





本文字数:13198;估计阅读时间:33 分钟

我们一向对开放数据挑战充满热情,所以当发现 MTA(城市交通管理局)在其官网发起了这样的挑战时,便跃跃欲试,积极参与。我们专注于闸机数据集,以分析纽约市的地铁使用情况,并在我们新的数据游乐场中免费开放此数据供用户查询。
MTA 负责纽约市的公共交通系统,涵盖地铁、公交和通勤铁路,每天服务数百万乘客。MTA 开放数据挑战是为期一个月的竞赛,面向开发者和数据爱好者,鼓励他们利用 MTA 的数据集创造性地开发项目,比如网页应用、数据可视化或报告。参赛作品需使用 data.ny.gov 上至少一个数据集,评审标准包括创意、实用性、执行效果及透明度。
MTA 提供了 176 个数据集供参赛者使用,大部分数据集较小,通常只有几百行。尽管这些数据资源极具价值,但其体量较小,难以充分发挥 ClickHouse 的优势。
ClickHouse 是专为大规模数据分析设计的 OLAP 数据库,因此我们选择了体量最大的闸机数据集进行探索。这个数据集汇总了多年来纽约市地铁站闸机的进出记录,约有 1 亿行数据,便于分析城市人流的流动情况。尽管该数据集看似简单,但为了清理并使之具备实际应用价值,我们付出了远超预期的努力。
该数据集涵盖 2014 至 2022 年的数据。针对最近几年的数据,有一个经过清理的版本可供使用,我们也加载了此版本并提供了示例查询。不过,为了完整呈现所有数据,我们在本文中将重点关注历史数据。
本文将详细介绍加载和清理这些数据的步骤,帮助大家在自己的 ClickHouse 实例中复现这些操作。这将展示 ClickHouse 在数据工程方面的关键功能,许多操作和查询同样适用于其他数据集。
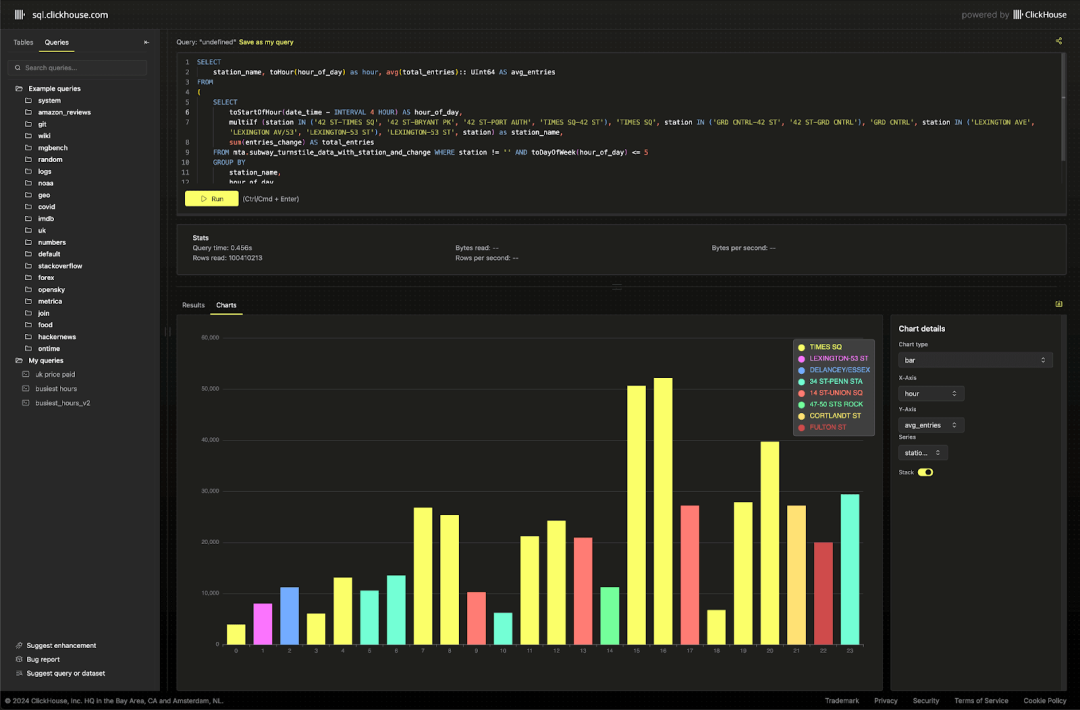
对于只关心最终数据集的用户,我们已将其加载到新的 ClickHouse playground,您可以在其中尝试超过 220 个查询和 35 个数据集!如需贡献新的查询和数据集,欢迎访问我们的 demo 仓库。
本文的所有步骤都可以使用 clickhouse-local 复现。clickhouse-local 是 ClickHouse 的轻量版,非常适合开发人员在无需安装完整数据库的情况下,通过 SQL 快速处理本地和远程文件。

为了简化加载,我们将闸机数据(以 TSV 文件格式)存储在一个公共存储桶中。通过简单的 S3 查询就可以查看列信息,ClickHouse 会自动推断列的类型。
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/mta/*.tsv')SETTINGS describe_compact_output = 1┌─name───────────────────────────────────────────────────────┬─type────────────────────┐│ C/A │ Nullable(String) ││ Unit │ Nullable(String) ││ SCP │ Nullable(String) ││ Station │ Nullable(String) ││ Line Name │ Nullable(String) ││ Division │ Nullable(String) ││ Date │ Nullable(DateTime64(9)) ││ Time │ Nullable(String) ││ Description │ Nullable(String) ││ Entries │ Nullable(Int64) ││ Exits │ Nullable(Int64) │└────────────────────────────────────────────────────────────┴─────────────────────────┘11 rows in set. Elapsed: 0.309 sec.
抽样数据并查看数据集描述后可以发现,每行数据记录了某一时间点的闸机进出人次计数。描述显示这些计数的数据是周期性报告的,统计的是上一个时间段内的情况。以下是直接在 S3 中执行的查询示例:
SELECT *FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/mta/*.tsv')LIMIT 1FORMAT VerticalRow 1:──────C/A: A002Unit: R051SCP: 02-00-00Station: LEXINGTON AVELine Name: NQR456Division: BMTDate: 2014-12-31 00:00:00.000000000Time: 23:00:00Description: REGULAREntries: 4943320Exits : 16747361 rows in set. Elapsed: 1.113 sec.
为简化处理并避免重复下载数据,我们可以将其加载到本地表中。使用推断的表结构创建该表并加载数据,命令如下。
CREATE TABLE subway_transits_2014_2022_rawENGINE = MergeTreeORDER BY tuple() EMPTYAS SELECT *FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/mta/*.tsv')
这会基于架构创建一个空表,我们将其作为数据探索的临时表,暂不使用排序键。数据加载可以简单地通过 INSERT INTO SELECT 完成:
INSERT INTO subway_transits_2014_2022_rawSETTINGS max_insert_threads = 16, parallel_distributed_insert_select = 2SELECT *FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/mta/*.tsv')SETTINGS max_insert_threads = 16, parallel_distributed_insert_select = 20 rows in set. Elapsed: 39.236 sec. Processed 94.88 million rows, 13.82 GB (2.42 million rows/s., 352.14 MB/s.)Peak memory usage: 1.54 GiB.SELECT count()FROM subway_transits_2014_2022_raw┌──count()─┐│ 94875892 │ -- 94.88 million└──────────┘1 row in set. Elapsed: 0.002 sec.
为加快加载速度,我们应用了一些简单的优化,比如使用 s3Cluster 函数。详情可参考《优化 S3 插入和读取性能指南》。上述时间(包括之后的处理时间)是在我们 sql.clickhouse.com 环境中测得的,该环境包含 3 个节点,每个节点有 30 个虚拟 CPU。您的性能可能会有所不同,但考虑到数据集大小,性能将主要取决于网络连接。
检查表结构后,我们发现了多个优化空间。
SHOW CREATE TABLE subway_transits_2014_2022_rawCREATE TABLE subway_transits_2014_2022_raw(`C/A` Nullable(String),`Unit` Nullable(String),`SCP` Nullable(String),`Station` Nullable(String),`Line Name` Nullable(String),`Division` Nullable(String),`Date` Nullable(DateTime64(9)),`Time` Nullable(String),`Description` Nullable(String),`Entries` Nullable(Int64),`Exits ` Nullable(Int64))ENGINE = SharedMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')ORDER BY tuple()
首先,列名建议使用小写且无特殊字符。此外,Nullable 类型非必需,会增加额外的空间开销以区分空值和空内容,应尽量避免使用。其次,日期和时间应合并为一个 date_time 列——ClickHouse 支持丰富的日期时间函数,可基于时间、日期或两者来查询 DateTime 类型。
快速查看数据的列描述后,我们还发现了一些优化空间。进站和出站值不会超过 Int32,若超出会回绕(需进一步处理),且仅为正值。大多数字符串列的基数也较低,可通过简单查询来验证:
SELECTuniq(`C/A`),uniq(Unit),uniq(SCP),uniq(Station),uniq(`Line Name`),uniq(Division),uniq(Description)FROM subway_transits_2014_2022_rawFORMAT VerticalQuery id: c925aaa4-6302-41e4-9f1e-1ba88587c3bcRow 1:──────uniq(C/A): 762uniq(Unit): 476uniq(SCP): 334uniq(Station): 579uniq(Line Name): 130uniq(Division): 7uniq(Description): 21 row in set. Elapsed: 0.959 sec. Processed 94.88 million rows, 10.27 GB (98.91 million rows/s., 10.71 GB/s.)Peak memory usage: 461.18 MiB.
因此,将这些列设置为 LowCardinality(String) 类型更合理,这样可以实现更高的压缩效率和更快的查询速度!
纽约市民对线路命名系统应该很熟悉。列 Line Name 表示检票闸机所服务的线路,例如:
“停靠该站的地铁线路,如 456”
这里 456 代表 4、5 和 6 号线。我们观察数据后发现,这些线路并没有保持一致的顺序。例如,456NQR 与 NQR456 实际上表示相同的线路组合。
SELECT `Line Name`FROM subway_transits_2014_2022_rawWHERE (`Line Name` = 'NQR456') OR (`Line Name` = '456NQR')LIMIT 1 BY `Line Name`┌─Line Name─┐│ NQR456 ││ 456NQR │└───────────┘2 rows in set. Elapsed: 0.059 sec. Processed 94.88 million rows, 1.20 GB (1.60 billion rows/s., 20.20 GB/s.)Peak memory usage: 105.88 MiB.
为了简化查询过程,我们将该字符串转为 Array(LowCardinality(String)) 类型,并对其中的线路排序。
最后,选择 station 和 date_time 作为排序键是一个合理的选择。
因此,表的结构如下:
CREATE TABLE subway_transits_2014_2022_v1(`ca` LowCardinality(String),`unit` LowCardinality(String),`scp` LowCardinality(String),`station` LowCardinality(String),`line_names` Array(LowCardinality(String)),`division` LowCardinality(String),`date_time` DateTime32,`description` LowCardinality(String),`entries` UInt32,`exits` UInt32)ENGINE = MergeTreeORDER BY (station, date_time)
接下来,我们可以通过从之前的 subway_transits_2014_2022_raw 表中读取数据,使用 SELECT 语句转换行数据来加载这些信息。
INSERT INTO subway_transits_2014_2022_v1 SELECT`C/A` AS ca,Unit AS unit,SCP AS scp,Station AS station,arraySort(ngrams(assumeNotNull(`Line Name`), 1)) AS line_names,Division AS division,parseDateTimeBestEffort(trimBoth(concat(CAST(Date, 'Date32'), ' ', Time))) AS date_time,Description AS description,Entries AS entries,`Exits ` AS exitsFROM subway_transits_2014_2022_rawSETTINGS max_insert_threads = 160 rows in set. Elapsed: 4.235 sec. Processed 94.88 million rows, 14.54 GB (22.40 million rows/s., 3.43 GB/s.)
我们发现了几个主要问题,接下来逐一说明。
挑战 1:累积值和异常值
根据 MTA 数据【https://data.ny.gov/api/views/ug6q-shqc/files/29edbef3-268e-461d-95f1-374b1c8a6f9d?download=true&filename=MTA_SubwayTurnstileUsageData2015_Overview.pdf】的详细描述,这些数据中存在一些质量问题,首先就是进出人数的数值是累积的。
> MTA 每隔四小时提供一次数据,记录了每个检票闸机的进出人数累积值,类似于里程表的读数。各车站的间隔时间可能不同,因为需要分批传输以防止系统过载。车站的审计时间设在每日的 00-03 点之间开始,此后每隔四小时一次。通过与之前的读数进行比较,可以计算出每个时段内通过检票闸机的进出人数。
这些累积值的使用比较困难,需要进行查询来计算每个检票闸机的时间序列变化。由于数据每 4 小时传输一次,这对特定时间段的统计仍显不精确,这也是我们无法完全解决的问题,因此低于该时间粒度的统计数据可能会存在偏差。
此外,数据还存在一些明显的质量问题:
> 检票闸机的审计并非总是每四小时一次,有时计数会回退、进出计数器周期性重置,各检票闸机的时间戳也不同。此外,数据为 10 位数,溢出后会归零。
理想情况下,我们希望计算每一行的进出人数变化,即通过与上一个时间点的差异进行计算,而要做到这一点,需要可靠地识别每个检票闸机。
虽然每个闸机有一个 scp 标识符,但它在各车站并不唯一。我们可以使用 scp、ca(车站的工作亭标识符)和 unit(车站的远程单元 ID)组合来识别具体车站。
要计算每个检票闸机的进出变化,我们可以使用窗口函数。以下代码计算每行的 entries_change 和 exits_change 列。
WITH 1000 AS threshold_per_hourSELECT*,any(date_time) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_date_time,any(entries) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_entries,any(exits) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_exits,dateDiff('hour', p_date_time, date_time) AS hours,if((entries < p_entries) OR (((entries - p_entries) if(hours > 0, hours, 1)) > threshold_per_hour), 0, entries - p_entries) AS entries_change,if((exits < p_exits) OR (((exits - p_exits) if(hours > 0, hours, 1)) > threshold_per_hour), 0, exits - p_exits) AS exits_changeFROM subway_transits_2014_2022_v1ORDER BYca ASC,unit ASC,scp ASC,date_time ASC
查询的关键点概述:
1. 数据按 ca、unit、scp 和 date_time 列(升序)排序,以确保每个检票闸机的记录按时间顺序排列,从而便于计算变化量。
2. 查询函数通过 PARTITION BY ca、unit、scp 为每个检票闸机创建窗口,并在每个窗口内按时间顺序排序。ROWS BETWEEN 1 PRECEDING AND CURRENT ROW 子句用于生成 p_entries 和 p_exits 列,这两列包含每行上一次的进出人数值,上一个时间点则存储在 p_date_time 列。
3. entries_change 和 exits_change 列存储的是当前行和前一行之间的进出人数变化。如果该变化为负数,返回值设为 0,假设这是由于计数器回滚。此外,数据分析显示存在异常高的值,例如一个小时内出现 10,000 人通过某个检票闸机的记录。若变化值超过合理阈值(每小时 1000 人),也会返回 0 以过滤掉异常值。我们选定的阈值基于实际通过率的估算(约每分钟 10-15 人)。这种方法虽然不完美,但可结合历史趋势进行改进。
挑战 2:站名缺失与不一致
虽然各年度数据集使用了相同架构,但 2022 年的数据集【https://data.ny.gov/Transportation/MTA-Subway-Turnstile-Usage-Data-2022/k7j9-jnct/about_data】缺少站名。
SELECT toYear(date_time) AS yearFROM mta.subway_transits_2014_2022_v1WHERE station = ''GROUP BY year┌─year─┐1. │ 2022 │└──────┘1 row in set. Elapsed: 0.016 sec. Processed 10.98 million rows, 54.90 MB (678.86 million rows/s., 3.39 GB/s.)Peak memory usage: 98.99 MiB.
为提高数据集的可用性,我们可以基于独特的检票闸机 ID(由早期数据填充)来补充 2022 年的站名。
然而,通过分析发现,即便同一检票闸机的站名也常不一致。例如,“大道”一词的拼写有时为 AV,有时为 AVE,导致同一站点被记录多次。
SELECT DISTINCT stationFROM subway_transits_2014_2022_v1WHERE station LIKE '%AV%'ORDER BY station ASCLIMIT 10FORMAT PrettyCompactMonoBlock┌─station──────┐│ 1 AV ││ 1 AVE ││ 138 ST-3 AVE ││ 14 ST-6 AVE ││ 149 ST-3 AVE ││ 18 AV ││ 18 AVE ││ 2 AV ││ 2 AVE ││ 20 AV │└──────────────┘10 rows in set. Elapsed: 0.024 sec. Processed 36.20 million rows, 41.62 MB (1.53 billion rows/s., 1.75 GB/s.)Peak memory usage: 26.68 MiB.
若能建立检票闸机与站名的映射,可以通过统一选择一种名称(如最长名称)并重新映射数据来解决简单的拼写不一致问题。需注意,这无法处理更复杂的映射问题,例如将“42 ST-TIMES SQ”与“TIMES SQ-42 ST”统一映射为“TIMES SQ”。我们可以暂时在查询时处理这些更复杂的情况。
为存储该映射关系,可以使用字典。这种内存结构允许通过 (ca, unit, scp) 的元组查找站名。以下查询可填充字典,生成分配给每个 (ca, unit, scp) 的唯一站名列表,并按长度排序,选取最长的名称。使用 groupArrayDistinct 函数创建列表并完成排序。
CREATE DICTIONARY station_names(`ca` String,`unit` String,`scp` String,`station_name` String)PRIMARY KEY (ca, unit, scp)SOURCE(CLICKHOUSE(QUERY $query$SELECTca,unit,scp,arrayReverseSort(station -> length(station), groupArrayDistinct(station))[1] AS station_nameFROM subway_transits_2014_2022_v1WHERE station != ''GROUP BYca,unit,scp$query$))LIFETIME(MIN 0 MAX 0)LAYOUT(complex_key_hashed())
有关字典的详细配置和类型,请参考字典文档。
使用 dictGet 函数可以高效检索站名。例如:
SELECT dictGet(station_names, 'station_name', ('R148', 'R033', '01-04-01'))┌─name───────────┐│ 42 ST-TIMES SQ │└────────────────┘1 row in set. Elapsed: 0.001 sec.
请注意,首次调用字典时,速度可能较慢,具体取决于数据是急加载还是在首次请求时才懒加载(lazy_load)。这可以通过设置 dictionaries_lazy_load 配置项控制。
最终数据的整合方案
现在,我们可以结合窗口函数和字典查询来生成最终数据。思路简单:在 v1 表上使用窗口函数和 dictGet 函数执行查询,将结果插入到一个新表中。我们的最终表结构如下:
CREATE TABLE mta.subway_transits_2014_2022_v2(`ca` LowCardinality(String),`unit` LowCardinality(String),`scp` LowCardinality(String),`line_names` Array(LowCardinality(String)),`division` LowCardinality(String),`date_time` DateTime,`description` LowCardinality(String),`entries` UInt32,`exits` UInt32,`station` LowCardinality(String),`entries_change` UInt32,`exits_change` UInt32)ENGINE = MergeTreeORDER BY (ca, unit, scp, date_time)
使用 INSERT INTO SELECT:
INSERT INTO mta.subway_transits_2014_2022_v2 WITH 2000 AS threshold_per_hour SELECTca, unit, scp, line_names, division, date_time, description, entries, exits,dictGet(station_names, 'station_name', (ca, unit, scp)) as station,entries_change, exits_changeFROM(SELECT*,any(date_time) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_date_time,any(entries) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_entries,any(exits) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_exits,dateDiff('hour', p_date_time, date_time) AS hours,if((entries < p_entries) OR (((entries - p_entries) if(hours > 0, hours, 1)) > threshold_per_hour), 0, entries - p_entries) AS entries_change,if((exits < p_exits) OR (((exits - p_exits) if(hours > 0, hours, 1)) > threshold_per_hour), 0, exits - p_exits) AS exits_changeFROM subway_transits_2014_2022_v1ORDER BYca ASC,unit ASC,scp ASC,date_time ASC) SETTINGS max_insert_threads=160 rows in set. Elapsed: 24.305 sec. Processed 94.88 million rows, 2.76 GB (3.90 million rows/s., 113.67 MB/s.)
最终表结构:
SELECT *FROM mta.subway_transits_2014_2022_v2LIMIT 1FORMAT VerticalRow 1:──────ca: A002unit: R051scp: 02-00-00line_names: ['4','5','6','N','Q','R']division: BMTdate_time: 2014-01-02 03:00:00description: REGULARentries: 4469306exits: 1523801station: LEXINGTON AVEentries_change: 0exits_change: 01 rows in set. Elapsed: 0.005 sec.
以下查询可以在 ClickHouse playground 中运行。我们为每个查询提供了默认的图表以便入门。
如果您有更多针对 MTA 数据集或其他数据集的查询建议或改进思路,欢迎联系我们,或在示例库的仓库【https://github.com/ClickHouse/sql.clickhouse.com】中提交问题。
首先,我们确认热门车站是否与官方数据一致。以 2018 年的数据为例:
SELECTstation,sum(entries_change) AS total_entries,formatReadableQuantity(total_entries) AS total_entries_readFROM mta.subway_transits_2014_2022_v2WHERE toYear(date_time) = '2018'GROUP BY stationORDER BY sum(entries_change) DESCLIMIT 10
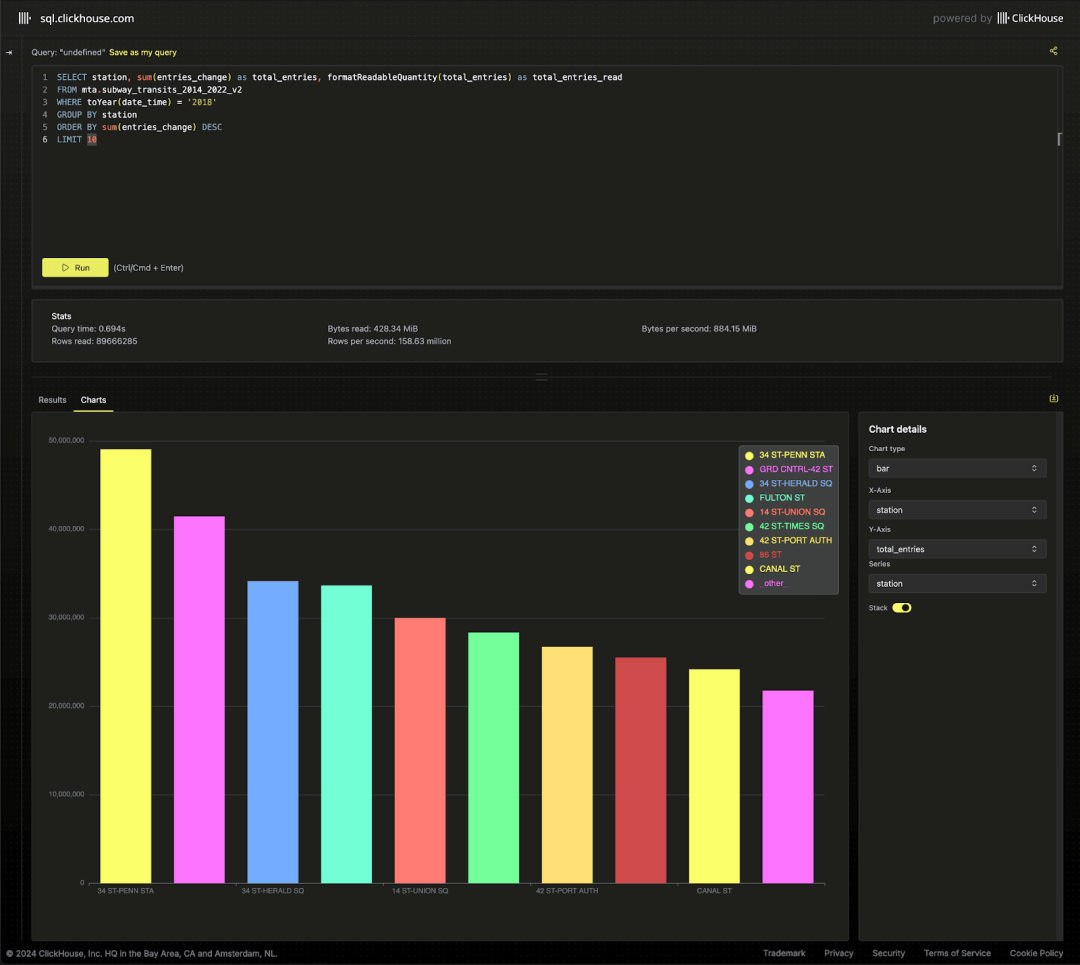
我们的结果质量受到数据嘈杂度和异常值处理方法的影响,但总体上与 MTA 报告的数据一致。请注意,数据集中一些站点有多个入口名称,例如 '42 ST-TIMES SQ' 和 'TIMES SQ-42 ST' 均表示 'TIMES SQ'。我们将名称清理作为待办事项,目前通过查询条件进行处理。
查看整个期间内前十站点的客流趋势时,COVID 疫情的影响显而易见。
SELECTstation,toYear(date_time) AS year,sum(entries_change) AS total_entriesFROM mta.subway_transits_2014_2022_v2WHERE station IN (SELECT stationFROM mta.subway_transits_2014_2022_v2GROUP BY stationORDER BY sum(entries_change) DESCLIMIT 10)GROUP BYyear,stationORDER BY year ASC
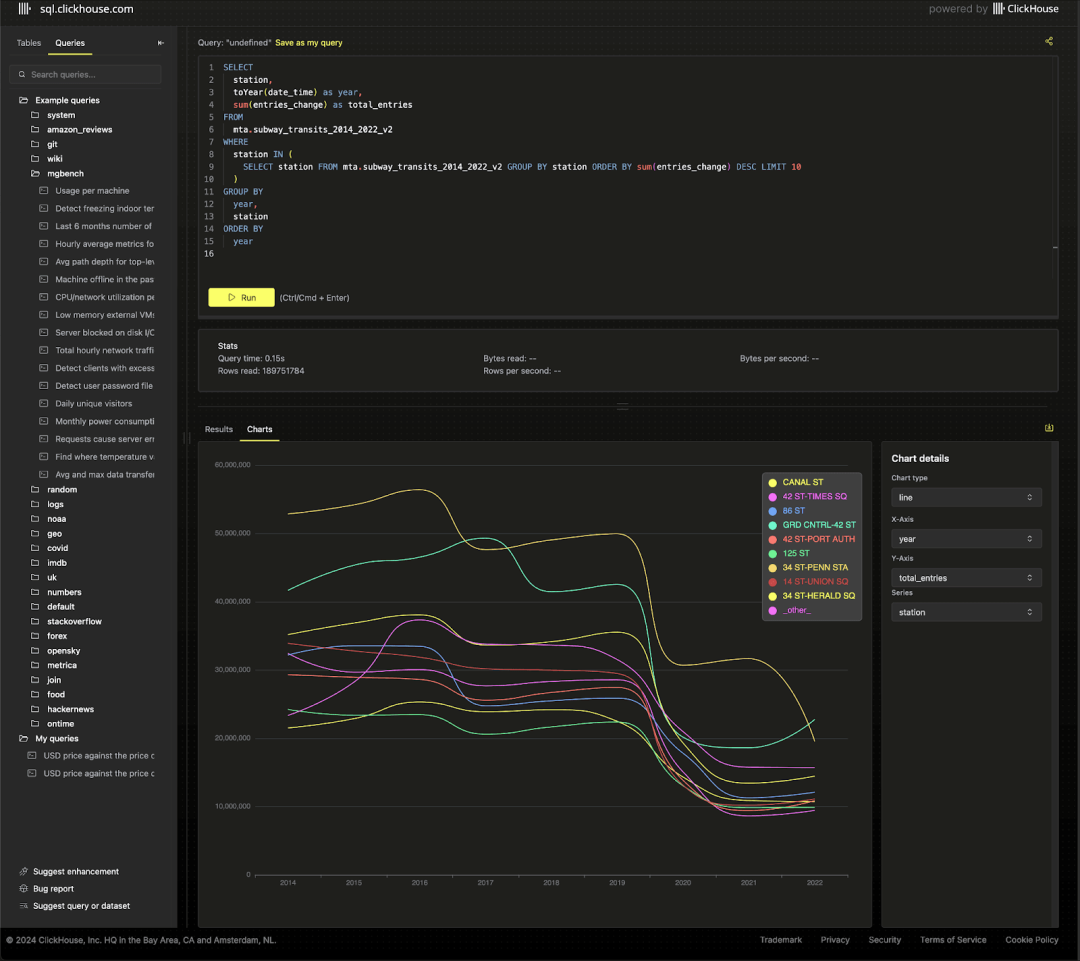
尽管经过处理,数据仍然较嘈杂,并存在一些明显的异常值,需进一步清理。欢迎提供改进方法。2022 年的交通数据则相对更可靠,质量较高。我们已将其加载至 transit_data 表中,并提供了一些示例查询。
通过这些数据,可以观察到各站点在高峰时段的通勤模式。
SELECTstation_complex,toHour(hour_of_day) AS hour,CAST(avg(total_entries), 'UInt64') AS avg_entriesFROM(SELECTtoStartOfHour(transit_timestamp) AS hour_of_day,station_complex,sum(ridership) AS total_entriesFROM mta.transit_dataWHERE toDayOfWeek(transit_timestamp) <= 5GROUP BYstation_complex,hour_of_day)GROUP BYhour,station_complexORDER BYhour ASC,avg_entries DESCLIMIT 3 BY hour
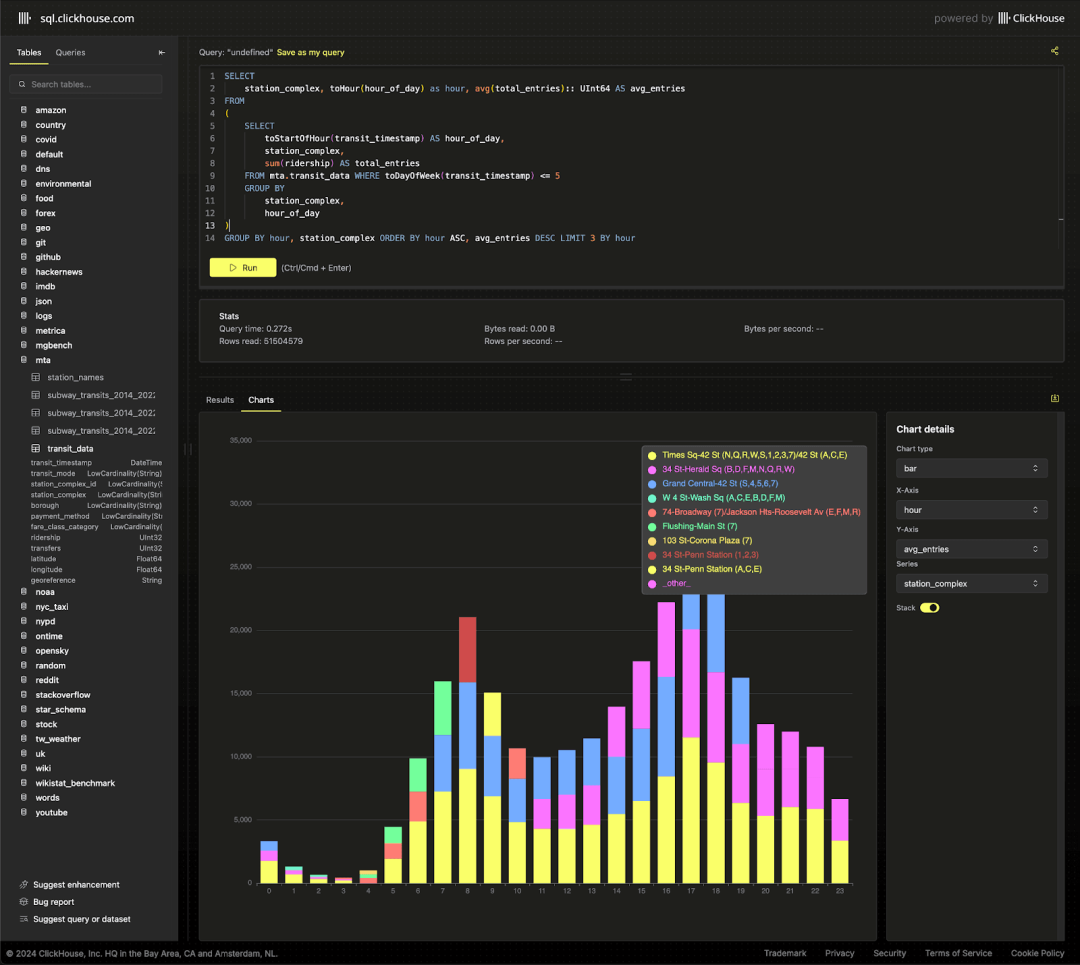
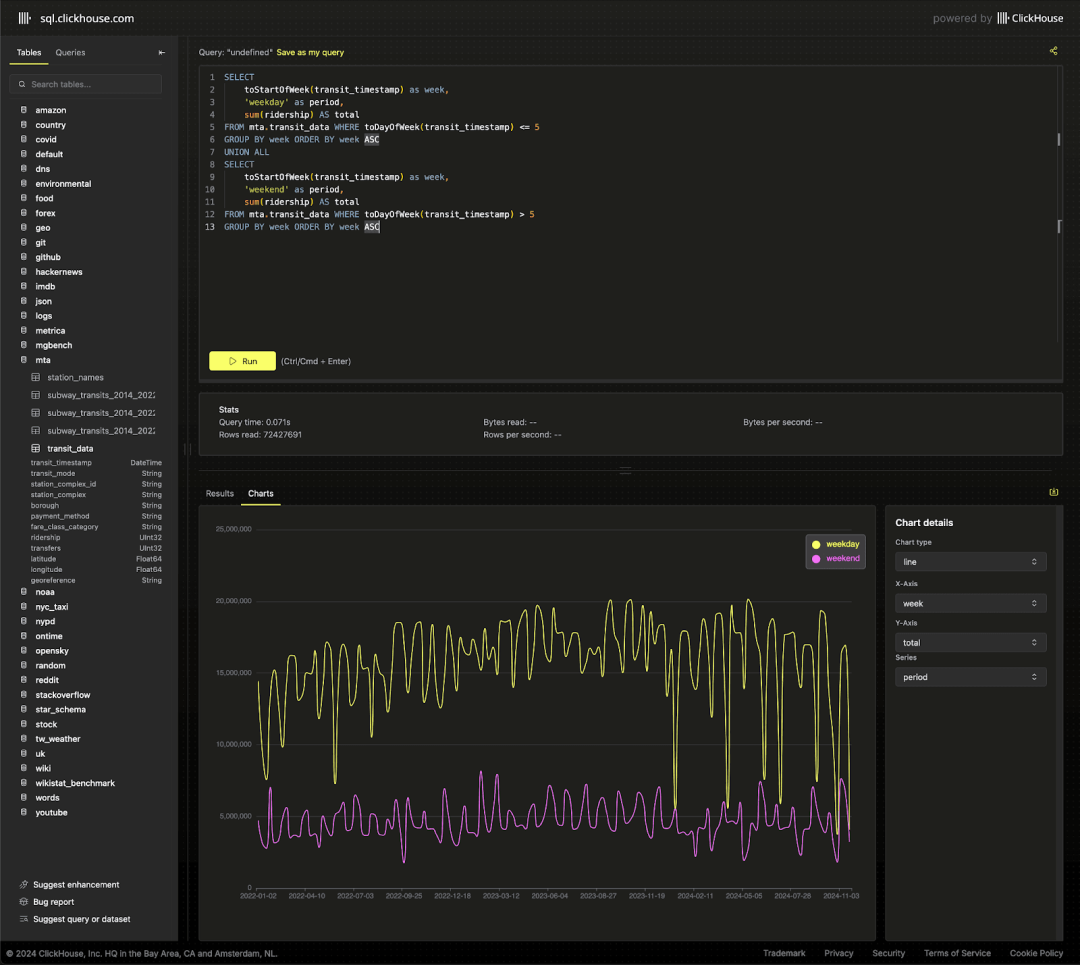
我们还可以轻松地对比周末和工作日的客流量,从而突出一年中的特定时段,例如 7 月 4 日,通勤流量明显减少。
SELECTtoStartOfWeek(transit_timestamp) AS week,'weekday' AS period,sum(ridership) AS totalFROM mta.transit_dataWHERE toDayOfWeek(transit_timestamp) <= 5GROUP BY weekORDER BY week ASCUNION ALLSELECTtoStartOfWeek(transit_timestamp) AS week,'weekend' AS period,sum(ridership) AS totalFROM mta.transit_dataWHERE toDayOfWeek(transit_timestamp) > 5GROUP BY weekORDER BY week ASC
我们在处理 MTA 数据时玩得很开心(尽量让数据清理过程更有趣!),希望我们的工作能帮助大家更轻松地进行有趣的数据分析。
如果您在示例库【https://github.com/ClickHouse/sql.clickhouse.com】中创建了新的查询或图表,欢迎与我们分享!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse架构全新升级,推出和原厂独家合作的ClickHouse企业版,在存储和计算成本上带来双重优势,现诚邀您参与100元指定规格测一个月的活动,了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


