS
vsql> select ParallelExport
( col1,col2,...,coln
using parameters cmd='
(source bigdata_env;
hadoop fs -put -f - hdfs:///tmp/data/xxx_20240610_`hostname`.dat
) 2>&1 > /dev/null',separator='∈'
) over(partition auto)
from xxx.xxxx
where col1=to_date('20240610','yyyymmdd');
|- |-
| exported [8190] |[host-name]
| exported [8447] |[host-name]
| exported [8051] |[host-name]
| ...... |......
| exported [10158] |[host-name]
(xxx rows)
export successful!
3.4.1.2、梧桐数据库外部表建立
1、登录梧桐数据库
psql -h <ip> -p <port> -U <用户名称> -d <dbname>
2、创建外部表
psql\> create readable external table ext_xxx
( col1 date,
......
coln bigint
)
LOCATION ( 'hdfs:///nameservie:port/path/xxx_yyyymmdd_*.dat' )
FORMAT 'TEXT' ( DELIMITER '∈' );
3.4.1.3、外部表加载到内部表
psql\> insert into xxx.xxx
select * from ext_xxx;
psql\> commit;
3.4.2、Oracle迁移至梧桐数据库
Oracle数据迁移到梧桐数据库采用MapReduce分片抽取加载梧桐数据库方案。具体功能架构如下图所示:

3.4.2.1、Oracle数据切片
为了提高抽取oracle效率,将oracle表进行均匀切片,多个抽取进程分别负责响应的切片数据,oracle均匀切片实现方式具体如下:
第一、查找抽取数据的区间
select *
from dba_extents
where owner = 'XXX'
and segment_name = 'TB_TEST1'
and partition_name='DATA_20240101';
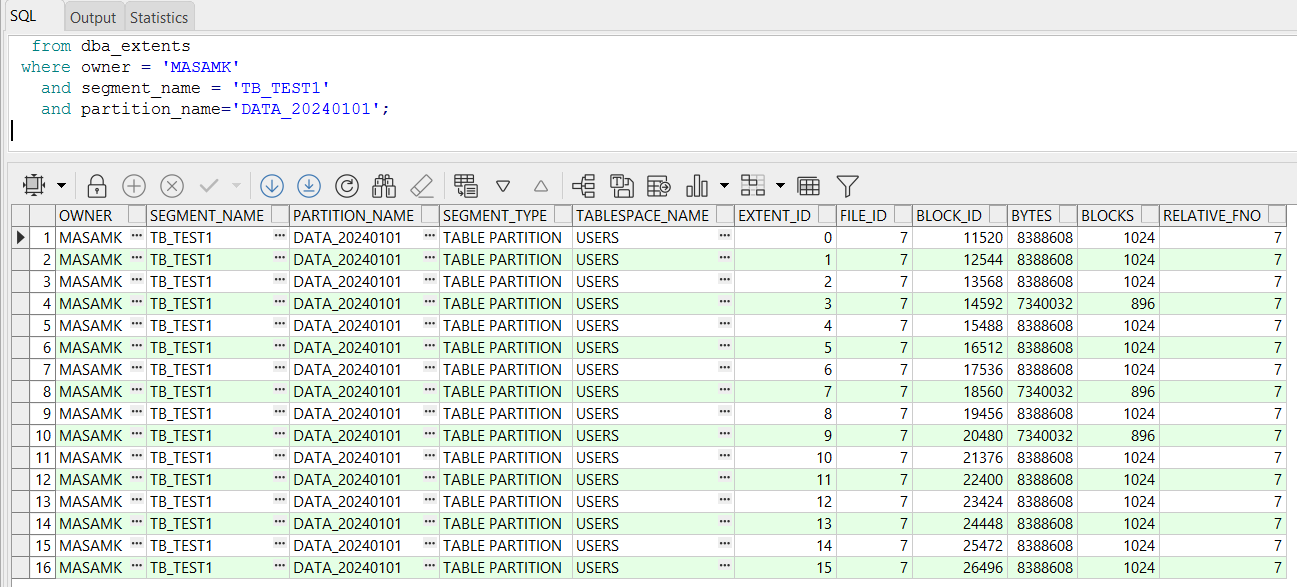
第二、按进程数进行数据切片
根据dbms_rowid.rowid_create计算出每个进程负责抽取的ROWID范围
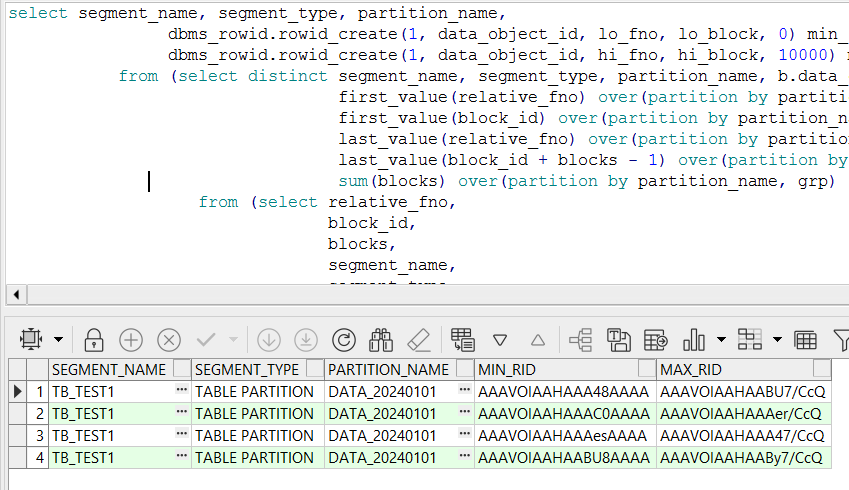
3.4.2.2、数据写入到HDFS
第一、提交MR job,分配每个map负责抽取的范围
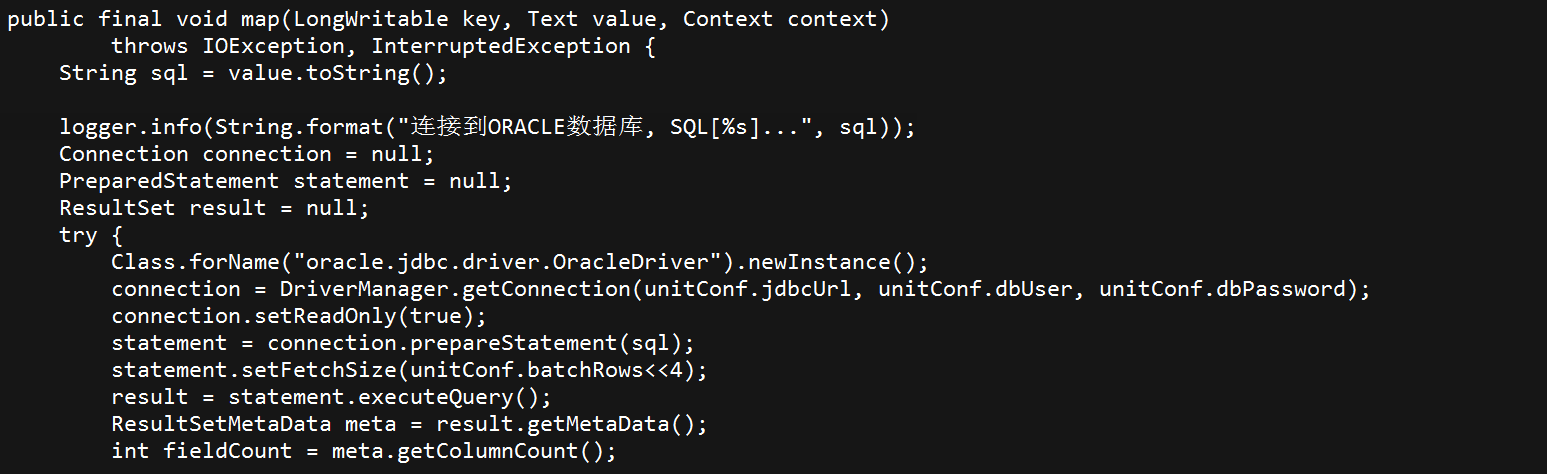
第二、Mapper task写入HDFS
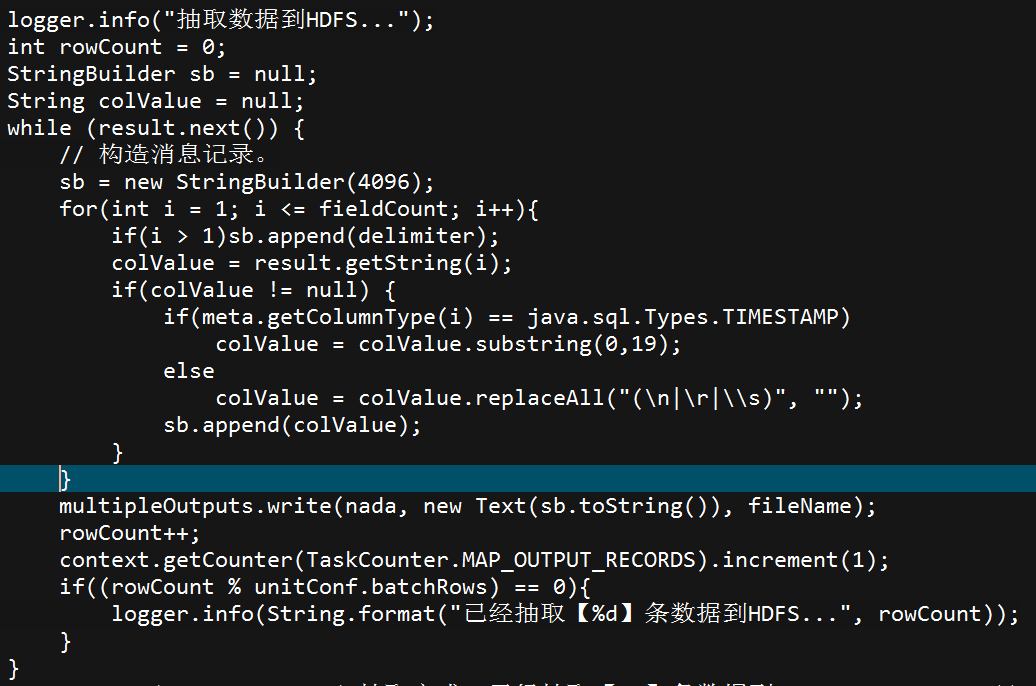
3.4.2.3、创建梧桐数据库外部表
1、登录梧桐数据库
psql -h <ip> -p <port> -U <用户名称> -d <dbname>
2、创建外部表
psql\> create readable external table ext_xx_test1
( col1 date,
......
col2 number(12)
)
LOCATION ( 'hdfs:///nameservice:port/path/xx_*.dat' )
FORMAT 'TEXT' ( DELIMITER '∈' );
3.4.2.4、数据加载到正式表
insert into xxx.xx_test1 select * from ext_xx_test1;
4、梧桐数仓能力完善
4.1、FDW功能完善
- 支持SQL访问Oracle、Vertica、hdfs文本文件的能力
PosttgreSQL FDW能力已经较为完善,目前已具备访问主流关系型数据库如:Oracle、MySQL、SQL Server;外部文件:CSV等。现网数据迁移由Oracle和Vertica迁移至梧桐数据库,由于梧桐数据库目前还不具备该能力,导致迁移工作量加大至少40%。
- 支持SQL访问其他梧桐数据库能力
按照集团制定的V6.0版本升级方案,重新部署一个新的数据库集群,数据库间的数据库同步如果采用hdfs文件中转效率及其低下,需要梧桐数据库之间的访问能力。
4.2、分级存储能力的完善
梧桐数仓目前采用HDFS作为存储,虽然能够实现对接EC存储实现分级存储方案,但是需要业务进行较大的改动,例如历史分区的数据存储到分级存储需要重新建表,然后将数据库迁移到分级存储中,造成了业务流程不连续。建议在业务模型不进行变动的前提下,历史数据能够自动或手动方式移动到分级存储中。
