




GoldenDb数据迁移梧桐云原生分析型数据库技术解决方案
1、概述
随着数据库国产化不断推进,某某公司有部分重要接口数据,源端使用的是GoldenDb数据库。如何快速高效将这部分GoldenDb数据库中的数据加载到梧桐云原生分析型数据库,将成为梧桐云原生分析型数据库承载这部分GoldenDb数据业务的关键因素。
2、数据迁移方案
GoldenDb数据抽取到梧桐云原生分析型数据库采用MapReduce Hash分布方式,将GoldenDb数据库中的表数据抽取并加载到梧桐云原生分析型数据库。具体功能架构如下图所示:
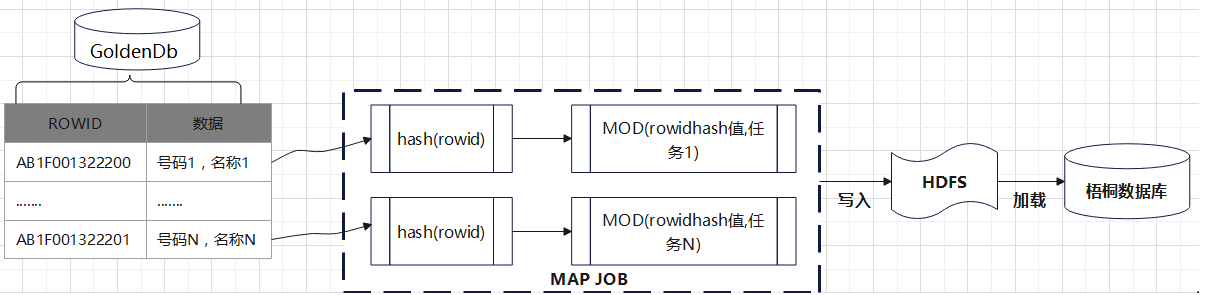
2.1 数据HASH
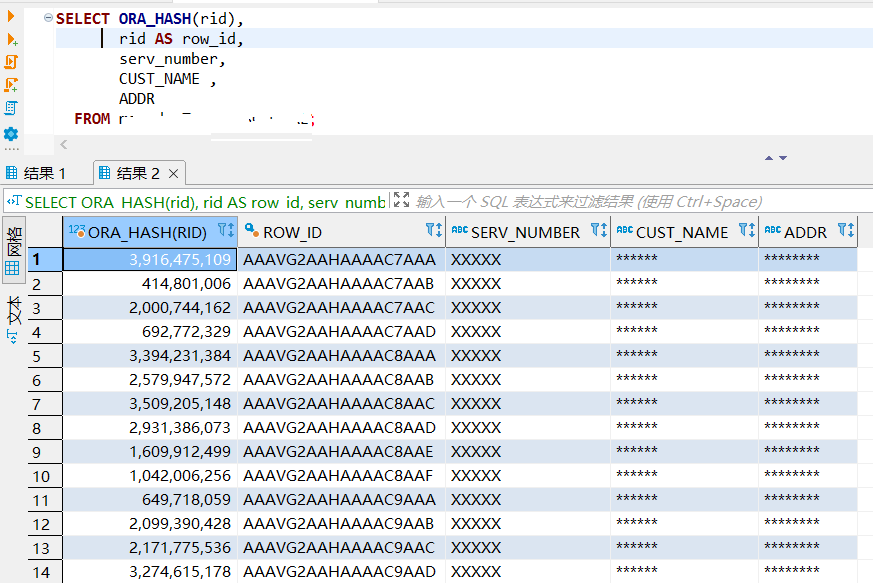
计算GoldenDb ROWID散列值,GoldenDb数据库兼容了Oracle数据库特性,支持ROWID,采用HASH函数计算ROWID的散列值,如下图所示:
select * FROM xxxxxx.xx_xx_xx_xxxx;
2.2 数据切片
按照进程数目进行数据切片,每一个进程负责抽取相对应的切片数据,多进程抽取,提升数据抽取效率。
代码实现:
public static void main (String[] args){
…
//遍历入参
for (int i=0;i != args.length;i++){
String key = args[i].Substring(0,pos);
String value = new String(args[i].Substring(pos+i).trim());
…
//取设定的 map(分片) 个数
if(key.equalsIgnoreCase(“map”))maps=Integer.parseInt(value);
…
}
…
//生成各个Map任务的SQL语句;
BufferedOutputStream bos = new BufferedOutputStream(fs.create(inputPath));
if(cnt <= 100000 || maps == 1) {
maps = 1;
bos.write(sql_text.getBytes(), 0, sql_text.length());
}
else for(int i = 0; i != maps ; i++) {
if(sql_text != null ){
Matcher m = pattern.matcher(sql_text);
if(m.find())sql = sql_text + " where ";
else sql = sql_text + " and ";
}
else {
sql = String.format("select /*+ parallel(6) */ %s from %s.%s where ", columns, unitConf.tableUser, unitConf.tableName);
if(whereString != null && whereString.length() > 0)
sql = sql + whereString + " and ";
}
sql = sql + “nvl(mod(ora_hash(” + keyColumn + "), " + maps + "), 0) = " + i + “\n”;
bos.write(sql.getBytes(), 0, sql.length());
}
bos.close();
}
日志显示:
2.3 数据写入HDFS
1、首先连接到 GoldenDb 数据库
代码实现:
logger.info(“连接到Goldendb数据库…”);
Class.forName(“com.goldendb.jdbc.Driver”).newInstance();
connection = DriverManager.getConnection(unitConf.jdbcUrl, unitConf.dbUser, unitConf.dbPassword);
connection.setReadOnly(true);
日志显示:

2、执行SQL
代码实现:
logger.info(String.format(“执行SQL[%s]…”, sql));
statement = connection.prepareStatement(sql);
statement.setFetchSize(unitConf.batchRows<<4);
result = statement.executeQuery();
ResultSetMetaData meta = result.getMetaData();
int fieldCount = meta.getColumnCount();
日志显示:

3、数据写入HDFS
代码实现:
logger.info(“发送数据到HDFS…”);
int rowCount = 0;
StringBuilder sb = new StringBuilder(1048576);
String colValue = null;
while (result.next()) {
// 构造消息记录。
for(int i = 1; i <= fieldCount; i++){
if(i > 1)sb.append(delimiter);
colValue = result.getString(i);
if(colValue != null) {
if(meta.getColumnType(i) == java.sql.Types.TIMESTAMP)
colValue = colValue.substring(0,19);
else
colValue = colValue.replaceAll("(\n|\r|\s)", “”);
sb.append(colValue);
}
}
sb.append(’\n’);
rowCount++;
if((rowCount % unitConf.batchRows) == 0){
String messageStr = sb.substring(0, sb.length()-1);
multipleOutputs.write(nada, new Text(messageStr), fileName);
sb = new StringBuilder(1048576);
logger.debug(String.format(“已经发送【%d】条数据到HDFS…”, rowCount));
}
}
if((rowCount % unitConf.batchRows) != 0){
String messageStr = sb.substring(0, sb.length()-1);
multipleOutputs.write(nada, new Text(messageStr), fileName);
logger.debug(String.format(“Message:%s\n”, messageStr));
}
logger.info(String.format(“发送数据到Hdfs成功,已经发送记录数【%d】”, rowCount));
logger.info(“移动文件到结果目录…”);
日志显示:

2.4 数据装载梧桐云原生分析型数据库
1、登录梧桐云原生分析型数据库
psql -h-p -U <用户名称> -d
2、创建外部表
psql> create readable external table ext_tb_???
( ??? date,
…
??? text
)
LOCATION ( 'hdfs:///xxxx:???/???/???/<tb_name>*.dat’) ???;
FORMAT ‘TEXT’ ( DELIMITER );
3 外部表加载到内部表
insert into <模式名>.<表名> select * from ext_tb
